Multi-Reference Preference Optimization for Large Language Models
2405.16388
0
0
Abstract
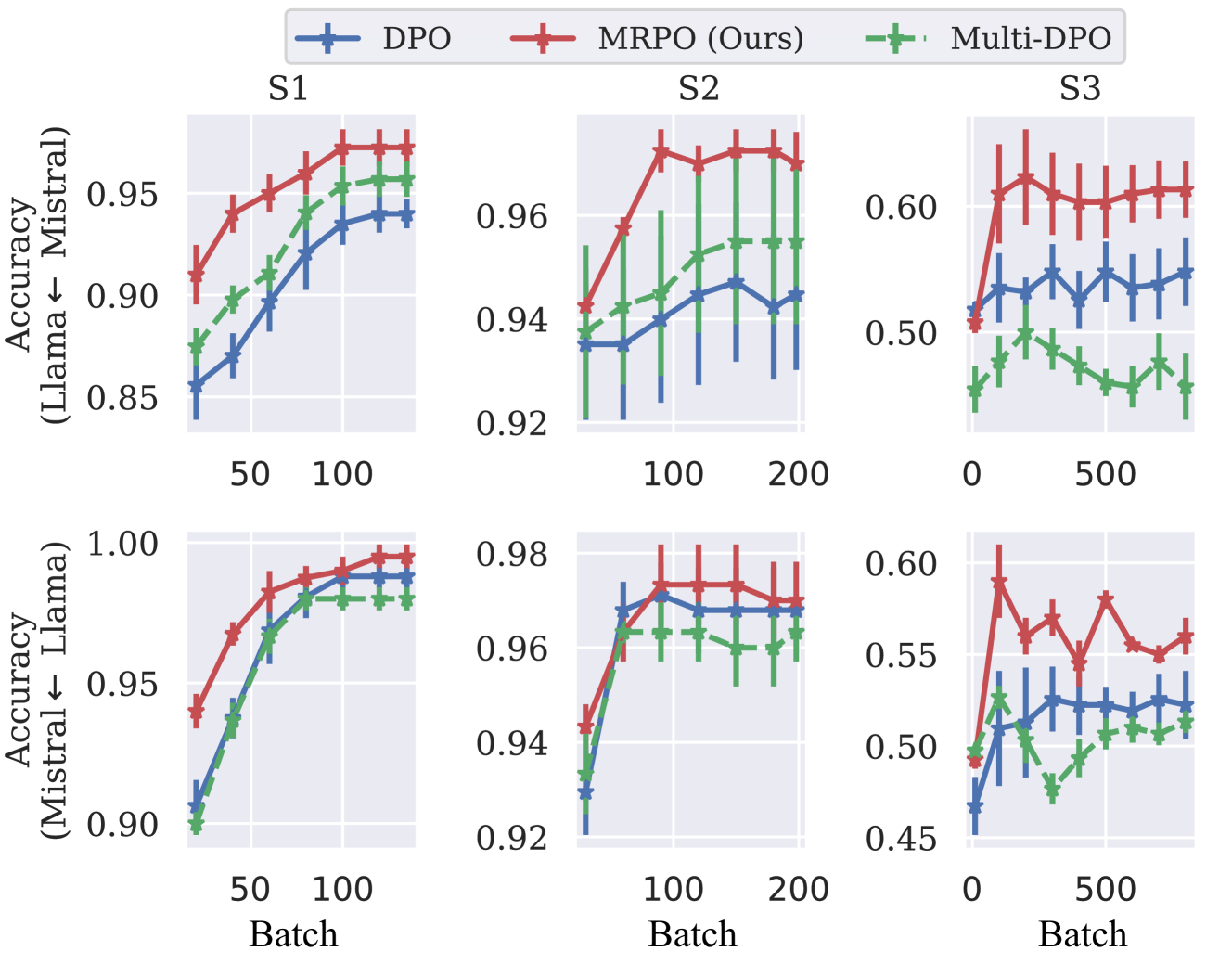
How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.
Create account to get full access
Overview
- This paper introduces a novel approach called Multi-Reference Preference Optimization (MRPO) for fine-tuning large language models to better align with user preferences.
- The key idea is to leverage multiple reference models, each representing a different set of preferences, to guide the fine-tuning process and learn a more personalized language model.
- The authors demonstrate the effectiveness of MRPO on various tasks, including text ranking, preference learning, and direct preference optimization.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful tools that can generate human-like text on a wide range of topics. However, these models are often trained on broad datasets and may not align well with the specific preferences and needs of individual users.
The authors of this paper propose a new approach called Multi-Reference Preference Optimization (MRPO) to fine-tune LLMs to better match a user's preferences. The key idea is to use multiple "reference models" during the fine-tuning process, each representing a different set of preferences. For example, one reference model might represent the preferences of a creative writer, while another might represent the preferences of a scientist.
By incorporating these diverse reference models, the fine-tuned LLM can learn to generate text that is more personalized and aligned with the user's specific needs and preferences. This could be particularly useful for tasks like personalized text ranking, where the model needs to understand the user's preferences to provide relevant and engaging content.
The authors demonstrate the effectiveness of MRPO on a variety of tasks, showing that it can outperform traditional fine-tuning approaches and lead to better alignment between the language model and the user's preferences.
Technical Explanation
The paper introduces a novel approach called Multi-Reference Preference Optimization (MRPO) for fine-tuning large language models to better align with user preferences. The key idea is to leverage multiple "reference models" during the fine-tuning process, each representing a different set of preferences.
The authors formulate the fine-tuning problem as a multi-task learning problem, where the model is trained to simultaneously match the preferences of multiple reference models. This is achieved by defining a loss function that encourages the model to generate text that is preferred by each of the reference models.
The authors explore several variants of MRPO, including token-level direct preference optimization and triple preference optimization, which aim to directly optimize the model's preference alignment with the reference models.
The authors conduct extensive experiments on a range of tasks, including text ranking, preference learning, and direct preference optimization. The results demonstrate the effectiveness of MRPO in improving the alignment between the fine-tuned language model and the user's preferences, outperforming traditional fine-tuning approaches.
Critical Analysis
The paper presents a compelling approach to fine-tuning large language models to better align with user preferences. The use of multiple reference models during the fine-tuning process is a clever idea that allows the model to learn a more personalized representation of language.
One potential limitation of the approach is the requirement to have access to multiple reference models, each representing a different set of preferences. In practice, it may be challenging to obtain or construct these reference models, especially for niche or specialized domains.
Additionally, the authors do not discuss the potential for unobserved preference heterogeneity within the reference models themselves. This could be an important consideration, as individual preferences may not be fully captured by the reference models.
Further research could explore ways to learn the reference models more effectively, potentially by incorporating user feedback or other sources of preference information. Investigating the robustness of MRPO to variations in the reference models would also be valuable.
Conclusion
This paper introduces a novel approach called Multi-Reference Preference Optimization (MRPO) for fine-tuning large language models to better align with user preferences. By leveraging multiple reference models during the fine-tuning process, the authors demonstrate that LLMs can learn a more personalized representation of language, leading to improved performance on a variety of tasks.
The core idea of MRPO has the potential to significantly advance the field of personalized language modeling, opening up new opportunities for more tailored and engaging language-based applications. As the authors have shown, this approach can lead to better text ranking, preference learning, and direct preference optimization, among other applications.
While the paper presents a promising solution, there are still areas for further research, such as addressing the challenges of obtaining and curating the reference models. Overall, the MRPO approach represents an important step towards developing large language models that are better aligned with the needs and preferences of individual users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Finetuning Large Language Model for Personalized Ranking
Zhuoxi Bai, Ning Wu, Fengyu Cai, Xinyi Zhu, Yun Xiong
0
0
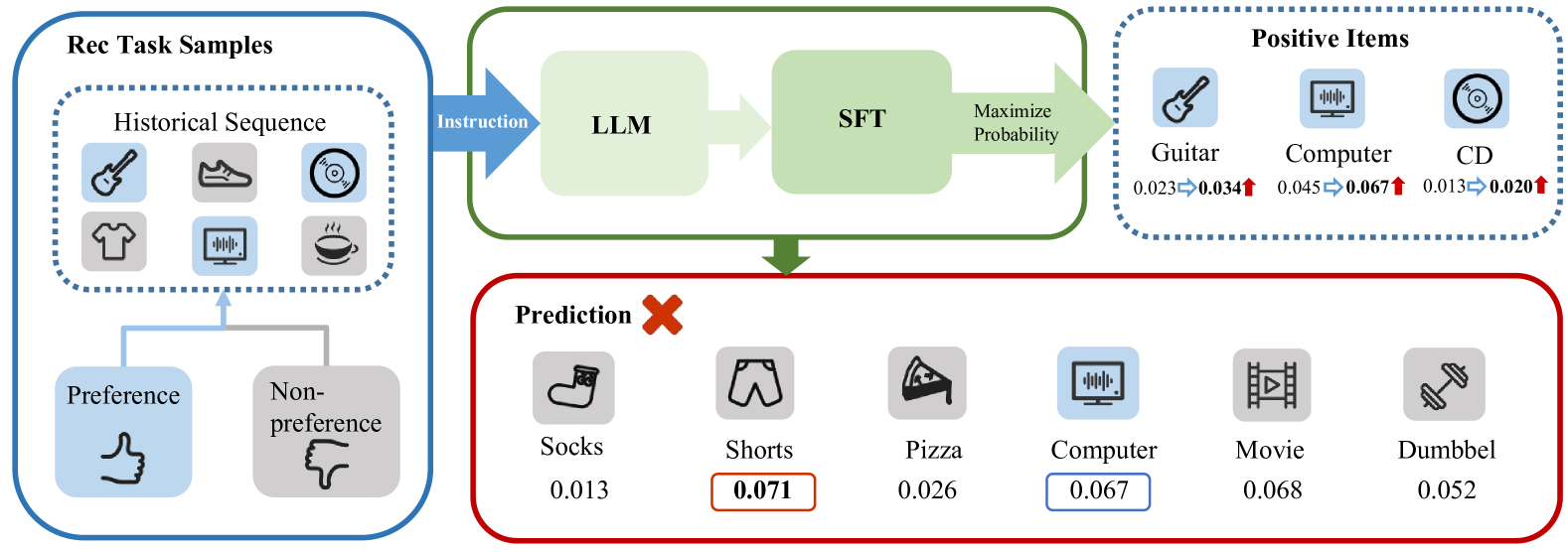
Large Language Models (LLMs) have demonstrated remarkable performance across various domains, motivating researchers to investigate their potential use in recommendation systems. However, directly applying LLMs to recommendation tasks has proven challenging due to the significant disparity between the data used for pre-training LLMs and the specific requirements of recommendation tasks. In this study, we introduce Direct Multi-Preference Optimization (DMPO), a streamlined framework designed to bridge the gap and enhance the alignment of LLMs for recommendation tasks. DMPO enhances the performance of LLM-based recommenders by simultaneously maximizing the probability of positive samples and minimizing the probability of multiple negative samples. We conducted experimental evaluations to compare DMPO against traditional recommendation methods and other LLM-based recommendation approaches. The results demonstrate that DMPO significantly improves the recommendation capabilities of LLMs across three real-world public datasets in few-shot scenarios. Additionally, the experiments indicate that DMPO exhibits superior generalization ability in cross-domain recommendations. A case study elucidates the reasons behind these consistent improvements and also underscores DMPO's potential as an explainable recommendation system.
6/21/2024
Triple Preference Optimization: Achieving Better Alignment with Less Data in a Single Step Optimization
Amir Saeidi, Shivanshu Verma, Aswin RRV, Chitta Baral
0
0
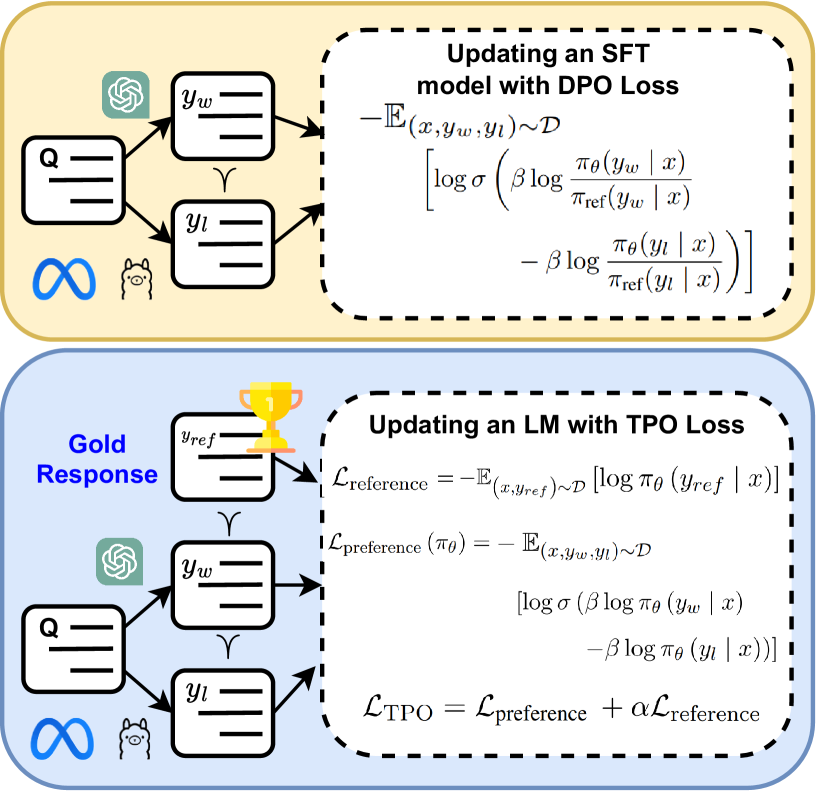
Large Language Models (LLMs) perform well across diverse tasks, but aligning them with human demonstrations is challenging. Recently, Reinforcement Learning (RL)-free methods like Direct Preference Optimization (DPO) have emerged, offering improved stability and scalability while retaining competitive performance relative to RL-based methods. However, while RL-free methods deliver satisfactory performance, they require significant data to develop a robust Supervised Fine-Tuned (SFT) model and an additional step to fine-tune this model on a preference dataset, which constrains their utility and scalability. In this paper, we introduce Triple Preference Optimization (TPO), a new preference learning method designed to align an LLM with three preferences without requiring a separate SFT step and using considerably less data. Through a combination of practical experiments and theoretical analysis, we show the efficacy of TPO as a single-step alignment strategy. Specifically, we fine-tuned the Phi-2 (2.7B) and Mistral (7B) models using TPO directly on the UltraFeedback dataset, achieving superior results compared to models aligned through other methods such as SFT, DPO, KTO, IPO, CPO, and ORPO. Moreover, the performance of TPO without the SFT component led to notable improvements in the MT-Bench score, with increases of +1.27 and +0.63 over SFT and DPO, respectively. Additionally, TPO showed higher average accuracy, surpassing DPO and SFT by 4.2% and 4.97% on the Open LLM Leaderboard benchmarks. Our code is publicly available at https://github.com/sahsaeedi/triple-preference-optimization .
5/28/2024

mDPO: Conditional Preference Optimization for Multimodal Large Language Models
Fei Wang, Wenxuan Zhou, James Y. Huang, Nan Xu, Sheng Zhang, Hoifung Poon, Muhao Chen
0
0
Direct preference optimization (DPO) has shown to be an effective method for large language model (LLM) alignment. Recent works have attempted to apply DPO to multimodal scenarios but have found it challenging to achieve consistent improvement. Through a comparative experiment, we identify the unconditional preference problem in multimodal preference optimization, where the model overlooks the image condition. To address this problem, we propose mDPO, a multimodal DPO objective that prevents the over-prioritization of language-only preferences by also optimizing image preference. Moreover, we introduce a reward anchor that forces the reward to be positive for chosen responses, thereby avoiding the decrease in their likelihood -- an intrinsic problem of relative preference optimization. Experiments on two multimodal LLMs of different sizes and three widely used benchmarks demonstrate that mDPO effectively addresses the unconditional preference problem in multimodal preference optimization and significantly improves model performance, particularly in reducing hallucination.
6/18/2024

Optimizing Language Models for Human Preferences is a Causal Inference Problem
Victoria Lin, Eli Ben-Michael, Louis-Philippe Morency
0
0
As large language models (LLMs) see greater use in academic and commercial settings, there is increasing interest in methods that allow language models to generate texts aligned with human preferences. In this paper, we present an initial exploration of language model optimization for human preferences from direct outcome datasets, where each sample consists of a text and an associated numerical outcome measuring the reader's response. We first propose that language model optimization should be viewed as a causal problem to ensure that the model correctly learns the relationship between the text and the outcome. We formalize this causal language optimization problem, and we develop a method--causal preference optimization (CPO)--that solves an unbiased surrogate objective for the problem. We further extend CPO with doubly robust CPO (DR-CPO), which reduces the variance of the surrogate objective while retaining provably strong guarantees on bias. Finally, we empirically demonstrate the effectiveness of (DR-)CPO in optimizing state-of-the-art LLMs for human preferences on direct outcome data, and we validate the robustness of DR-CPO under difficult confounding conditions.
6/7/2024