TREE: Tree Regularization for Efficient Execution
2406.12531
0
0
Abstract
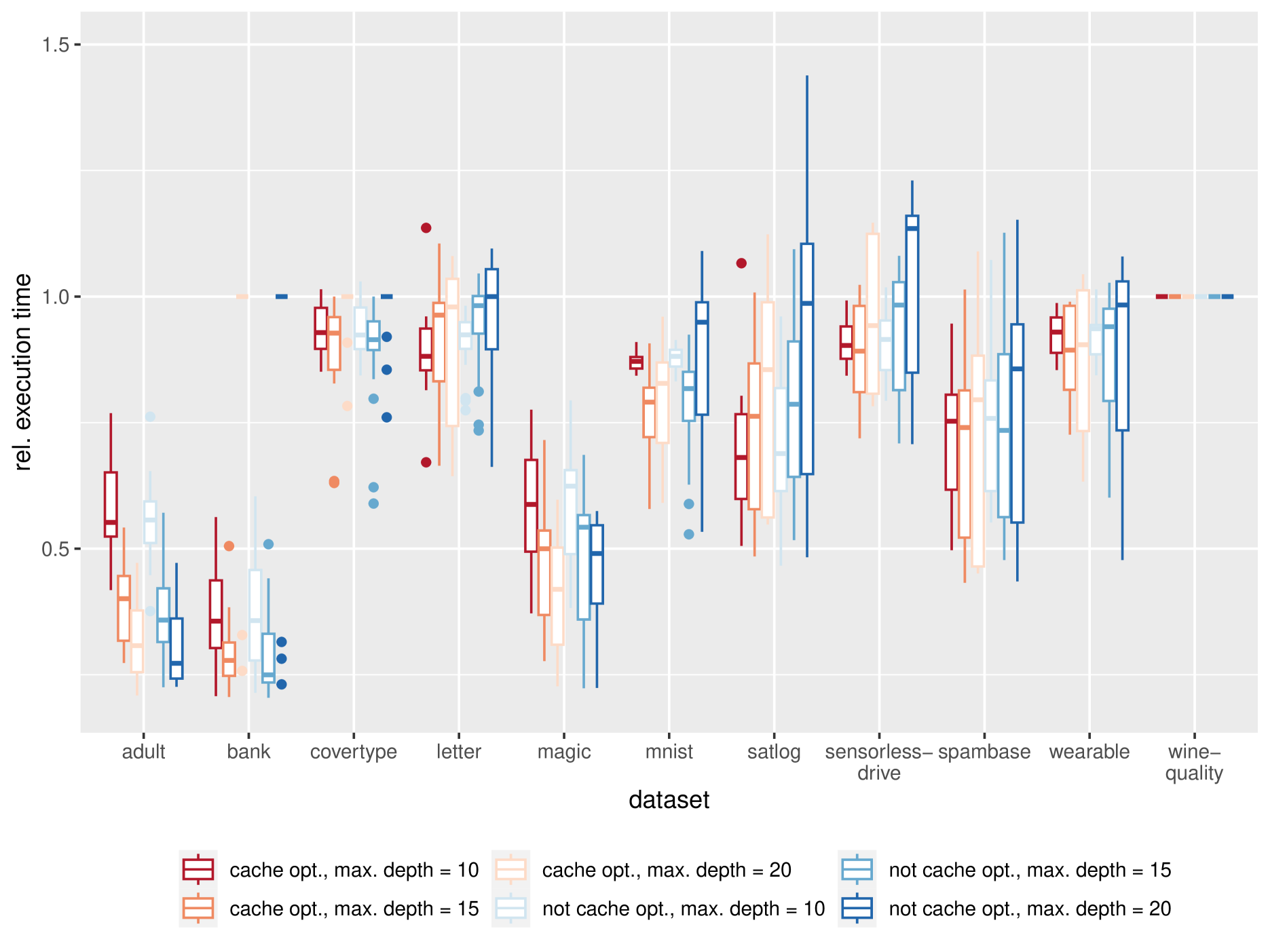
The rise of machine learning methods on heavily resource constrained devices requires not only the choice of a suitable model architecture for the target platform, but also the optimization of the chosen model with regard to execution time consumption for inference in order to optimally utilize the available resources. Random forests and decision trees are shown to be a suitable model for such a scenario, since they are not only heavily tunable towards the total model size, but also offer a high potential for optimizing their executions according to the underlying memory architecture. In addition to the straightforward strategy of enforcing shorter paths through decision trees and hence reducing the execution time for inference, hardware-aware implementations can optimize the execution time in an orthogonal manner. One particular hardware-aware optimization is to layout the memory of decision trees in such a way, that higher probably paths are less likely to be evicted from system caches. This works particularly well when splits within tree nodes are uneven and have a high probability to visit one of the child nodes. In this paper, we present a method to reduce path lengths by rewarding uneven probability distributions during the training of decision trees at the cost of a minimal accuracy degradation. Specifically, we regularize the impurity computation of the CART algorithm in order to favor not only low impurity, but also highly asymmetric distributions for the evaluation of split criteria and hence offer a high optimization potential for a memory architecture-aware implementation. We show that especially for binary classification data sets and data sets with many samples, this form of regularization can lead to an reduction of up to approximately four times in the execution time with a minimal accuracy degradation.
Create account to get full access
Overview
- This paper proposes a new technique called "tree regularization" for optimizing decision tree ensemble models.
- The key idea is to incorporate structural constraints on the decision trees during the training process to encourage the model to learn a more interpretable and accurate set of trees.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improvements in interpretability and performance compared to standard ensemble methods.
Plain English Explanation
The paper introduces a new way to train decision tree ensemble models, which are a popular type of machine learning model used for tasks like classification and prediction. Decision tree ensembles work by combining the predictions of multiple individual decision trees to make more accurate and robust predictions.
The authors' key insight is that by adding specific "regularization" constraints to the training process, they can encourage the decision trees to have a more interpretable structure. This means the resulting trees are simpler and easier for humans to understand, without sacrificing too much predictive accuracy.
The main idea behind their "tree regularization" approach is to penalize the model if the individual trees become too complex or diverge too much from a desired structural template. This encourages the model to learn a set of trees that are well-aligned with each other and have a clean, interpretable form.
The authors demonstrate that their tree regularization technique leads to more interpretable and accurate decision tree ensembles compared to standard training methods, across a variety of benchmark datasets. This suggests the approach could be a valuable tool for building AI models that are both high-performing and transparent to human users.
Technical Explanation
The paper proposes a new technique called "tree regularization" for training decision tree ensemble models. The key idea is to incorporate structural constraints on the decision trees during the training process to encourage the model to learn a more interpretable and accurate set of trees.
Specifically, the authors define a "tree regularization" penalty term that is added to the overall training objective. This penalty term encourages the individual trees in the ensemble to have a similar structural form, such as limiting the maximum depth or number of leaves. The authors also experiment with techniques like penalizing trees that deviate from a "reference" tree structure.
The authors evaluate their tree regularization approach on several benchmark datasets for classification and regression tasks. They show that the resulting decision tree ensembles achieve improved interpretability, as measured by metrics like average tree depth and number of leaves, without sacrificing too much predictive performance compared to standard ensemble training.
The paper also includes ablation studies and analyses to better understand the impact of the different tree regularization terms and hyperparameters. Overall, the results suggest that incorporating structural constraints during training can be an effective way to learn more interpretable and accurate decision tree ensemble models.
Critical Analysis
The paper presents a well-designed and thorough study of the proposed tree regularization approach for decision tree ensembles. The authors carefully evaluate their method on multiple benchmark datasets and provide compelling empirical evidence for its benefits in terms of interpretability and performance.
That said, the paper does not extensively discuss potential limitations or caveats of the technique. For example, it's unclear how the approach would scale to very large datasets or high-dimensional feature spaces, where the complexity of the underlying decision boundaries may require more expressive (and less interpretable) tree structures.
Additionally, the paper focuses on generic performance metrics like accuracy and interpretability, but does not consider application-specific factors that may be important in real-world use cases. For instance, in sensitive domains like healthcare or finance, the interpretability of the model may need to be weighed against other considerations like robustness to distribution shift or the ability to provide reliable uncertainty estimates.
Overall, the tree regularization approach seems promising, but further research would be needed to fully understand its strengths, weaknesses, and appropriate scope of application. Incorporating feedback from domain experts and end-users could also help ensure the technique addresses the most relevant challenges in interpretable machine learning.
Conclusion
This paper introduces a new "tree regularization" technique for training decision tree ensemble models that are both interpretable and accurate. The key idea is to incorporate structural constraints on the individual trees during the training process, encouraging the model to learn a set of trees that are well-aligned and have a clean, easy-to-understand form.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improvements in interpretability metrics like average tree depth and number of leaves, without sacrificing too much predictive performance compared to standard ensemble training methods.
The tree regularization technique represents a valuable contribution to the field of interpretable machine learning, providing a principled way to balance model accuracy and transparency. As AI systems become more prominent in high-stakes domains, approaches like this that prioritize both performance and interpretability will likely become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Register Your Forests: Decision Tree Ensemble Optimization by Explicit CPU Register Allocation
Daniel Biebert, Christian Hakert, Kuan-Hsun Chen, Jian-Jia Chen
0
0
Bringing high-level machine learning models to efficient and well-suited machine implementations often invokes a bunch of tools, e.g.~code generators, compilers, and optimizers. Along such tool chains, abstractions have to be applied. This leads to not optimally used CPU registers. This is a shortcoming, especially in resource constrained embedded setups. In this work, we present a code generation approach for decision tree ensembles, which produces machine assembly code within a single conversion step directly from the high-level model representation. Specifically, we develop various approaches to effectively allocate registers for the inference of decision tree ensembles. Extensive evaluations of the proposed method are conducted in comparison to the basic realization of C code from the high-level machine learning model and succeeding compilation. The results show that the performance of decision tree ensemble inference can be significantly improved (by up to $approx1.6times$), if the methods are applied carefully to the appropriate scenario.
4/11/2024
📊
Data Selection: A General Principle for Building Small Interpretable Models
Abhishek Ghose
0
0
We present convincing empirical evidence for an effective and general strategy for building accurate small models. Such models are attractive for interpretability and also find use in resource-constrained environments. The strategy is to learn the training distribution and sample accordingly from the provided training data. The distribution learning algorithm is not a contribution of this work; our contribution is a rigorous demonstration of the broad utility of this strategy in various practical settings. We apply it to the tasks of (1) building cluster explanation trees, (2) prototype-based classification, and (3) classification using Random Forests, and show that it improves the accuracy of decades-old weak traditional baselines to be competitive with specialized modern techniques. This strategy is also versatile wrt the notion of model size. In the first two tasks, model size is considered to be number of leaves in the tree and the number of prototypes respectively. In the final task involving Random Forests, the strategy is shown to be effective even when model size comprises of more than one factor: number of trees and their maximum depth. Positive results using multiple datasets are presented that are shown to be statistically significant.
4/30/2024

Learning accurate and interpretable decision trees
Maria-Florina Balcan, Dravyansh Sharma
0
0
Decision trees are a popular tool in machine learning and yield easy-to-understand models. Several techniques have been proposed in the literature for learning a decision tree classifier, with different techniques working well for data from different domains. In this work, we develop approaches to design decision tree learning algorithms given repeated access to data from the same domain. We propose novel parameterized classes of node splitting criteria in top-down algorithms, which interpolate between popularly used entropy and Gini impurity based criteria, and provide theoretical bounds on the number of samples needed to learn the splitting function appropriate for the data at hand. We also study the sample complexity of tuning prior parameters in Bayesian decision tree learning, and extend our results to decision tree regression. We further consider the problem of tuning hyperparameters in pruning the decision tree for classical pruning algorithms including min-cost complexity pruning. We also study the interpretability of the learned decision trees and introduce a data-driven approach for optimizing the explainability versus accuracy trade-off using decision trees. Finally, we demonstrate the significance of our approach on real world datasets by learning data-specific decision trees which are simultaneously more accurate and interpretable.
5/28/2024
↗️
Ensembles of Probabilistic Regression Trees
Alexandre Seiller (APTIKAL), 'Eric Gaussier (APTIKAL), Emilie Devijver (APTIKAL), Marianne Clausel (IECL), Sami Alkhoury
0
0
Tree-based ensemble methods such as random forests, gradient-boosted trees, and Bayesianadditive regression trees have been successfully used for regression problems in many applicationsand research studies. In this paper, we study ensemble versions of probabilisticregression trees that provide smooth approximations of the objective function by assigningeach observation to each region with respect to a probability distribution. We prove thatthe ensemble versions of probabilistic regression trees considered are consistent, and experimentallystudy their bias-variance trade-off and compare them with the state-of-the-art interms of performance prediction.
6/21/2024