ORacle: Large Vision-Language Models for Knowledge-Guided Holistic OR Domain Modeling
2404.07031
0
0
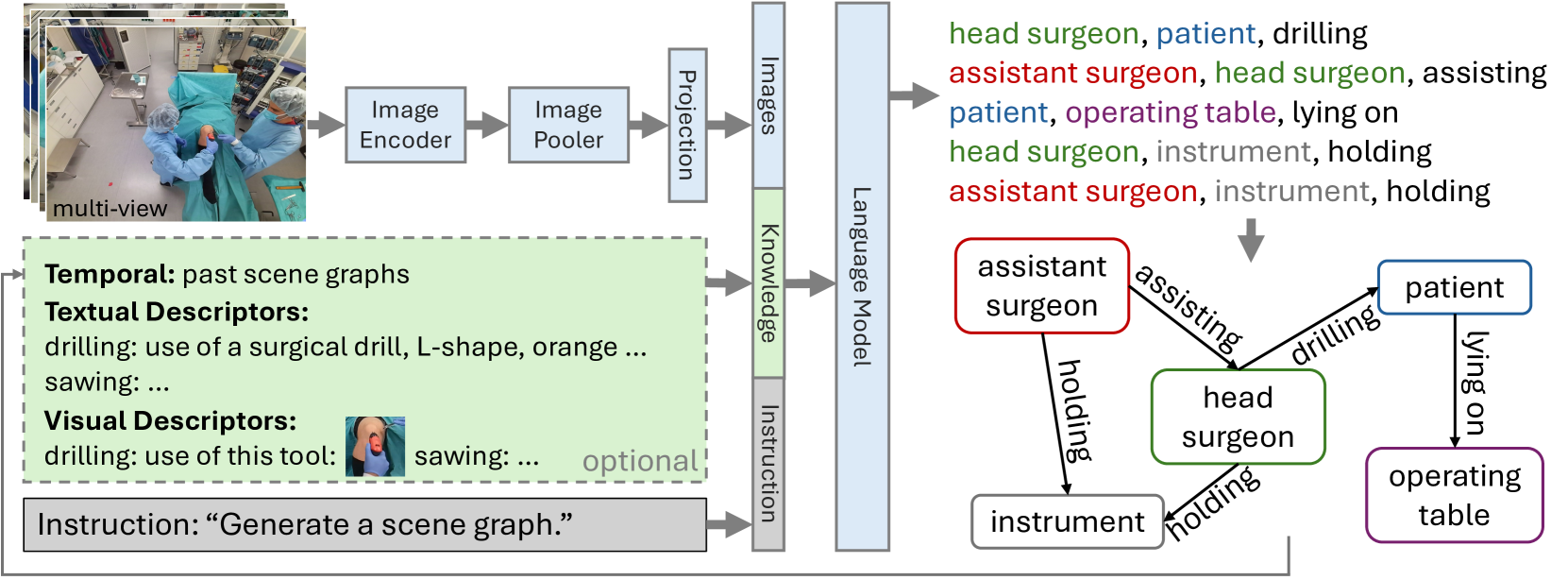
Abstract
Every day, countless surgeries are performed worldwide, each within the distinct settings of operating rooms (ORs) that vary not only in their setups but also in the personnel, tools, and equipment used. This inherent diversity poses a substantial challenge for achieving a holistic understanding of the OR, as it requires models to generalize beyond their initial training datasets. To reduce this gap, we introduce ORacle, an advanced vision-language model designed for holistic OR domain modeling, which incorporates multi-view and temporal capabilities and can leverage external knowledge during inference, enabling it to adapt to previously unseen surgical scenarios. This capability is further enhanced by our novel data augmentation framework, which significantly diversifies the training dataset, ensuring ORacle's proficiency in applying the provided knowledge effectively. In rigorous testing, in scene graph generation, and downstream tasks on the 4D-OR dataset, ORacle not only demonstrates state-of-the-art performance but does so requiring less data than existing models. Furthermore, its adaptability is displayed through its ability to interpret unseen views, actions, and appearances of tools and equipment. This demonstrates ORacle's potential to significantly enhance the scalability and affordability of OR domain modeling and opens a pathway for future advancements in surgical data science. We will release our code and data upon acceptance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new approach called "ORacle" that uses large vision-language models to enable holistic modeling of the Operating Room (OR) domain.
- The method combines visual and textual information to build a semantic scene graph that captures the complex relationships and interactions within the OR environment.
- The authors demonstrate the potential of this approach for tasks like surgical data science and knowledge-guided decision support.
Plain English Explanation
The paper presents a new way to model the complex world of the Operating Room (OR) using advanced artificial intelligence (AI) techniques. The researchers developed a system called "ORacle" that can take in visual information, like camera footage, and textual information, like medical reports, and use that to build a detailed understanding of everything that's going on in the OR.
This "semantic scene graph" captures all the different objects, people, and activities in the OR, as well as how they're related to each other. For example, it can identify the surgeon, the patient, the medical instruments, and understand how they're all interacting during a procedure.
The key innovation here is using large, powerful AI language and vision models that have been trained on huge amounts of data. This allows the system to understand the OR environment in a very holistic and nuanced way, going beyond just recognizing individual elements.
The authors suggest this could be really useful for things like improving surgical data analysis and developing decision support tools that can help medical teams make better choices during operations. By having this detailed, AI-powered understanding of the OR, it opens up new possibilities for enhancing medical care and research.
Technical Explanation
The paper introduces a new approach called "ORacle" that leverages large pre-trained vision-language models to enable holistic modeling of the Operating Room (OR) domain. The key innovation is the use of these powerful cross-modal AI models to fuse visual and textual information and construct a comprehensive semantic scene graph representation of the OR environment.
The ORacle framework first extracts visual features from camera footage using a vision model, and semantic concepts from medical reports using a language model. It then integrates this multi-modal information to build a holistic graph-based understanding of the OR, capturing the objects, people, activities and their relationships.
The authors demonstrate the potential of this approach for tasks like surgical data science and knowledge-guided decision support. By having this rich, AI-powered model of the OR, it opens up new possibilities for enhancing medical care and research through more sophisticated data analysis and intelligent systems.
Critical Analysis
The ORacle approach represents an exciting step forward in using advanced AI techniques to better understand complex medical environments like the Operating Room. The authors make a compelling case for the value of this holistic, multi-modal modeling approach, and provide evidence of its potential applications.
However, the paper does not address some important limitations and caveats. For example, the reliance on large pre-trained models means the system's performance is heavily dependent on the breadth and quality of the training data. There may be challenges in adapting it to niche medical settings or capturing nuanced domain knowledge.
Additionally, the ethical implications of such a powerful AI system monitoring sensitive medical procedures are not discussed. Issues around privacy, data governance, and potential biases in the underlying models would need to be carefully considered.
Further research is also needed to fully validate the ORacle approach, assess its real-world feasibility, and explore ways to make it more robust, adaptable and transparent. Nonetheless, this work represents an important step forward in the application of advanced AI to enhance healthcare.
Conclusion
The ORacle framework introduced in this paper demonstrates the potential of using large vision-language models to enable a holistic, knowledge-guided understanding of complex medical environments like the Operating Room. By fusing visual and textual information into a comprehensive semantic scene graph, the system offers new possibilities for improved surgical data analysis and intelligent decision support tools.
While the approach has some limitations and ethical considerations that require further exploration, this research represents an exciting advancement in the field of AI-powered healthcare applications. As these technologies continue to evolve, they may unlock transformative capabilities for enhancing medical care, training, and research in the years to come.
Related Papers
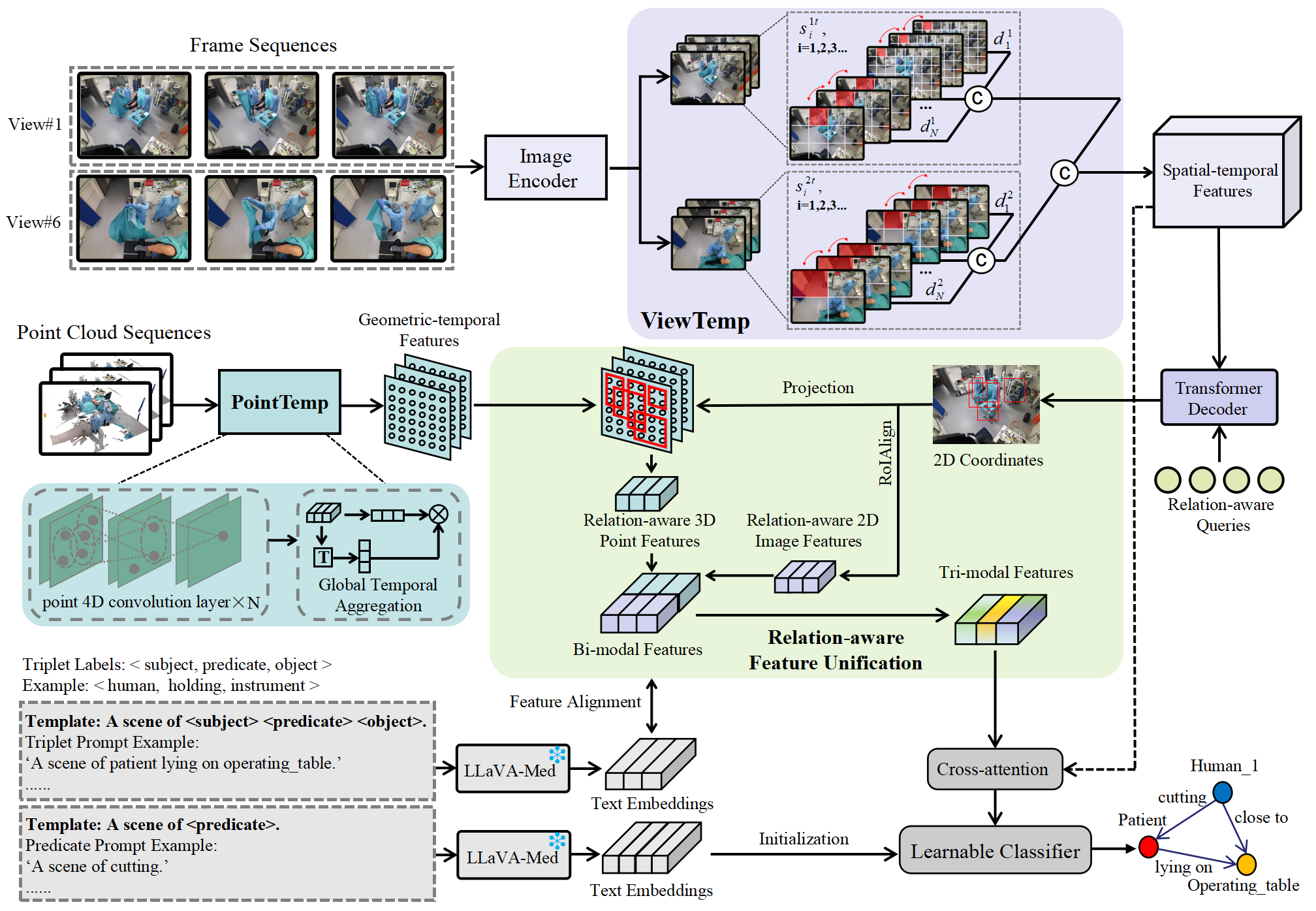
Tri-modal Confluence with Temporal Dynamics for Scene Graph Generation in Operating Rooms
Diandian Guo, Manxi Lin, Jialun Pei, He Tang, Yueming Jin, Pheng-Ann Heng
0
0
A comprehensive understanding of surgical scenes allows for monitoring of the surgical process, reducing the occurrence of accidents and enhancing efficiency for medical professionals. Semantic modeling within operating rooms, as a scene graph generation (SGG) task, is challenging since it involves consecutive recognition of subtle surgical actions over prolonged periods. To address this challenge, we propose a Tri-modal (i.e., images, point clouds, and language) confluence with Temporal dynamics framework, termed TriTemp-OR. Diverging from previous approaches that integrated temporal information via memory graphs, our method embraces two advantages: 1) we directly exploit bi-modal temporal information from the video streaming for hierarchical feature interaction, and 2) the prior knowledge from Large Language Models (LLMs) is embedded to alleviate the class-imbalance problem in the operating theatre. Specifically, our model performs temporal interactions across 2D frames and 3D point clouds, including a scale-adaptive multi-view temporal interaction (ViewTemp) and a geometric-temporal point aggregation (PointTemp). Furthermore, we transfer knowledge from the biomedical LLM, LLaVA-Med, to deepen the comprehension of intraoperative relations. The proposed TriTemp-OR enables the aggregation of tri-modal features through relation-aware unification to predict relations so as to generate scene graphs. Experimental results on the 4D-OR benchmark demonstrate the superior performance of our model for long-term OR streaming.
4/16/2024
👀
Vision Beyond Boundaries: An Initial Design Space of Domain-specific Large Vision Models in Human-robot Interaction
Yuchong Zhang, Yong Ma, Danica Kragic
0
0
The emergence of Large Vision Models (LVMs) is following in the footsteps of the recent prosperity of Large Language Models (LLMs) in following years. However, there's a noticeable gap in structured research applying LVMs to Human-Robot Interaction (HRI), despite extensive evidence supporting the efficacy of vision models in enhancing interactions between humans and robots. Recognizing the vast and anticipated potential, we introduce an initial design space that incorporates domain-specific LVMs, chosen for their superior performance over normal models. We delve into three primary dimensions: HRI contexts, vision-based tasks, and specific domains. The empirical validation was implemented among 15 experts across six evaluated metrics, showcasing the primary efficacy in relevant decision-making scenarios. We explore the process of ideation and potential application scenarios, envisioning this design space as a foundational guideline for future HRI system design, emphasizing accurate domain alignment and model selection.
4/24/2024
👀
Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
Cuong Nhat Ha, Shima Asaadi, Sanjeev Kumar Karn, Oladimeji Farri, Tobias Heimann, Thomas Runkler
0
0
Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
4/26/2024
Large language models as oracles for instantiating ontologies with domain-specific knowledge
Giovanni Ciatto, Andrea Agiollo, Matteo Magnini, Andrea Omicini
0
0
Background. Endowing intelligent systems with semantic data commonly requires designing and instantiating ontologies with domain-specific knowledge. Especially in the early phases, those activities are typically performed manually by human experts possibly leveraging on their own experience. The resulting process is therefore time-consuming, error-prone, and often biased by the personal background of the ontology designer. Objective. To mitigate that issue, we propose a novel domain-independent approach to automatically instantiate ontologies with domain-specific knowledge, by leveraging on large language models (LLMs) as oracles. Method. Starting from (i) an initial schema composed by inter-related classes andproperties and (ii) a set of query templates, our method queries the LLM multi- ple times, and generates instances for both classes and properties from its replies. Thus, the ontology is automatically filled with domain-specific knowledge, compliant to the initial schema. As a result, the ontology is quickly and automatically enriched with manifold instances, which experts may consider to keep, adjust, discard, or complement according to their own needs and expertise. Contribution. We formalise our method in general way and instantiate it over various LLMs, as well as on a concrete case study. We report experiments rooted in the nutritional domain where an ontology of food meals and their ingredients is semi-automatically instantiated from scratch, starting from a categorisation of meals and their relationships. There, we analyse the quality of the generated ontologies and compare ontologies attained by exploiting different LLMs. Finally, we provide a SWOT analysis of the proposed method.
4/8/2024