Tree-Planted Transformers: Unidirectional Transformer Language Models with Implicit Syntactic Supervision

0

Sign in to get full access
Overview
- This paper presents "Tree-Planted Transformers," a novel approach to training large language models with implicit syntactic supervision.
- The key idea is to integrate tree-structured linguistic knowledge into the transformer architecture, allowing the model to learn syntactic structures without explicit supervision.
- The researchers demonstrate the benefits of this approach on a range of natural language tasks, showcasing its potential to improve the performance and interpretability of large language models.
Plain English Explanation
The paper explores a new way to train large language models, which are AI systems that can understand and generate human-like text. These models are typically trained on vast amounts of text data, but they don't always learn the underlying grammatical structure of language.
The researchers behind this paper have developed a technique called "Tree-Planted Transformers" that aims to address this issue. The core idea is to incorporate tree-like structures, which represent the syntax of language, directly into the model's architecture. This allows the model to implicitly learn these syntactic patterns as it's being trained, without the need for explicit labeling or annotation of the training data.
By embedding this syntactic knowledge into the model, the researchers show that it can perform better on a variety of language tasks, such as text generation, question answering, and natural language inference. Additionally, the tree-like structure makes the model's internal workings more interpretable, allowing us to better understand how it's processing and generating language.
This research is significant because it demonstrates a new way to build more powerful and insightful language models, which could have far-reaching applications in areas like natural language processing, conversational AI, and multimodal machine learning.
Technical Explanation
The researchers propose a new architecture called "Tree-Planted Transformers" that integrates tree-structured linguistic knowledge into the standard transformer model. This is achieved by adding a tree encoder module that processes the input text and generates a tree-like representation, which is then combined with the transformer's standard token-level encoding.
The key innovation is that this tree encoder is trained jointly with the overall language model, allowing the model to learn the syntactic structure of language in an implicit, data-driven way. This contrasts with previous approaches that required explicit annotation of the training data with syntactic parse trees.
Through extensive experiments on a range of natural language tasks, the researchers demonstrate the benefits of this tree-planted architecture. They show that it outperforms standard transformer models in terms of performance, while also providing greater interpretability and insight into the model's internal representations.
The authors also analyze the learned tree structures and find that they capture meaningful linguistic concepts, such as noun phrases, verb phrases, and sentence-level dependencies. This suggests that the model is able to discover and leverage syntactic knowledge without the need for explicit supervision.
Overall, this work presents a novel and promising direction for building more powerful and transparent large language models, with potential applications across natural language processing, multi-task learning, and beyond.
Critical Analysis
The Tree-Planted Transformer approach represents an exciting step forward in integrating syntactic knowledge into large language models. By learning tree structures in an implicit, data-driven way, the model can potentially capture more nuanced and contextual linguistic patterns than traditional rule-based parsing methods.
However, the paper does not fully address the question of how the learned tree structures compare to gold-standard syntactic annotations, or how they might differ across different domains or genres of text. It would be valuable to see more in-depth analysis and interpretation of the model's internal representations, to better understand the strengths and limitations of this approach.
Additionally, while the authors demonstrate the benefits of their approach on a range of tasks, it's unclear how the tree-planted architecture might scale to even larger language models or more challenging real-world applications. Further research is needed to explore the robustness and generalizability of this technique.
Finally, as with any data-driven approach, there are potential concerns around biases and fairness that should be carefully considered, particularly when deploying such models in high-stakes domains. The authors do not address these important ethical considerations in the current paper.
Conclusion
Overall, the Tree-Planted Transformer represents a promising step forward in the quest to build more powerful and interpretable large language models. By integrating tree-structured linguistic knowledge in an implicit, data-driven way, the researchers have demonstrated the potential to enhance model performance and provide greater insights into the inner workings of these complex systems.
As the field of natural language processing continues to evolve, approaches like this that combine structural, syntactic, and semantic understanding will likely play an increasingly important role. The researchers have opened up an intriguing new direction for further exploration and innovation, with applications across a wide range of language-based technologies and AI-powered systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tree-Planted Transformers: Unidirectional Transformer Language Models with Implicit Syntactic Supervision
Ryo Yoshida, Taiga Someya, Yohei Oseki
Syntactic Language Models (SLMs) can be trained efficiently to reach relatively high performance; however, they have trouble with inference efficiency due to the explicit generation of syntactic structures. In this paper, we propose a new method dubbed tree-planting: instead of explicitly generating syntactic structures, we plant trees into attention weights of unidirectional Transformer LMs to implicitly reflect syntactic structures of natural language. Specifically, unidirectional Transformer LMs trained with tree-planting will be called Tree-Planted Transformers (TPT), which inherit the training efficiency from SLMs without changing the inference efficiency of their underlying Transformer LMs. Targeted syntactic evaluations on the SyntaxGym benchmark demonstrated that TPTs, despite the lack of explicit generation of syntactic structures, significantly outperformed not only vanilla Transformer LMs but also various SLMs that generate hundreds of syntactic structures in parallel. This result suggests that TPTs can learn human-like syntactic knowledge as data-efficiently as SLMs while maintaining the modeling space of Transformer LMs unchanged.
Read more6/7/2024

0
Generative Pretrained Structured Transformers: Unsupervised Syntactic Language Models at Scale
Xiang Hu, Pengyu Ji, Qingyang Zhu, Wei Wu, Kewei Tu
A syntactic language model (SLM) incrementally generates a sentence with its syntactic tree in a left-to-right manner. We present Generative Pretrained Structured Transformers (GPST), an unsupervised SLM at scale capable of being pre-trained from scratch on raw texts with high parallelism. GPST circumvents the limitations of previous SLMs such as relying on gold trees and sequential training. It consists of two components, a usual SLM supervised by a uni-directional language modeling loss, and an additional composition model, which induces syntactic parse trees and computes constituent representations, supervised by a bi-directional language modeling loss. We propose a representation surrogate to enable joint parallel training of the two models in a hard-EM fashion. We pre-train GPST on OpenWebText, a corpus with $9$ billion tokens, and demonstrate the superiority of GPST over GPT-2 with a comparable size in numerous tasks covering both language understanding and language generation. Meanwhile, GPST also significantly outperforms existing unsupervised SLMs on left-to-right grammar induction, while holding a substantial acceleration on training.
Read more6/18/2024
🤔
0
Learning Syntax Without Planting Trees: Understanding When and Why Transformers Generalize Hierarchically
Kabir Ahuja, Vidhisha Balachandran, Madhur Panwar, Tianxing He, Noah A. Smith, Navin Goyal, Yulia Tsvetkov
Transformers trained on natural language data have been shown to learn its hierarchical structure and generalize to sentences with unseen syntactic structures without explicitly encoding any structural bias. In this work, we investigate sources of inductive bias in transformer models and their training that could cause such generalization behavior to emerge. We extensively experiment with transformer models trained on multiple synthetic datasets and with different training objectives and show that while other objectives e.g. sequence-to-sequence modeling, prefix language modeling, often failed to lead to hierarchical generalization, models trained with the language modeling objective consistently learned to generalize hierarchically. We then conduct pruning experiments to study how transformers trained with the language modeling objective encode hierarchical structure. When pruned, we find joint existence of subnetworks within the model with different generalization behaviors (subnetworks corresponding to hierarchical structure and linear order). Finally, we take a Bayesian perspective to further uncover transformers' preference for hierarchical generalization: We establish a correlation between whether transformers generalize hierarchically on a dataset and whether the simplest explanation of that dataset is provided by a hierarchical grammar compared to regular grammars exhibiting linear generalization.
Read more6/4/2024
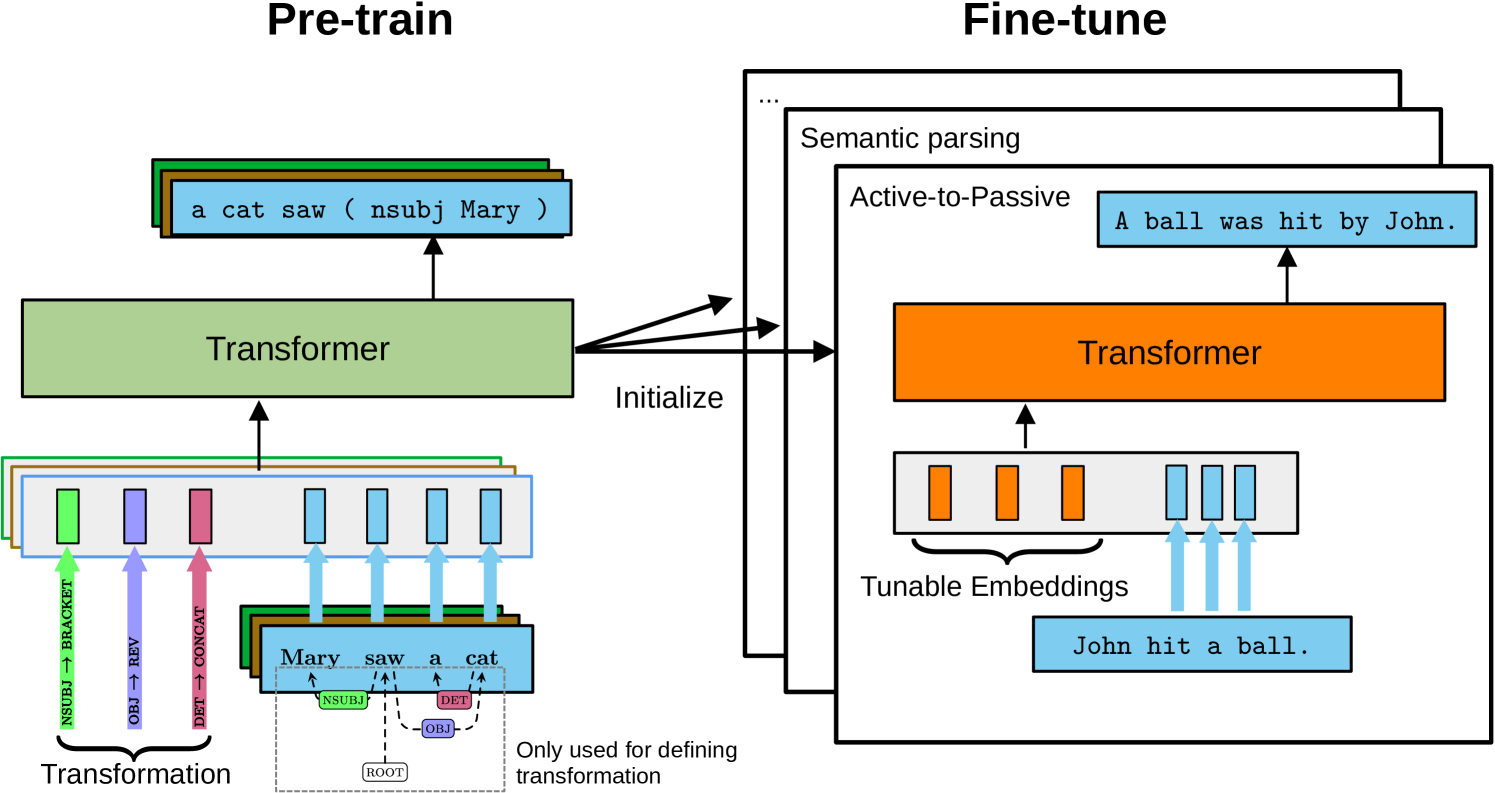
0
Strengthening Structural Inductive Biases by Pre-training to Perform Syntactic Transformations
Matthias Lindemann, Alexander Koller, Ivan Titov
Models need appropriate inductive biases to effectively learn from small amounts of data and generalize systematically outside of the training distribution. While Transformers are highly versatile and powerful, they can still benefit from enhanced structural inductive biases for seq2seq tasks, especially those involving syntactic transformations, such as converting active to passive voice or semantic parsing. In this paper, we propose to strengthen the structural inductive bias of a Transformer by intermediate pre-training to perform synthetically generated syntactic transformations of dependency trees given a description of the transformation. Our experiments confirm that this helps with few-shot learning of syntactic tasks such as chunking, and also improves structural generalization for semantic parsing. Our analysis shows that the intermediate pre-training leads to attention heads that keep track of which syntactic transformation needs to be applied to which token, and that the model can leverage these attention heads on downstream tasks.
Read more7/8/2024