Strengthening Structural Inductive Biases by Pre-training to Perform Syntactic Transformations

0
Sign in to get full access
Overview
- This research paper explores how pre-training transformers to perform syntactic transformations can strengthen their structural inductive biases.
- The key contributions are:
- Designing a novel pre-training task that encourages transformers to learn syntactic transformations.
- Showing this pre-training approach leads to stronger performance on downstream tasks that require structured reasoning.
Plain English Explanation
The paper looks at how to make transformer models better at understanding the structure and syntax of language. Transformers are a type of neural network that have become very powerful for language tasks, but they can struggle to grasp the underlying grammatical structure of sentences.
To address this, the researchers developed a new pre-training technique. Rather than just training transformers on raw text, they also had the models practice transforming sentences in specific ways, like changing the voice from active to passive. This helps the transformers learn about syntax and the logical relationships between the parts of a sentence.
The intuition is that by gaining this deeper understanding of language structure, the transformers will perform better on downstream tasks that require reasoning about things like logical entailment or textual attribute inference. The results show this pre-training approach does lead to stronger performance on these types of tasks compared to standard pre-training.
Technical Explanation
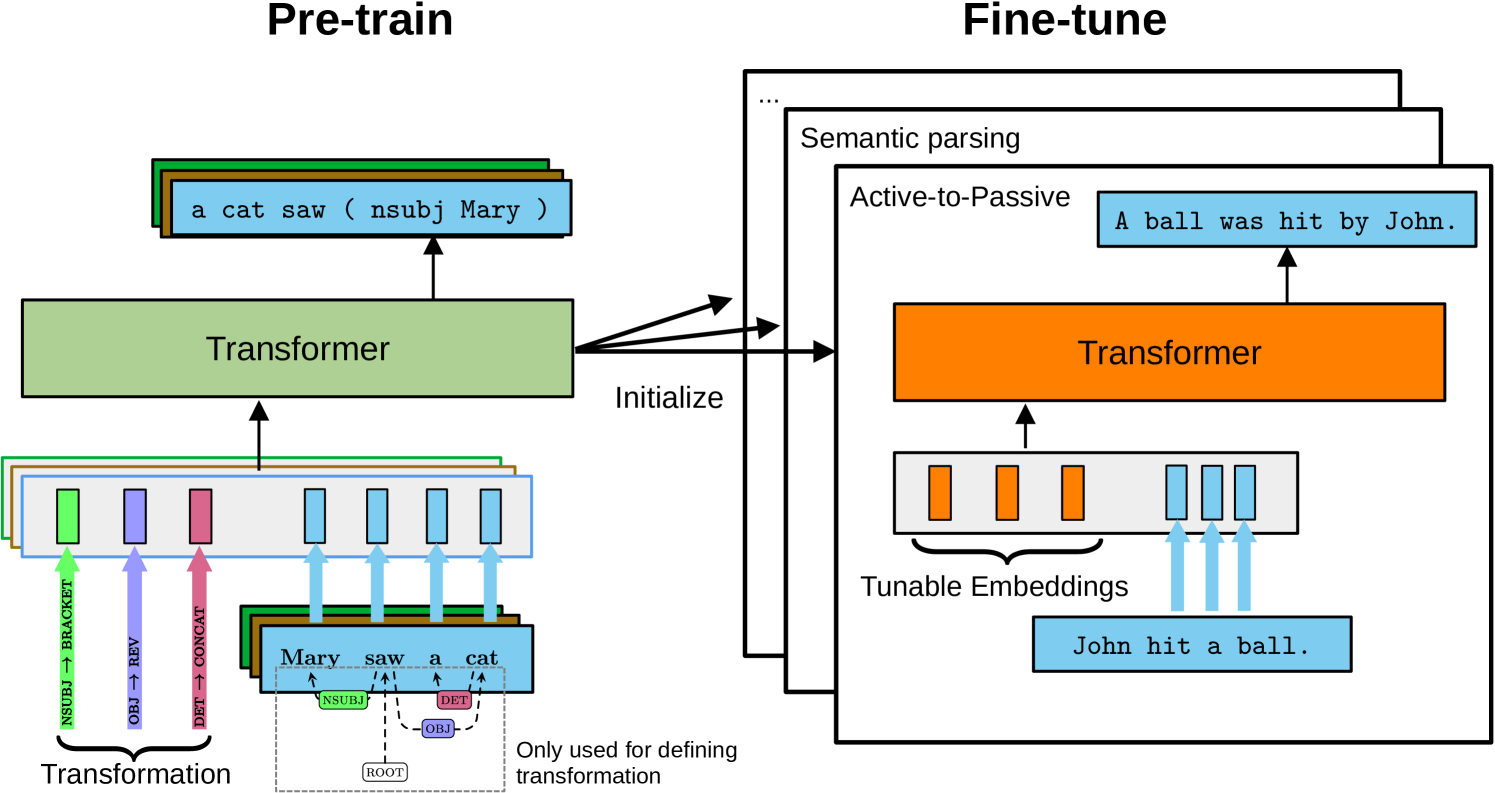
The key innovation in this work is a novel pre-training task called Syntactic Transformation (SynT), where the model must learn to transform sentences in specific ways, like changing the voice or negating a clause. This forces the model to engage with the underlying syntactic structure of the input text.
The SynT pre-training is done in addition to standard language modeling on raw text. The researchers then evaluate the pre-trained models on a suite of downstream tasks that require structured reasoning, such as natural language inference and semantic role labeling.
The results show that the SynT pre-training leads to significant performance gains on these tasks compared to standard pre-training approaches. The authors hypothesize that this is because the SynT objective helps the model build stronger structural inductive biases - an innate understanding of the logical relationships between the components of language.
Critical Analysis
The authors provide a thorough evaluation of their approach, testing it on a range of datasets and tasks that require different types of structured reasoning. This helps demonstrate the generality of their findings.
However, one limitation is that the experiments are primarily focused on English language tasks. It would be valuable to see if the benefits of SynT pre-training hold up for other languages with different grammatical structures.
Additionally, the paper does not deeply analyze the internal representations and behaviors of the models pre-trained with SynT. A more detailed mechanistic understanding of how this approach shapes the model's inductive biases could provide additional insights.
Overall, this work makes a compelling case that explicitly training transformers to perform syntactic transformations is an effective way to improve their ability to reason about language structure.
Conclusion
This paper presents a novel pre-training approach that helps transformer models build stronger structural inductive biases. By training the models to perform specific syntactic transformations, the researchers were able to achieve significant performance gains on downstream tasks requiring logical and grammatical reasoning.
These findings suggest that incorporating more explicit knowledge about language structure during pre-training can be a powerful way to enhance the capabilities of transformer-based models. This could have important implications for developing NLP systems that can better understand and reason about the semantic and pragmatic aspects of human language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Strengthening Structural Inductive Biases by Pre-training to Perform Syntactic Transformations
Matthias Lindemann, Alexander Koller, Ivan Titov
Models need appropriate inductive biases to effectively learn from small amounts of data and generalize systematically outside of the training distribution. While Transformers are highly versatile and powerful, they can still benefit from enhanced structural inductive biases for seq2seq tasks, especially those involving syntactic transformations, such as converting active to passive voice or semantic parsing. In this paper, we propose to strengthen the structural inductive bias of a Transformer by intermediate pre-training to perform synthetically generated syntactic transformations of dependency trees given a description of the transformation. Our experiments confirm that this helps with few-shot learning of syntactic tasks such as chunking, and also improves structural generalization for semantic parsing. Our analysis shows that the intermediate pre-training leads to attention heads that keep track of which syntactic transformation needs to be applied to which token, and that the model can leverage these attention heads on downstream tasks.
Read more7/8/2024

0
SIP: Injecting a Structural Inductive Bias into a Seq2Seq Model by Simulation
Matthias Lindemann, Alexander Koller, Ivan Titov
Strong inductive biases enable learning from little data and help generalization outside of the training distribution. Popular neural architectures such as Transformers lack strong structural inductive biases for seq2seq NLP tasks on their own. Consequently, they struggle with systematic generalization beyond the training distribution, e.g. with extrapolating to longer inputs, even when pre-trained on large amounts of text. We show how a structural inductive bias can be efficiently injected into a seq2seq model by pre-training it to simulate structural transformations on synthetic data. Specifically, we inject an inductive bias towards Finite State Transducers (FSTs) into a Transformer by pre-training it to simulate FSTs given their descriptions. Our experiments show that our method imparts the desired inductive bias, resulting in improved systematic generalization and better few-shot learning for FST-like tasks. Our analysis shows that fine-tuned models accurately capture the state dynamics of the unseen underlying FSTs, suggesting that the simulation process is internalized by the fine-tuned model.
Read more7/11/2024
🤔
0
Learning Syntax Without Planting Trees: Understanding When and Why Transformers Generalize Hierarchically
Kabir Ahuja, Vidhisha Balachandran, Madhur Panwar, Tianxing He, Noah A. Smith, Navin Goyal, Yulia Tsvetkov
Transformers trained on natural language data have been shown to learn its hierarchical structure and generalize to sentences with unseen syntactic structures without explicitly encoding any structural bias. In this work, we investigate sources of inductive bias in transformer models and their training that could cause such generalization behavior to emerge. We extensively experiment with transformer models trained on multiple synthetic datasets and with different training objectives and show that while other objectives e.g. sequence-to-sequence modeling, prefix language modeling, often failed to lead to hierarchical generalization, models trained with the language modeling objective consistently learned to generalize hierarchically. We then conduct pruning experiments to study how transformers trained with the language modeling objective encode hierarchical structure. When pruned, we find joint existence of subnetworks within the model with different generalization behaviors (subnetworks corresponding to hierarchical structure and linear order). Finally, we take a Bayesian perspective to further uncover transformers' preference for hierarchical generalization: We establish a correlation between whether transformers generalize hierarchically on a dataset and whether the simplest explanation of that dataset is provided by a hierarchical grammar compared to regular grammars exhibiting linear generalization.
Read more6/4/2024
📈
0
Downstream bias mitigation is all you need
Arkadeep Baksi, Rahul Singh, Tarun Joshi
The advent of transformer-based architectures and large language models (LLMs) have significantly advanced the performance of natural language processing (NLP) models. Since these LLMs are trained on huge corpuses of data from the web and other sources, there has been a major concern about harmful prejudices that may potentially be transferred from the data. In many applications, these pre-trained LLMs are fine-tuned on task specific datasets, which can further contribute to biases. This paper studies the extent of biases absorbed by LLMs during pre-training as well as task-specific behaviour after fine-tuning. We found that controlled interventions on pre-trained LLMs, prior to fine-tuning, have minimal effect on lowering biases in classifiers. However, the biases present in domain-specific datasets play a much bigger role, and hence mitigating them at this stage has a bigger impact. While pre-training does matter, but after the model has been pre-trained, even slight changes to co-occurrence rates in the fine-tuning dataset has a significant effect on the bias of the model.
Read more8/29/2024