From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
2404.00906
0
0
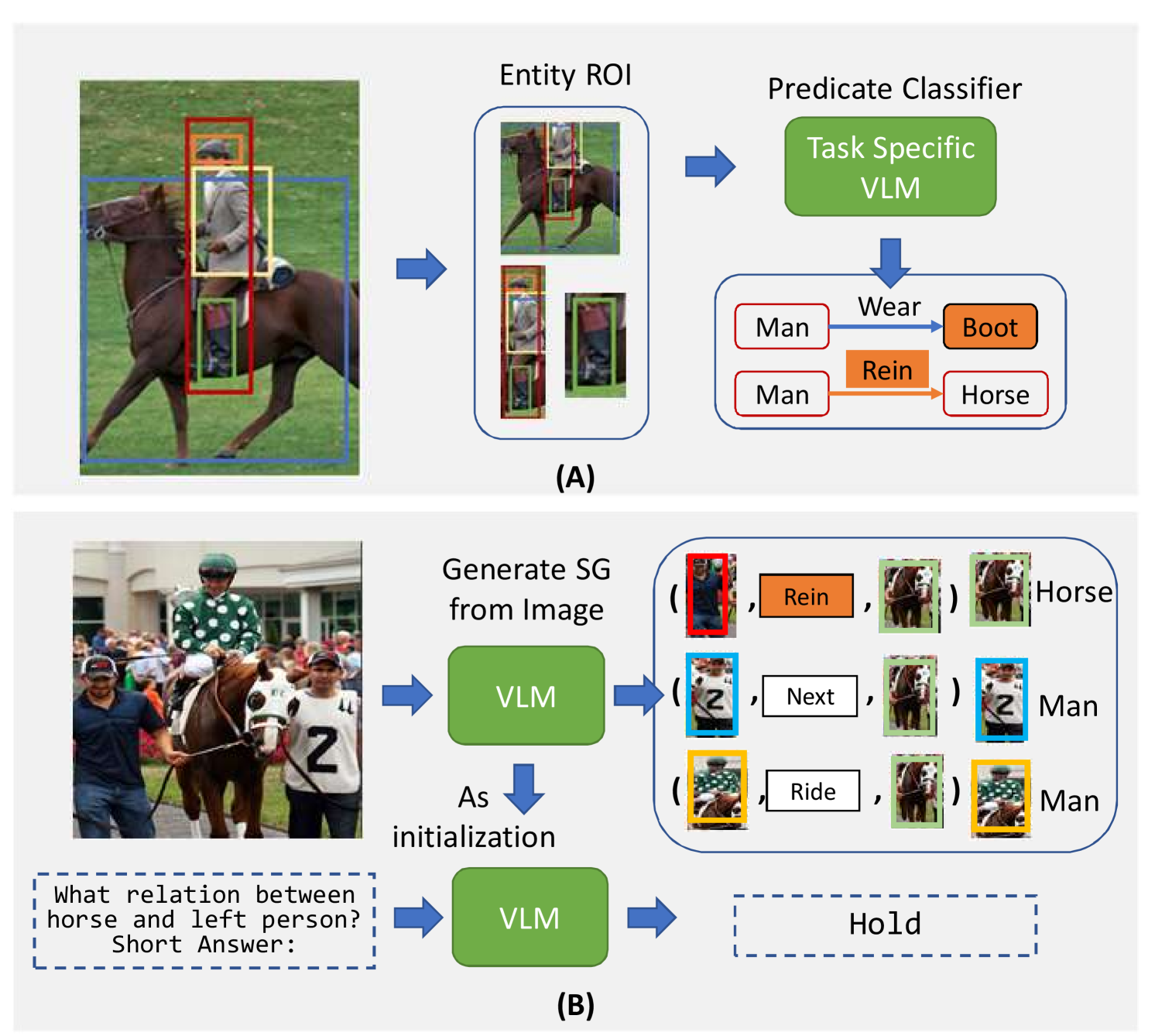
Abstract
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents a method for generating open-vocabulary scene graphs from images using vision-language models.
- Scene graphs are a structured representation of the objects, relationships, and attributes in an image, which can be useful for tasks like image understanding and reasoning.
- The approach leverages large pre-trained vision-language models like CLIP to detect and classify objects and their relationships, without being limited to a fixed set of pre-defined concepts.
Plain English Explanation
The researchers have developed a way to automatically create detailed descriptions of the contents of images, going beyond just identifying the objects present. Their method can generate "scene graphs" - diagrams that show the various elements in an image and how they are connected.
For example, a scene graph for an image of a kitchen might include nodes representing a stove, a table, and a person, as well as edges indicating that the person is sitting at the table or that the stove is located in the kitchen. This structured representation provides a richer understanding of the overall scene compared to just listing the individual objects.
Importantly, the approach is "open-vocabulary", meaning it can recognize and describe a wide range of objects, actions, and relationships, not just a fixed set of pre-defined concepts. This is enabled by leveraging large language models that have been trained on vast amounts of text data, allowing them to understand and reason about a diverse set of visual elements.
By connecting pixels to conceptual knowledge in this way, the researchers aim to move towards more holistic and flexible scene understanding, with applications in areas like image captioning, visual question answering, and robotic perception. This could lead to AI systems that can engage in more meaningful and contextual interactions with the visual world.
Technical Explanation
The paper introduces a novel approach for [object Object] using [object Object]. The key idea is to leverage the rich semantic understanding captured by large-scale [object Object] to detect and classify objects and their relationships in a more open-ended and generalizable way, compared to traditional scene graph generation approaches.
The proposed method takes an input image and uses a vision-language model like CLIP to extract features representing the visual content. These features are then used to predict a set of objects, their attributes, and the relationships between them, resulting in a structured scene graph representation. Notably, the approach is not limited to a fixed vocabulary of pre-defined concepts, but can handle a much broader range of visual elements by drawing on the extensive knowledge captured by the underlying vision-language model.
The authors evaluate their method on standard scene graph benchmarks, [object Object] compared to prior work. They also show how the generated scene graphs can be used to support various downstream vision-and-language tasks, such as [object Object].
Critical Analysis
The paper presents a compelling approach for leveraging the power of large-scale vision-language models to enable more flexible and open-ended scene graph generation. By moving beyond fixed vocabularies, the method can potentially capture a richer set of visual concepts and relationships, which could lead to more meaningful scene understanding.
However, the authors acknowledge some limitations of their current approach. For example, the performance on certain relationship prediction tasks still lags behind specialized scene graph generation models, suggesting there is room for further improvement. Additionally, the reliance on pre-trained vision-language models means the approach could be susceptible to biases or errors present in those underlying models.
It would also be interesting to see how the generated scene graphs could be further refined or enhanced, perhaps through iterative interaction with human users or by integrating the scene graph generation with other complementary vision-and-language tasks. Exploring ways to make the scene graphs more actionable or interpretable for downstream applications could also be a fruitful area for future research.
Overall, this work represents an exciting step towards more flexible and powerful scene understanding, with the potential to enable AI systems that can engage with the visual world in increasingly sophisticated and contextual ways.
Conclusion
The paper presents a novel approach for generating open-vocabulary scene graphs from images using vision-language models. By leveraging the rich semantic knowledge captured by large-scale pre-trained models, the method can detect and classify a diverse range of visual elements, going beyond the limitations of traditional scene graph generation techniques.
The demonstrated capability to create structured representations of image content, with a focus on objects, attributes, and relationships, has promising applications in areas like image understanding, reasoning, and multimodal interaction. As the field of vision-and-language continues to advance, this work highlights the potential of integrating powerful language-based representations with visual perception to enable more holistic and flexible scene understanding.
While the current approach has some limitations, the overall direction of the research is exciting and points towards a future where AI systems can engage with the visual world in increasingly sophisticated and contextual ways, with benefits for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
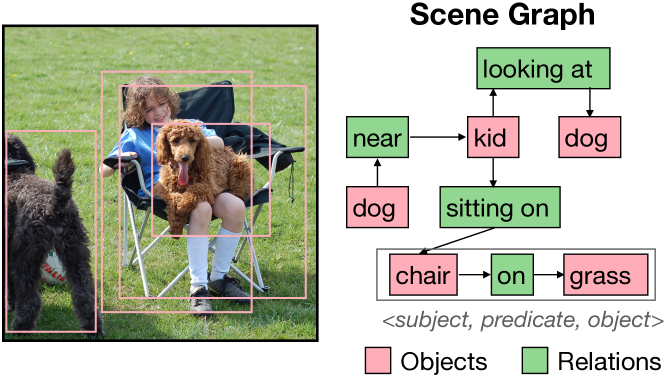
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Naitik Khandelwal, Xiao Liu, Mengmi Zhang
0
0
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
4/15/2024
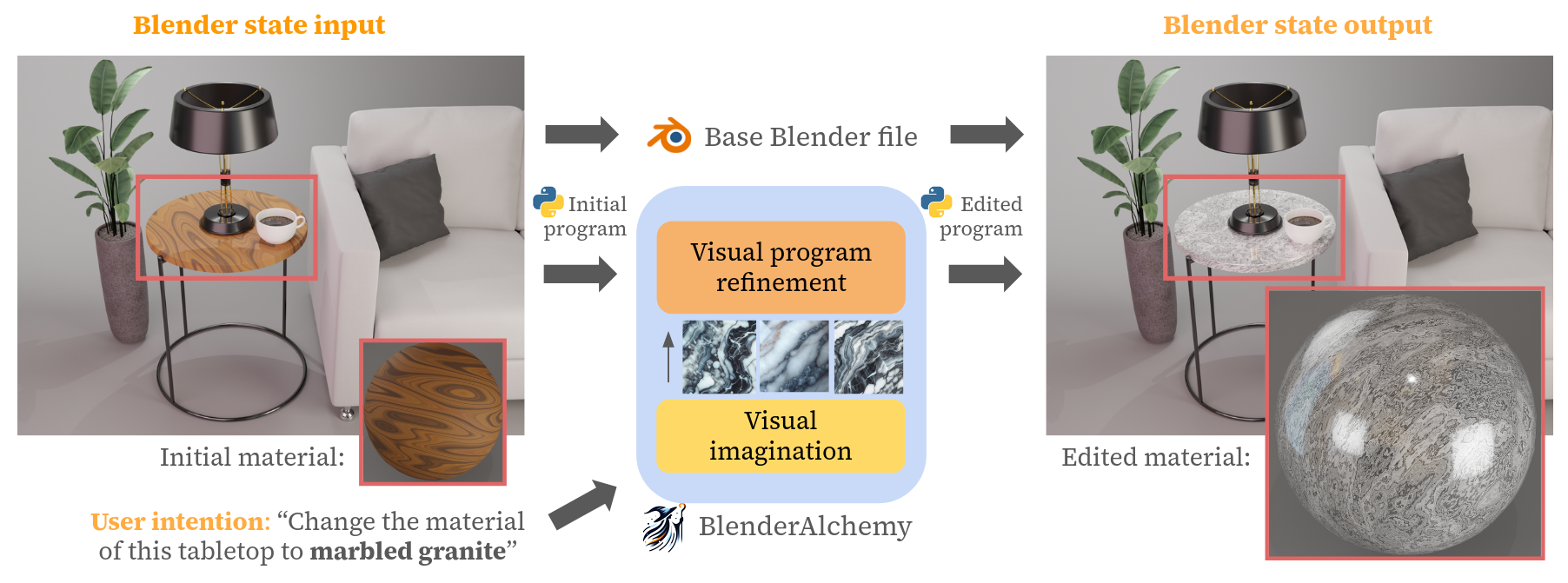
BlenderAlchemy: Editing 3D Graphics with Vision-Language Models
Ian Huang, Guandao Yang, Leonidas Guibas
0
0
Graphics design is important for various applications, including movie production and game design. To create a high-quality scene, designers usually need to spend hours in software like Blender, in which they might need to interleave and repeat operations, such as connecting material nodes, hundreds of times. Moreover, slightly different design goals may require completely different sequences, making automation difficult. In this paper, we propose a system that leverages Vision-Language Models (VLMs), like GPT-4V, to intelligently search the design action space to arrive at an answer that can satisfy a user's intent. Specifically, we design a vision-based edit generator and state evaluator to work together to find the correct sequence of actions to achieve the goal. Inspired by the role of visual imagination in the human design process, we supplement the visual reasoning capabilities of VLMs with imagined reference images from image-generation models, providing visual grounding of abstract language descriptions. In this paper, we provide empirical evidence suggesting our system can produce simple but tedious Blender editing sequences for tasks such as editing procedural materials from text and/or reference images, as well as adjusting lighting configurations for product renderings in complex scenes.
4/30/2024
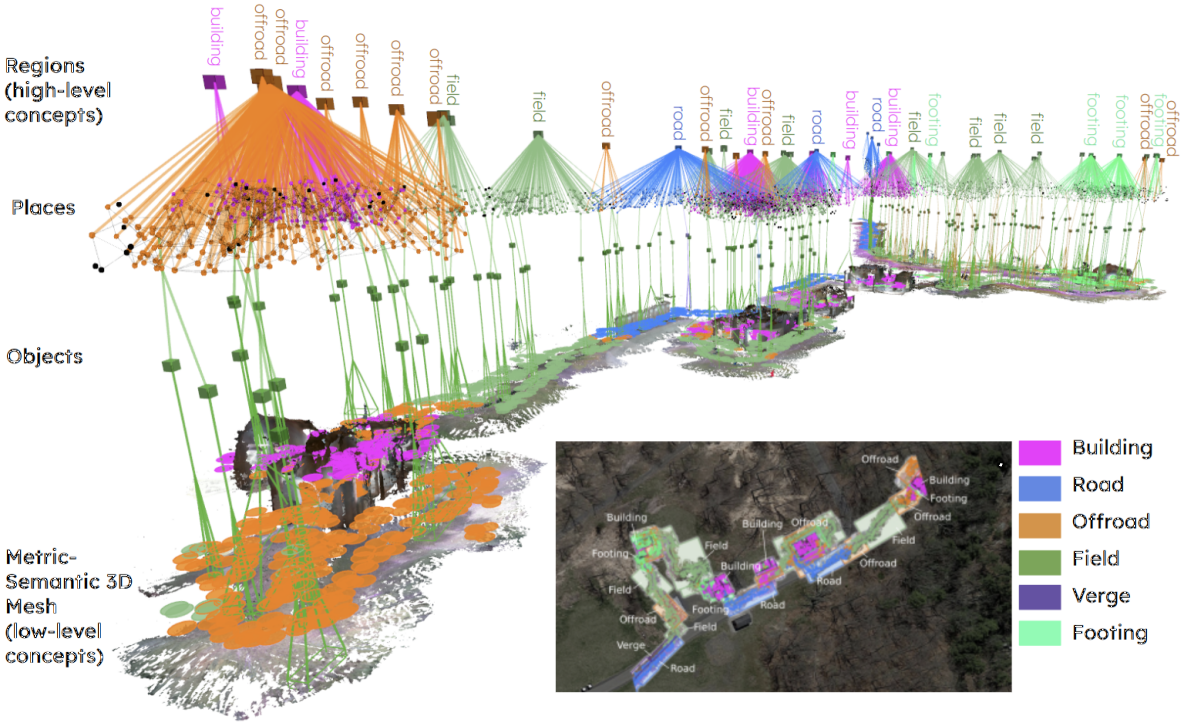
Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies
Jared Strader, Nathan Hughes, William Chen, Alberto Speranzon, Luca Carlone
0
0
This paper proposes an approach to build 3D scene graphs in arbitrary indoor and outdoor environments. Such extension is challenging; the hierarchy of concepts that describe an outdoor environment is more complex than for indoors, and manually defining such hierarchy is time-consuming and does not scale. Furthermore, the lack of training data prevents the straightforward application of learning-based tools used in indoor settings. To address these challenges, we propose two novel extensions. First, we develop methods to build a spatial ontology defining concepts and relations relevant for indoor and outdoor robot operation. In particular, we use a Large Language Model (LLM) to build such an ontology, thus largely reducing the amount of manual effort required. Second, we leverage the spatial ontology for 3D scene graph construction using Logic Tensor Networks (LTN) to add logical rules, or axioms (e.g., a beach contains sand), which provide additional supervisory signals at training time thus reducing the need for labelled data, providing better predictions, and even allowing predicting concepts unseen at training time. We test our approach in a variety of datasets, including indoor, rural, and coastal environments, and show that it leads to a significant increase in the quality of the 3D scene graph generation with sparsely annotated data.
4/26/2024
AUG: A New Dataset and An Efficient Model for Aerial Image Urban Scene Graph Generation
Yansheng Li, Kun Li, Yongjun Zhang, Linlin Wang, Dingwen Zhang
0
0
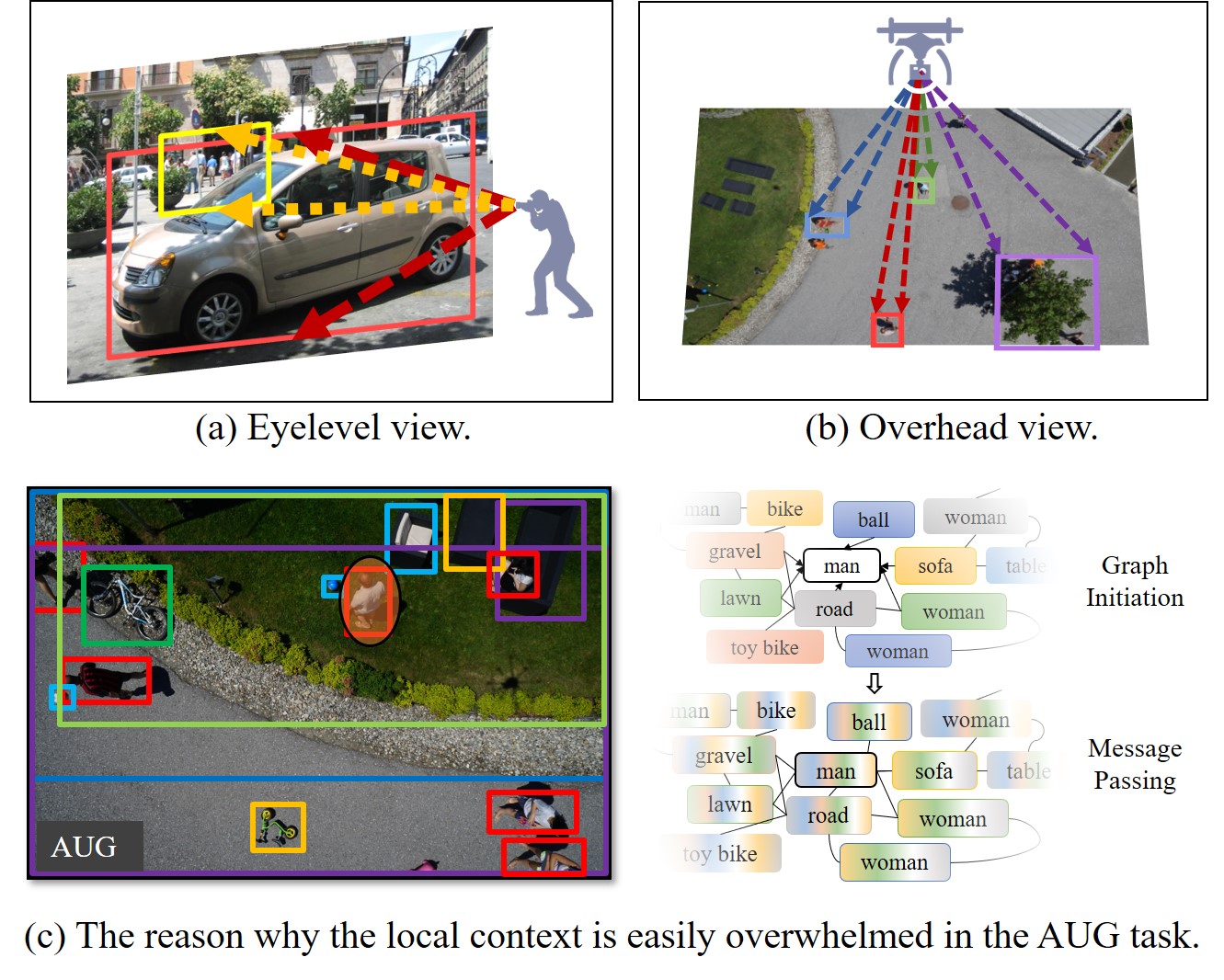
Scene graph generation (SGG) aims to understand the visual objects and their semantic relationships from one given image. Until now, lots of SGG datasets with the eyelevel view are released but the SGG dataset with the overhead view is scarcely studied. By contrast to the object occlusion problem in the eyelevel view, which impedes the SGG, the overhead view provides a new perspective that helps to promote the SGG by providing a clear perception of the spatial relationships of objects in the ground scene. To fill in the gap of the overhead view dataset, this paper constructs and releases an aerial image urban scene graph generation (AUG) dataset. Images from the AUG dataset are captured with the low-attitude overhead view. In the AUG dataset, 25,594 objects, 16,970 relationships, and 27,175 attributes are manually annotated. To avoid the local context being overwhelmed in the complex aerial urban scene, this paper proposes one new locality-preserving graph convolutional network (LPG). Different from the traditional graph convolutional network, which has the natural advantage of capturing the global context for SGG, the convolutional layer in the LPG integrates the non-destructive initial features of the objects with dynamically updated neighborhood information to preserve the local context under the premise of mining the global context. To address the problem that there exists an extra-large number of potential object relationship pairs but only a small part of them is meaningful in AUG, we propose the adaptive bounding box scaling factor for potential relationship detection (ABS-PRD) to intelligently prune the meaningless relationship pairs. Extensive experiments on the AUG dataset show that our LPG can significantly outperform the state-of-the-art methods and the effectiveness of the proposed locality-preserving strategy.
4/12/2024