Triple Preference Optimization: Achieving Better Alignment with Less Data in a Single Step Optimization
2405.16681
0
0
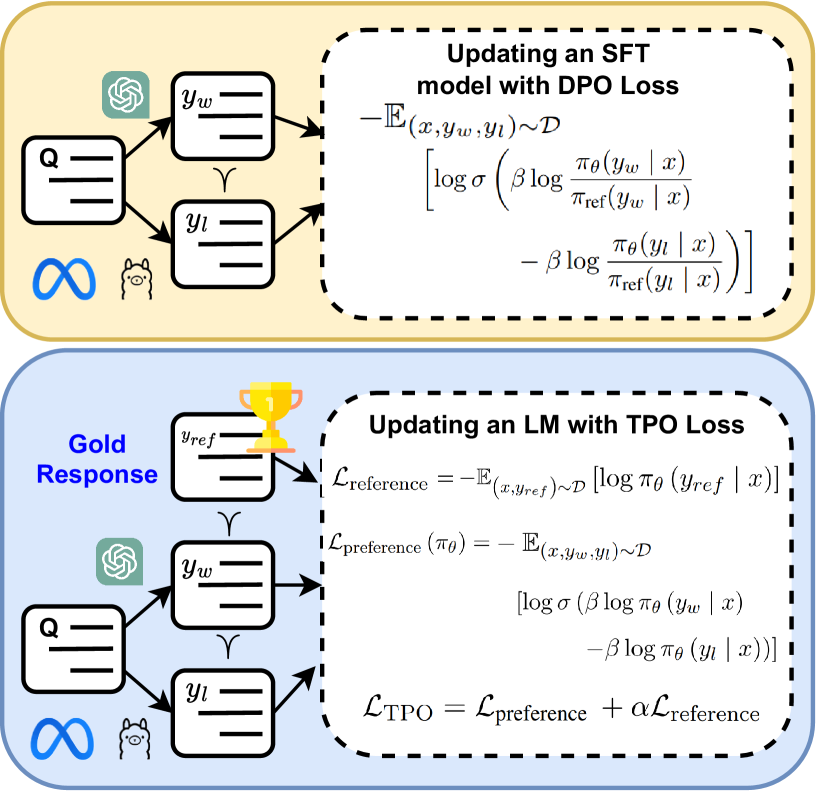
Abstract
Large Language Models (LLMs) perform well across diverse tasks, but aligning them with human demonstrations is challenging. Recently, Reinforcement Learning (RL)-free methods like Direct Preference Optimization (DPO) have emerged, offering improved stability and scalability while retaining competitive performance relative to RL-based methods. However, while RL-free methods deliver satisfactory performance, they require significant data to develop a robust Supervised Fine-Tuned (SFT) model and an additional step to fine-tune this model on a preference dataset, which constrains their utility and scalability. In this paper, we introduce Triple Preference Optimization (TPO), a new preference learning method designed to align an LLM with three preferences without requiring a separate SFT step and using considerably less data. Through a combination of practical experiments and theoretical analysis, we show the efficacy of TPO as a single-step alignment strategy. Specifically, we fine-tuned the Phi-2 (2.7B) and Mistral (7B) models using TPO directly on the UltraFeedback dataset, achieving superior results compared to models aligned through other methods such as SFT, DPO, KTO, IPO, CPO, and ORPO. Moreover, the performance of TPO without the SFT component led to notable improvements in the MT-Bench score, with increases of +1.27 and +0.63 over SFT and DPO, respectively. Additionally, TPO showed higher average accuracy, surpassing DPO and SFT by 4.2% and 4.97% on the Open LLM Leaderboard benchmarks. Our code is publicly available at https://github.com/sahsaeedi/triple-preference-optimization .
Create account to get full access
Overview
- Presents a new optimization method called "Triple Preference Optimization" (TPO) that aims to align large language models with less training data compared to existing approaches.
- Introduces a novel objective function that combines three different preference types to achieve better alignment with user preferences.
- Claims TPO can outperform previous methods like Direct Preference Optimization (DPO), Multi-Reference Preference Optimization (MRPO), and Token-level Direct Preference Optimization (TDPO) in terms of alignment with user preferences.
Plain English Explanation
The paper proposes a new way to train large language models to better match user preferences, using an approach called "Triple Preference Optimization" (TPO). The key idea is to combine three different types of preferences - direct feedback, relative feedback, and reference feedback - into a single optimization objective. This allows the model to learn user preferences more effectively, using less training data compared to prior methods.
The direct feedback captures the user's direct assessment of the model's output. The relative feedback compares the model's output to other alternatives. And the reference feedback compares the model's output to a set of high-quality reference examples.
By incorporating these three preference signals, the TPO method aims to guide the model towards outputs that better align with what users want, even with less training data. The authors claim this leads to superior alignment compared to earlier approaches like Direct Preference Optimization (DPO), Multi-Reference Preference Optimization (MRPO), and Token-level Direct Preference Optimization (TDPO).
Technical Explanation
The paper introduces a new optimization method called "Triple Preference Optimization" (TPO) for aligning large language models with user preferences. TPO combines three different types of preference signals into a single objective function:
-
Direct Preference: This captures the user's direct assessment or rating of the model's output.
-
Relative Preference: This compares the model's output to other alternatives, capturing the user's relative preference.
-
Reference Preference: This compares the model's output to a set of high-quality reference examples, assessing how well the model matches these references.
By incorporating these three preference types, the TPO objective function aims to guide the model towards outputs that better align with what users want, even with less training data compared to prior methods.
The authors evaluate TPO against several baselines, including Direct Preference Optimization (DPO), Multi-Reference Preference Optimization (MRPO), and Token-level Direct Preference Optimization (TDPO). The results show that TPO can achieve better alignment with user preferences using less training data than these previous approaches.
Critical Analysis
The paper provides a novel optimization method that combines multiple preference signals to improve the alignment of large language models with user preferences. However, there are a few potential limitations and areas for further research:
-
Generalization Across Domains: The experiments in the paper focus on a specific domain (e.g., summarization). It would be important to evaluate the generalization of TPO across a wider range of tasks and domains to assess its broader applicability.
-
Interpretability and Transparency: The paper does not delve into the interpretability of the TPO method or how the different preference signals contribute to the final alignment. Providing more transparency around the inner workings of TPO could help users better understand its strengths and limitations.
-
Scalability and Computational Efficiency: While TPO claims to require less training data, the added complexity of the multi-objective function may introduce computational and memory overhead. Evaluating the scalability and efficiency of TPO, especially for large-scale language models, would be an important area for further research.
-
Robustness to Noisy or Biased Preferences: The paper assumes that the user preferences used for training are accurate and unbiased. It would be valuable to investigate the robustness of TPO to noisy or biased preference signals, which are common in real-world settings.
Overall, the TPO method presents a promising approach to improving the alignment of large language models with user preferences using less training data. Further research on the generalization, interpretability, scalability, and robustness of the method could help solidify its value and applicability in practical settings.
Conclusion
This paper introduces a new optimization method called "Triple Preference Optimization" (TPO) that aims to align large language models with user preferences using less training data compared to previous approaches. TPO combines three different types of preference signals - direct, relative, and reference - into a single objective function to guide the model towards outputs that better match what users want.
The authors claim that TPO can outperform existing methods like Direct Preference Optimization (DPO), Multi-Reference Preference Optimization (MRPO), and Token-level Direct Preference Optimization (TDPO) in terms of alignment with user preferences, using less training data.
While the TPO method shows promise, further research is needed to address potential limitations, such as the generalization across domains, interpretability of the method, scalability, and robustness to noisy or biased preference signals. Addressing these areas could help solidify the value and practical applicability of the TPO approach in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
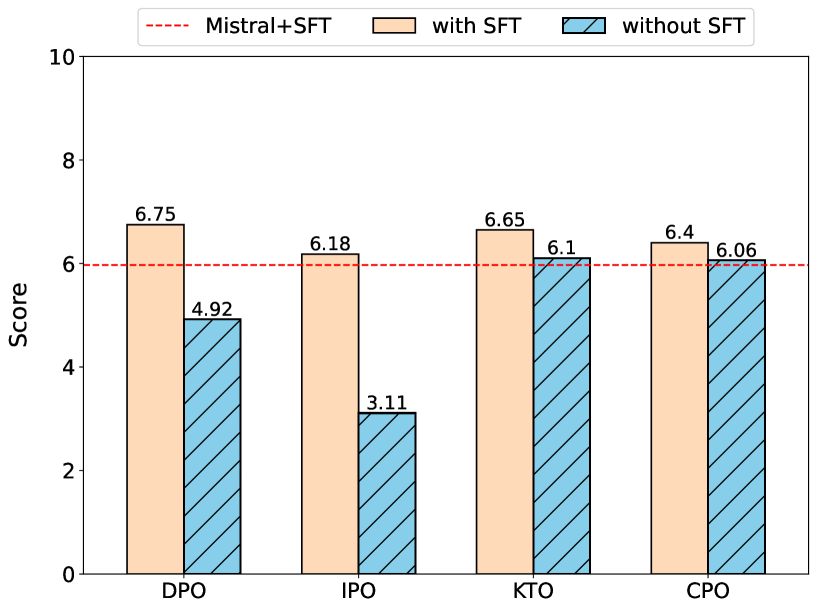
Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks
Amir Saeidi, Shivanshu Verma, Chitta Baral
0
0
Large Language Models (LLMs) have demonstrated remarkable performance across a spectrum of tasks. Recently, Direct Preference Optimization (DPO) has emerged as an RL-free approach to optimize the policy model on human preferences. However, several limitations hinder the widespread adoption of this method. To address these shortcomings, various versions of DPO have been introduced. Yet, a comprehensive evaluation of these variants across diverse tasks is still lacking. In this study, we aim to bridge this gap by investigating the performance of alignment methods across three distinct scenarios: (1) keeping the Supervised Fine-Tuning (SFT) part, (2) skipping the SFT part, and (3) skipping the SFT part and utilizing an instruction-tuned model. Furthermore, we explore the impact of different training sizes on their performance. Our evaluation spans a range of tasks including dialogue systems, reasoning, mathematical problem-solving, question answering, truthfulness, and multi-task understanding, encompassing 13 benchmarks such as MT-Bench, Big Bench, and Open LLM Leaderboard. Key observations reveal that alignment methods achieve optimal performance with smaller training data subsets, exhibit limited effectiveness in reasoning tasks yet significantly impact mathematical problem-solving, and employing an instruction-tuned model notably influences truthfulness. We anticipate that our findings will catalyze further research aimed at developing more robust models to address alignment challenges.
4/24/2024
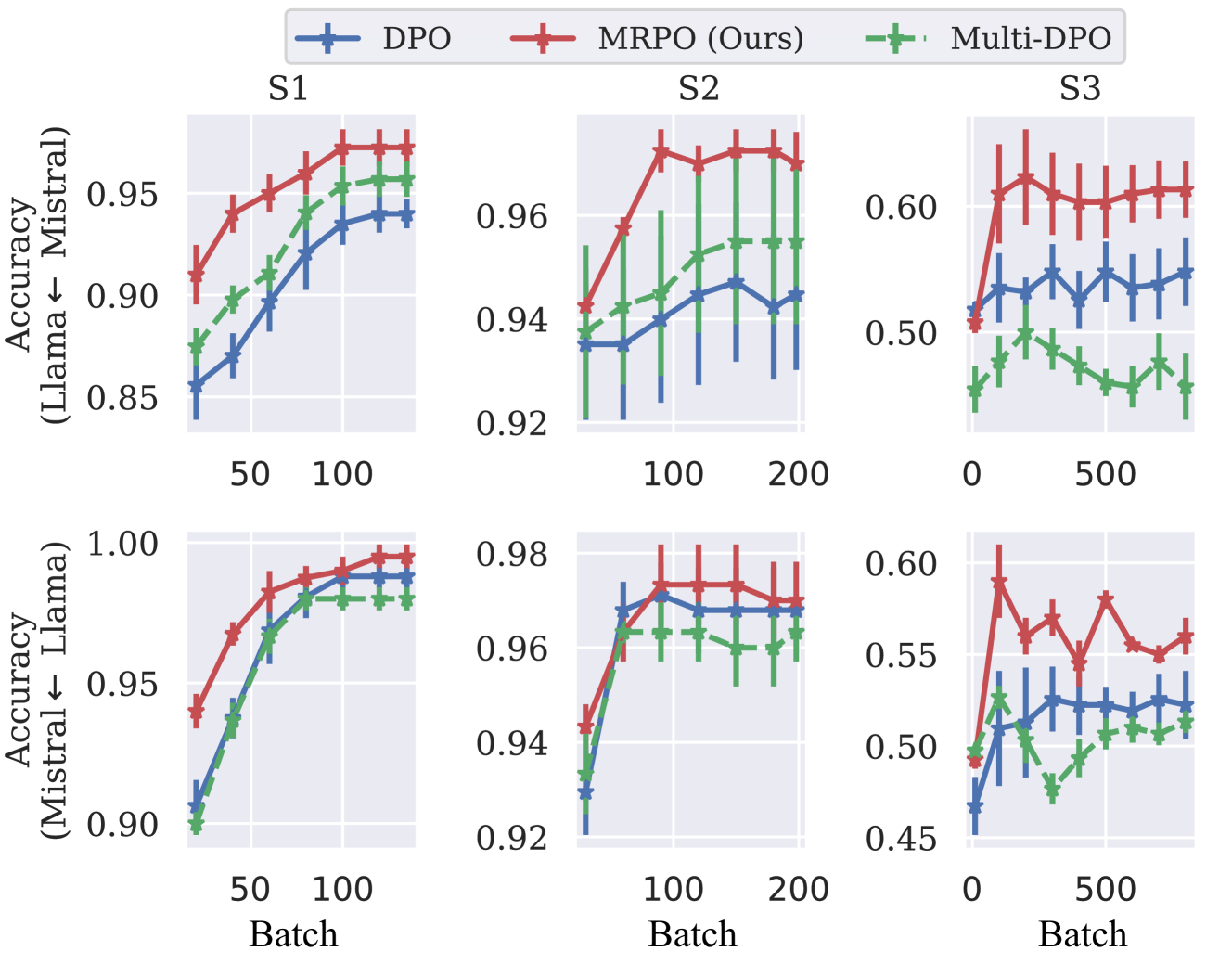
Multi-Reference Preference Optimization for Large Language Models
Hung Le, Quan Tran, Dung Nguyen, Kien Do, Saloni Mittal, Kelechi Ogueji, Svetha Venkatesh
0
0
How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.
5/28/2024

New!Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, Jiaya Jia
0
0
Mathematical reasoning presents a significant challenge for Large Language Models (LLMs) due to the extensive and precise chain of reasoning required for accuracy. Ensuring the correctness of each reasoning step is critical. To address this, we aim to enhance the robustness and factuality of LLMs by learning from human feedback. However, Direct Preference Optimization (DPO) has shown limited benefits for long-chain mathematical reasoning, as models employing DPO struggle to identify detailed errors in incorrect answers. This limitation stems from a lack of fine-grained process supervision. We propose a simple, effective, and data-efficient method called Step-DPO, which treats individual reasoning steps as units for preference optimization rather than evaluating answers holistically. Additionally, we have developed a data construction pipeline for Step-DPO, enabling the creation of a high-quality dataset containing 10K step-wise preference pairs. We also observe that in DPO, self-generated data is more effective than data generated by humans or GPT-4, due to the latter's out-of-distribution nature. Our findings demonstrate that as few as 10K preference data pairs and fewer than 500 Step-DPO training steps can yield a nearly 3% gain in accuracy on MATH for models with over 70B parameters. Notably, Step-DPO, when applied to Qwen2-72B-Instruct, achieves scores of 70.8% and 94.0% on the test sets of MATH and GSM8K, respectively, surpassing a series of closed-source models, including GPT-4-1106, Claude-3-Opus, and Gemini-1.5-Pro. Our code, data, and models are available at https://github.com/dvlab-research/Step-DPO.
6/28/2024
Token-level Direct Preference Optimization
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, Jun Wang
0
0
Fine-tuning pre-trained Large Language Models (LLMs) is essential to align them with human values and intentions. This process often utilizes methods like pairwise comparisons and KL divergence against a reference LLM, focusing on the evaluation of full answers generated by the models. However, the generation of these responses occurs in a token level, following a sequential, auto-regressive fashion. In this paper, we introduce Token-level Direct Preference Optimization (TDPO), a novel approach to align LLMs with human preferences by optimizing policy at the token level. Unlike previous methods, which face challenges in divergence efficiency, TDPO incorporates forward KL divergence constraints for each token, improving alignment and diversity. Utilizing the Bradley-Terry model for a token-based reward system, TDPO enhances the regulation of KL divergence, while preserving simplicity without the need for explicit reward modeling. Experimental results across various text tasks demonstrate TDPO's superior performance in balancing alignment with generation diversity. Notably, fine-tuning with TDPO strikes a better balance than DPO in the controlled sentiment generation and single-turn dialogue datasets, and significantly improves the quality of generated responses compared to both DPO and PPO-based RLHF methods. Our code is open-sourced at https://github.com/Vance0124/Token-level-Direct-Preference-Optimization.
6/28/2024