Tri-modal Confluence with Temporal Dynamics for Scene Graph Generation in Operating Rooms
2404.09231
0
0
Abstract
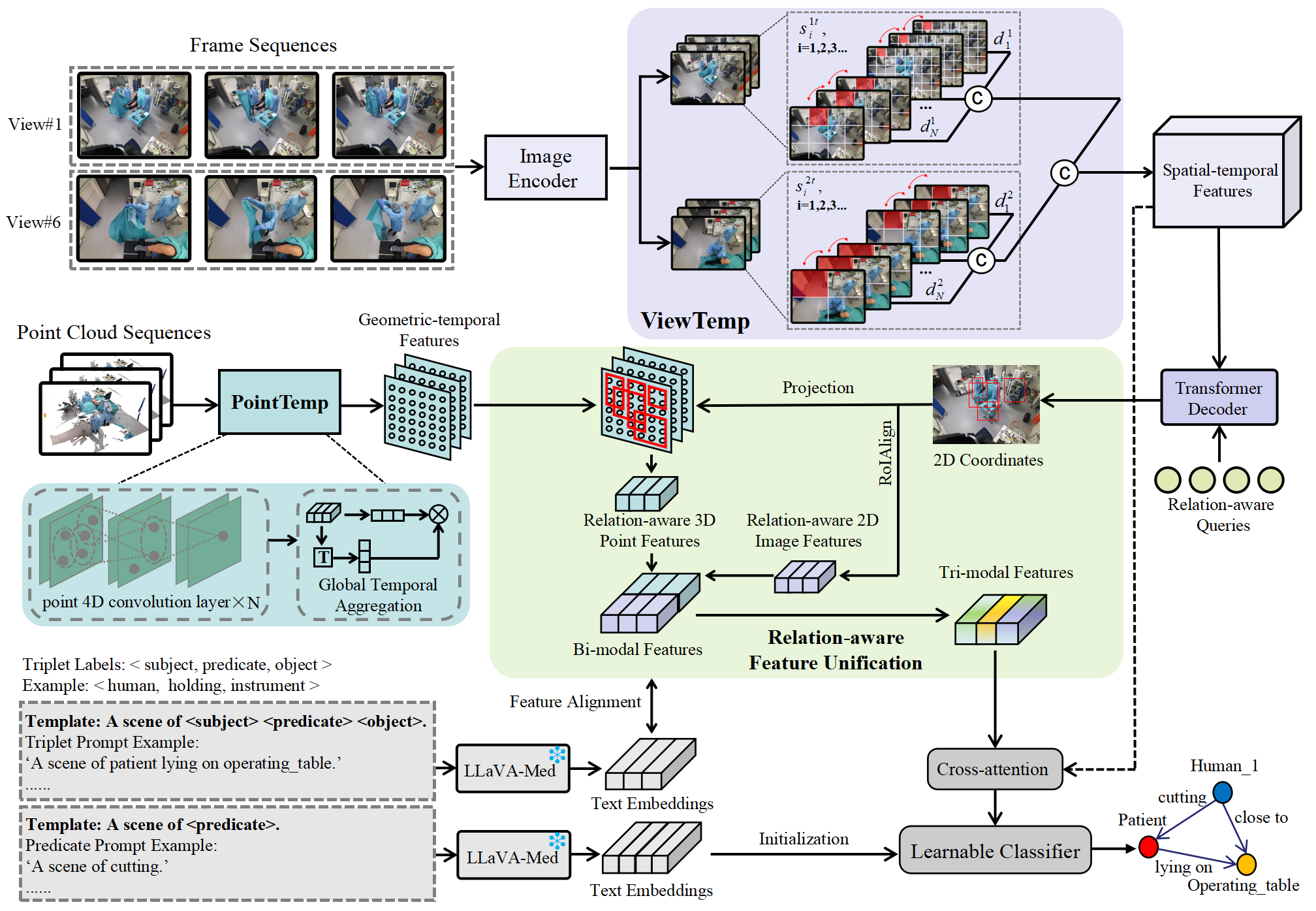
A comprehensive understanding of surgical scenes allows for monitoring of the surgical process, reducing the occurrence of accidents and enhancing efficiency for medical professionals. Semantic modeling within operating rooms, as a scene graph generation (SGG) task, is challenging since it involves consecutive recognition of subtle surgical actions over prolonged periods. To address this challenge, we propose a Tri-modal (i.e., images, point clouds, and language) confluence with Temporal dynamics framework, termed TriTemp-OR. Diverging from previous approaches that integrated temporal information via memory graphs, our method embraces two advantages: 1) we directly exploit bi-modal temporal information from the video streaming for hierarchical feature interaction, and 2) the prior knowledge from Large Language Models (LLMs) is embedded to alleviate the class-imbalance problem in the operating theatre. Specifically, our model performs temporal interactions across 2D frames and 3D point clouds, including a scale-adaptive multi-view temporal interaction (ViewTemp) and a geometric-temporal point aggregation (PointTemp). Furthermore, we transfer knowledge from the biomedical LLM, LLaVA-Med, to deepen the comprehension of intraoperative relations. The proposed TriTemp-OR enables the aggregation of tri-modal features through relation-aware unification to predict relations so as to generate scene graphs. Experimental results on the 4D-OR benchmark demonstrate the superior performance of our model for long-term OR streaming.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores how to leverage multiple data modalities, including visual, audio, and temporal information, to generate comprehensive scene graphs for operating room environments.
- Proposes a tri-modal confluence model that combines these diverse inputs to capture the complex and dynamic nature of surgical workflows.
- Demonstrates the model's ability to outperform state-of-the-art approaches on scene graph generation tasks in operating rooms.
Plain English Explanation
Operating rooms are dynamic and complex environments, with numerous medical devices, tools, and interactions between healthcare professionals. Generating comprehensive scene graphs - visual representations that capture the relationships between the various elements in a scene - can be incredibly useful for understanding and optimizing surgical workflows.
This research paper presents a novel approach that leverages multiple data sources to create these scene graphs. Rather than relying solely on visual information, the proposed tri-modal confluence model also incorporates audio cues and temporal dynamics to provide a more comprehensive understanding of the operating room environment.
By combining these diverse data streams, the model can better capture the complex interactions and workflows that unfold over time in a surgical setting. This is a significant advancement over previous approaches that have focused on more limited, static snapshots of the scene.
The researchers demonstrate that their tri-modal confluence model outperforms state-of-the-art methods on scene graph generation tasks in operating rooms, highlighting the value of this multi-faceted approach to understanding these dynamic environments.
Technical Explanation
The core of the proposed method is a tri-modal confluence model that jointly leverages visual, audio, and temporal information to generate comprehensive scene graphs for operating room environments.
The visual module processes RGB image data to detect and recognize the various objects, people, and tools present in the scene. The audio module analyzes the acoustic signals to identify relevant sounds, such as medical equipment being used or verbal instructions from the surgical team.
Critically, the model also incorporates temporal dynamics to capture the evolving nature of the surgical workflow. By modeling the sequential relationships between the different elements in the scene over time, the system can better understand the context and significance of the observed interactions.
The outputs from these three modalities are then fused together through a series of attention mechanisms and neural network layers, allowing the model to learn the complex, multi-faceted relationships that characterize the operating room environment.
The researchers evaluate their tri-modal confluence model on a dataset of operating room footage, demonstrating its superior performance on scene graph generation tasks compared to state-of-the-art approaches that rely on more limited, single-modality inputs.
Critical Analysis
The researchers acknowledge several caveats and limitations to their work. First, the dataset used for evaluation, while comprehensive, is relatively small and may not capture the full diversity of operating room environments. Expanding the dataset to include more varied surgical procedures and healthcare settings could help validate the model's generalizability.
Additionally, while the tri-modal approach shows promising results, the researchers note that the relative contributions of the different data streams (visual, audio, temporal) may vary depending on the specific task or context. Further analysis to understand the optimal weighting of these modalities could lead to additional performance improvements.
Another potential area for improvement is the interpretability of the learned scene graphs. While the model can generate detailed representations of the operating room, the underlying reasoning and decision-making process is not always transparent. Developing techniques to better explain the model's outputs could enhance its utility for healthcare practitioners and researchers.
Finally, the researchers mention the potential for this technology to be applied beyond operating rooms, such as in other complex, dynamic environments like manufacturing or construction sites. Exploring these additional use cases could further demonstrate the broader applicability of the tri-modal confluence approach to scene graph generation.
Conclusion
This research paper presents a significant advancement in the field of scene understanding for operating room environments. By leveraging multiple data modalities and modeling temporal dynamics, the proposed tri-modal confluence model can generate more comprehensive and contextually-relevant scene graphs than previous state-of-the-art approaches.
The ability to capture the nuanced relationships and evolving workflows in operating rooms has important implications for improving surgical training, optimizing healthcare processes, and enhancing patient safety. As the model is further refined and expanded to other domains, it has the potential to transform how we understand and interact with complex, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ORacle: Large Vision-Language Models for Knowledge-Guided Holistic OR Domain Modeling
Ege Ozsoy, Chantal Pellegrini, Matthias Keicher, Nassir Navab
0
0
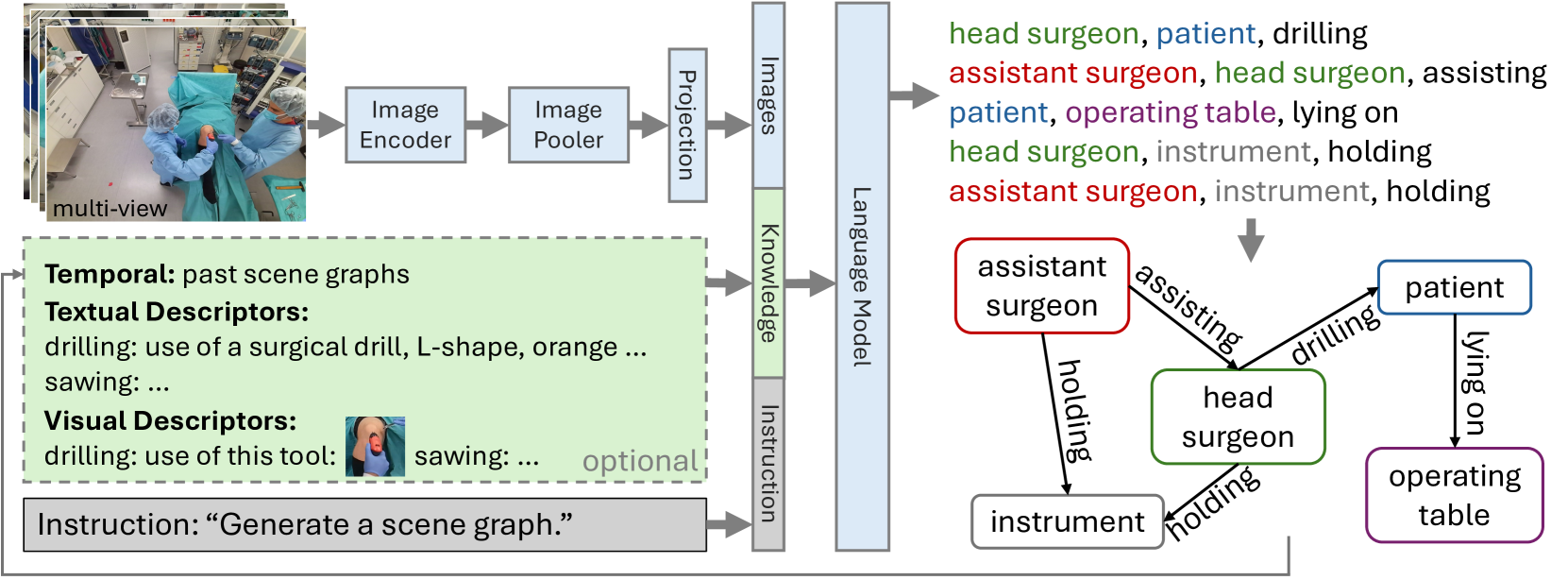
Every day, countless surgeries are performed worldwide, each within the distinct settings of operating rooms (ORs) that vary not only in their setups but also in the personnel, tools, and equipment used. This inherent diversity poses a substantial challenge for achieving a holistic understanding of the OR, as it requires models to generalize beyond their initial training datasets. To reduce this gap, we introduce ORacle, an advanced vision-language model designed for holistic OR domain modeling, which incorporates multi-view and temporal capabilities and can leverage external knowledge during inference, enabling it to adapt to previously unseen surgical scenarios. This capability is further enhanced by our novel data augmentation framework, which significantly diversifies the training dataset, ensuring ORacle's proficiency in applying the provided knowledge effectively. In rigorous testing, in scene graph generation, and downstream tasks on the 4D-OR dataset, ORacle not only demonstrates state-of-the-art performance but does so requiring less data than existing models. Furthermore, its adaptability is displayed through its ability to interpret unseen views, actions, and appearances of tools and equipment. This demonstrates ORacle's potential to significantly enhance the scalability and affordability of OR domain modeling and opens a pathway for future advancements in surgical data science. We will release our code and data upon acceptance.
4/11/2024

Unified Spatio-Temporal Tri-Perspective View Representation for 3D Semantic Occupancy Prediction
Sathira Silva, Savindu Bhashitha Wannigama, Gihan Jayatilaka, Muhammad Haris Khan, Roshan Ragel
0
0
Holistic understanding and reasoning in 3D scenes play a vital role in the success of autonomous driving systems. The evolution of 3D semantic occupancy prediction as a pretraining task for autonomous driving and robotic downstream tasks capture finer 3D details compared to methods like 3D detection. Existing approaches predominantly focus on spatial cues such as tri-perspective view embeddings (TPV), often overlooking temporal cues. This study introduces a spatiotemporal transformer architecture S2TPVFormer for temporally coherent 3D semantic occupancy prediction. We enrich the prior process by including temporal cues using a novel temporal cross-view hybrid attention mechanism (TCVHA) and generate spatiotemporal TPV embeddings (i.e. S2TPV embeddings). Experimental evaluations on the nuScenes dataset demonstrate a substantial 4.1% improvement in mean Intersection over Union (mIoU) for 3D Semantic Occupancy compared to TPVFormer, confirming the effectiveness of the proposed S2TPVFormer in enhancing 3D scene perception.
4/5/2024
Modeling social interaction dynamics using temporal graph networks
J. Taery Kim, Archit Naik, Isuru Jayarathne, Sehoon Ha, Jouh Yeong Chew
0
0
Integrating intelligent systems, such as robots, into dynamic group settings poses challenges due to the mutual influence of human behaviors and internal states. A robust representation of social interaction dynamics is essential for effective human-robot collaboration. Existing approaches often narrow their focus to facial expressions or speech, overlooking the broader context. We propose employing an adapted Temporal Graph Networks to comprehensively represent social interaction dynamics while enabling its practical implementation. Our method incorporates temporal multi-modal behavioral data including gaze interaction, voice activity and environmental context. This representation of social interaction dynamics is trained as a link prediction problem using annotated gaze interaction data. The F1-score outperformed the baseline model by 37.0%. This improvement is consistent for a secondary task of next speaker prediction which achieves an improvement of 29.0%. Our contributions are two-fold, including a model to representing social interaction dynamics which can be used for many downstream human-robot interaction tasks like human state inference and next speaker prediction. More importantly, this is achieved using a more concise yet efficient message passing method, significantly reducing it from 768 to 14 elements, while outperforming the baseline model.
4/11/2024
Efficient Data-driven Scene Simulation using Robotic Surgery Videos via Physics-embedded 3D Gaussians
Zhenya Yang, Kai Chen, Yonghao Long, Qi Dou
0
0
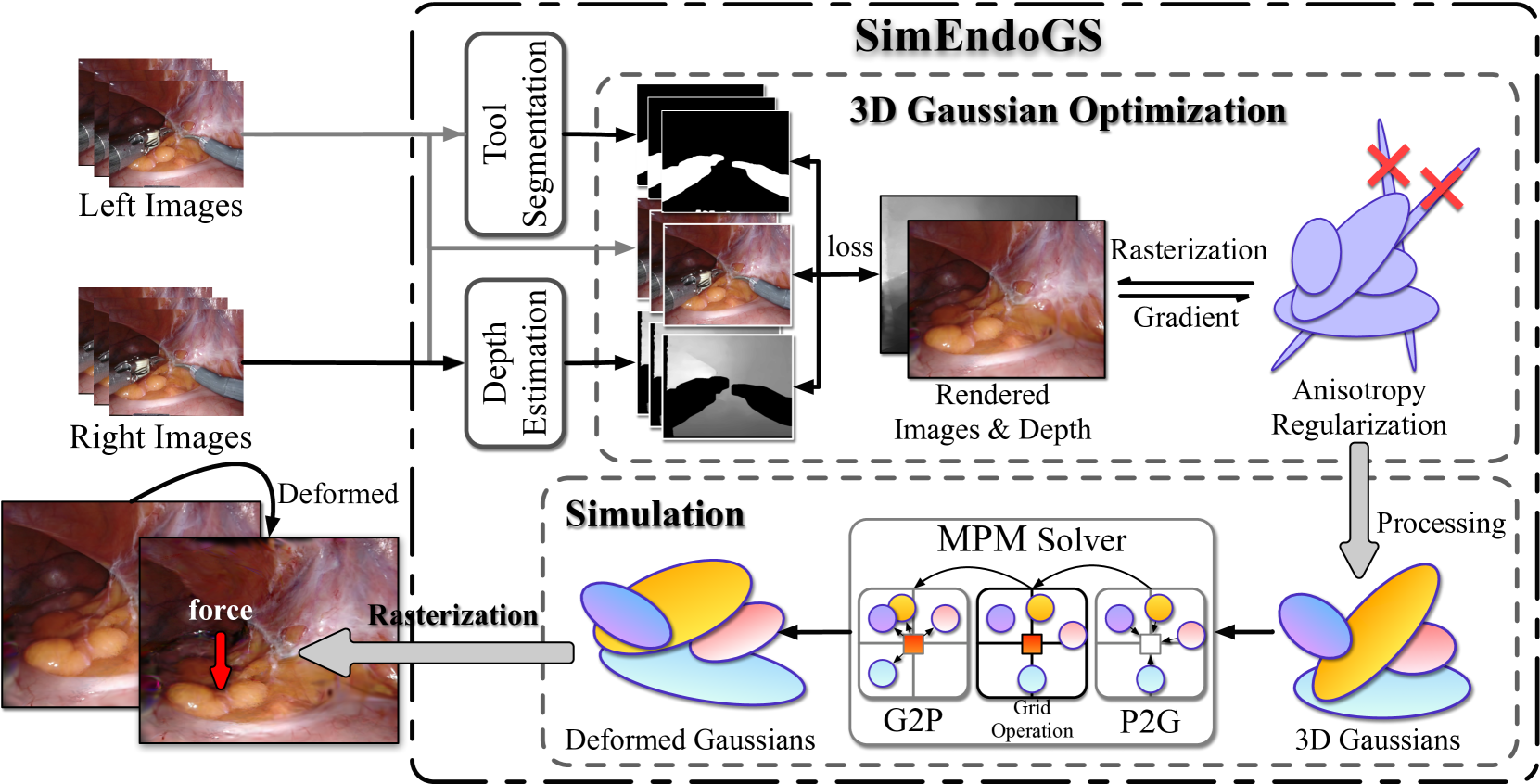
Surgical scene simulation plays a crucial role in surgical education and simulator-based robot learning. Traditional approaches for creating these environments with surgical scene involve a labor-intensive process where designers hand-craft tissues models with textures and geometries for soft body simulations. This manual approach is not only time-consuming but also limited in the scalability and realism. In contrast, data-driven simulation offers a compelling alternative. It has the potential to automatically reconstruct 3D surgical scenes from real-world surgical video data, followed by the application of soft body physics. This area, however, is relatively uncharted. In our research, we introduce 3D Gaussian as a learnable representation for surgical scene, which is learned from stereo endoscopic video. To prevent over-fitting and ensure the geometrical correctness of these scenes, we incorporate depth supervision and anisotropy regularization into the Gaussian learning process. Furthermore, we apply the Material Point Method, which is integrated with physical properties, to the 3D Gaussians to achieve realistic scene deformations. Our method was evaluated on our collected in-house and public surgical videos datasets. Results show that it can reconstruct and simulate surgical scenes from endoscopic videos efficiently-taking only a few minutes to reconstruct the surgical scene-and produce both visually and physically plausible deformations at a speed approaching real-time. The results demonstrate great potential of our proposed method to enhance the efficiency and variety of simulations available for surgical education and robot learning.
5/3/2024