Tree-Sliced Wasserstein Distance on a System of Lines

0
Sign in to get full access
Overview
- Introduces a new distance metric called Stereographic Spherical Sliced Wasserstein (S3W) distance
- Proposes a hierarchical hybrid approach combining S3W and other Wasserstein-based distances for scalable and heterogeneous data
- Analyzes the theoretical properties of discrete sliced Wasserstein losses
- Introduces a novel Wasserstein Wormhole distance for transformers that can efficiently compute optimal transport distances
Plain English Explanation
The paper presents several new techniques for measuring the similarity between different data distributions, which is an important problem in machine learning.
The first key idea is the Stereographic Spherical Sliced Wasserstein (S3W) distance. This is a new way to calculate the distance between probability distributions that the authors claim has advantages over previous methods. They show how S3W can be used for a variety of machine learning tasks.
Next, the paper introduces a hierarchical hybrid approach that combines S3W with other Wasserstein-based distances. This allows the method to handle large and complex datasets more efficiently.
The paper also analyzes the theoretical properties of a related concept called discrete sliced Wasserstein losses, providing a deeper mathematical understanding of these techniques.
Finally, the authors propose a novel distance metric called Wasserstein Wormhole that can efficiently compute optimal transport distances for transformers, a popular type of deep learning model.
Overall, this work introduces several innovative techniques for comparing and working with different types of data distributions, which have important applications in machine learning and beyond.
Technical Explanation
The paper first introduces the Stereographic Spherical Sliced Wasserstein (S3W) distance. This is a new way to calculate the distance between probability distributions that generalizes previous sliced Wasserstein approaches. S3W maps data onto a sphere and then computes the distance between the resulting spherical distributions. The authors show that S3W has several desirable theoretical properties and can be efficiently computed.
Next, the paper proposes a hierarchical hybrid approach that combines S3W with other Wasserstein-based distances. This hybrid method can handle large and complex datasets by adaptively choosing the most appropriate distance metric for different parts of the data. Experiments demonstrate the scalability and effectiveness of this approach on various machine learning tasks.
The paper also provides a theoretical analysis of discrete sliced Wasserstein losses. The authors derive new results on the convergence and approximation properties of these losses, shedding light on their mathematical structure and behavior.
Finally, the authors introduce the Wasserstein Wormhole distance, a novel approach for efficiently computing optimal transport distances in the context of transformers. This technique leverages the self-attention mechanism of transformers to enable scalable and accurate optimal transport computations.
Critical Analysis
The paper presents several innovative techniques for working with probability distributions, which is an important and challenging problem in machine learning. The authors have done a thorough job of analyzing the theoretical properties of their proposed methods and demonstrating their effectiveness on a range of tasks.
One potential limitation is that the S3W distance and hierarchical hybrid approach may be more computationally expensive than some simpler distance metrics, especially for very large datasets. The authors acknowledge this and propose the Wasserstein Wormhole as a way to address the scalability challenge, but further research may be needed to fully optimize the efficiency of these techniques.
Additionally, while the theoretical analysis of discrete sliced Wasserstein losses is valuable, the practical implications of these results could be explored in more depth. It would be helpful to see how the insights from this analysis translate to improved performance on real-world machine learning problems.
Overall, this paper makes significant contributions to the field of optimal transport and probability distribution comparison, providing both new methodological advances and a deeper mathematical understanding of related concepts. The ideas presented here have the potential to enable more powerful and flexible machine learning systems, and the work serves as a strong foundation for further research in this area.
Conclusion
This paper introduces several novel techniques for measuring the similarity between probability distributions, a fundamental problem in machine learning. The key contributions include the Stereographic Spherical Sliced Wasserstein (S3W) distance, a hierarchical hybrid approach that combines different Wasserstein-based metrics, a theoretical analysis of discrete sliced Wasserstein losses, and the novel Wasserstein Wormhole distance for transformers.
These innovations have significant implications for a wide range of machine learning applications, from generative modeling to domain adaptation and beyond. While the techniques presented may have some computational challenges, the authors have made important strides in advancing the state-of-the-art in this crucial area of research. Overall, this work lays the groundwork for more powerful, flexible, and scalable methods for working with complex data distributions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
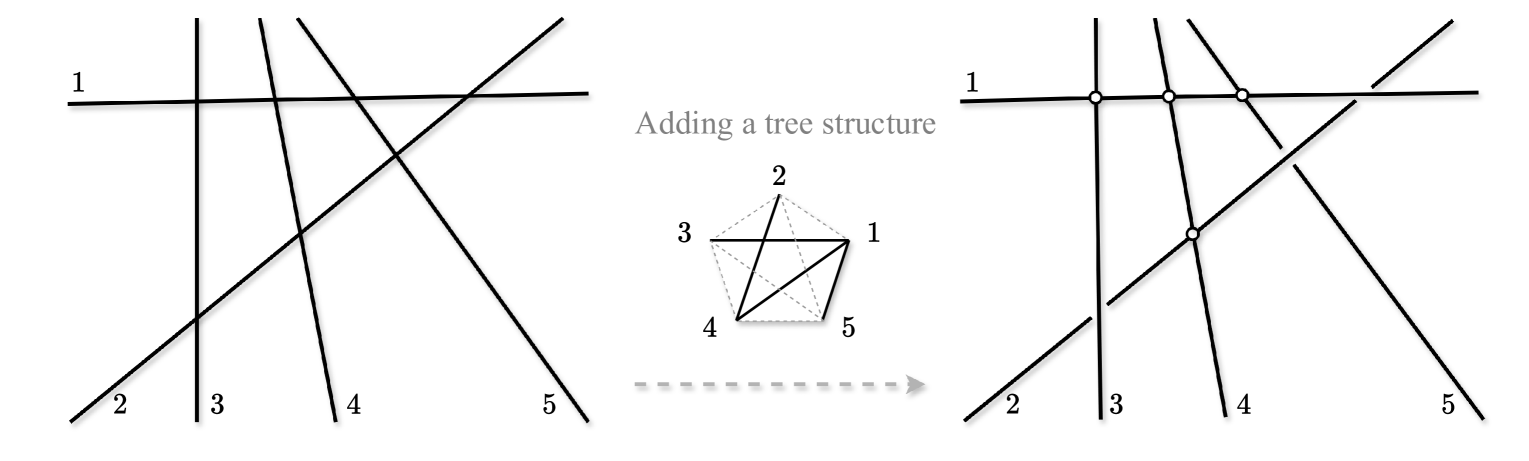
Tree-Sliced Wasserstein Distance on a System of Lines
Viet-Hoang Tran, Trang Pham, Tho Tran, Tam Le, Tan M. Nguyen
Sliced Wasserstein (SW) distance in Optimal Transport (OT) is widely used in various applications thanks to its statistical effectiveness and computational efficiency. On the other hand, Tree Wassenstein (TW) and Tree-sliced Wassenstein (TSW) are instances of OT for probability measures where its ground cost is a tree metric. TSW also has a low computational complexity, i.e. linear to the number of edges in the tree. Especially, TSW is identical to SW when the tree is a chain. While SW is prone to loss of topological information of input measures due to relying on one-dimensional projection, TSW is more flexible and has a higher degree of freedom by choosing a tree rather than a line to alleviate the curse of dimensionality in SW. However, for practical applications, popular tree metric sampling methods are heavily built upon given supports, which limits their capacity to adapt to new supports. In this paper, we propose the Tree-Sliced Wasserstein distance on a System of Lines (TSW-SL), which brings a connection between SW and TSW. Compared to SW and TSW, our TSW-SL benefits from the higher degree of freedom of TSW while being suitable to dynamic settings as SW. In TSW-SL, we use a variant of the Radon Transform to project measures onto a system of lines, resulting in measures on a space with a tree metric, then leverage TW to efficiently compute distances between them. We empirically verify the advantages of TSW-SL over the traditional SW by conducting a variety of experiments on gradient flows, image style transfer, and generative models.
Read more6/21/2024
🛠️
0
Stereographic Spherical Sliced Wasserstein Distances
Huy Tran, Yikun Bai, Abihith Kothapalli, Ashkan Shahbazi, Xinran Liu, Rocio Diaz Martin, Soheil Kolouri
Comparing spherical probability distributions is of great interest in various fields, including geology, medical domains, computer vision, and deep representation learning. The utility of optimal transport-based distances, such as the Wasserstein distance, for comparing probability measures has spurred active research in developing computationally efficient variations of these distances for spherical probability measures. This paper introduces a high-speed and highly parallelizable distance for comparing spherical measures using the stereographic projection and the generalized Radon transform, which we refer to as the Stereographic Spherical Sliced Wasserstein (S3W) distance. We carefully address the distance distortion caused by the stereographic projection and provide an extensive theoretical analysis of our proposed metric and its rotationally invariant variation. Finally, we evaluate the performance of the proposed metrics and compare them with recent baselines in terms of both speed and accuracy through a wide range of numerical studies, including gradient flows and self-supervised learning. Our code is available at https://github.com/mint-vu/s3wd.
Read more6/11/2024

0
Hierarchical Hybrid Sliced Wasserstein: A Scalable Metric for Heterogeneous Joint Distributions
Khai Nguyen, Nhat Ho
Sliced Wasserstein (SW) and Generalized Sliced Wasserstein (GSW) have been widely used in applications due to their computational and statistical scalability. However, the SW and the GSW are only defined between distributions supported on a homogeneous domain. This limitation prevents their usage in applications with heterogeneous joint distributions with marginal distributions supported on multiple different domains. Using SW and GSW directly on the joint domains cannot make a meaningful comparison since their homogeneous slicing operator i.e., Radon Transform (RT) and Generalized Radon Transform (GRT) are not expressive enough to capture the structure of the joint supports set. To address the issue, we propose two new slicing operators i.e., Partial Generalized Radon Transform (PGRT) and Hierarchical Hybrid Radon Transform (HHRT). In greater detail, PGRT is the generalization of Partial Radon Transform (PRT), which transforms a subset of function arguments non-linearly while HHRT is the composition of PRT and multiple domain-specific PGRT on marginal domain arguments. By using HHRT, we extend the SW into Hierarchical Hybrid Sliced Wasserstein (H2SW) distance which is designed specifically for comparing heterogeneous joint distributions. We then discuss the topological, statistical, and computational properties of H2SW. Finally, we demonstrate the favorable performance of H2SW in 3D mesh deformation, deep 3D mesh autoencoders, and datasets comparison.
Read more5/2/2024
🌐
0
Properties of Discrete Sliced Wasserstein Losses
Eloi Tanguy, R'emi Flamary, Julie Delon
The Sliced Wasserstein (SW) distance has become a popular alternative to the Wasserstein distance for comparing probability measures. Widespread applications include image processing, domain adaptation and generative modelling, where it is common to optimise some parameters in order to minimise SW, which serves as a loss function between discrete probability measures (since measures admitting densities are numerically unattainable). All these optimisation problems bear the same sub-problem, which is minimising the Sliced Wasserstein energy. In this paper we study the properties of $mathcal{E}: Y longmapsto mathrm{SW}_2^2(gamma_Y, gamma_Z)$, i.e. the SW distance between two uniform discrete measures with the same amount of points as a function of the support $Y in mathbb{R}^{n times d}$ of one of the measures. We investigate the regularity and optimisation properties of this energy, as well as its Monte-Carlo approximation $mathcal{E}_p$ (estimating the expectation in SW using only $p$ samples) and show convergence results on the critical points of $mathcal{E}_p$ to those of $mathcal{E}$, as well as an almost-sure uniform convergence and a uniform Central Limit result on the process $mathcal{E}_p(Y)$. Finally, we show that in a certain sense, Stochastic Gradient Descent methods minimising $mathcal{E}$ and $mathcal{E}_p$ converge towards (Clarke) critical points of these energies.
Read more5/14/2024