TruthSR: Trustworthy Sequential Recommender Systems via User-generated Multimodal Content
2404.17238
0
0
📶
Abstract
Sequential recommender systems explore users' preferences and behavioral patterns from their historically generated data. Recently, researchers aim to improve sequential recommendation by utilizing massive user-generated multi-modal content, such as reviews, images, etc. This content often contains inevitable noise. Some studies attempt to reduce noise interference by suppressing cross-modal inconsistent information. However, they could potentially constrain the capturing of personalized user preferences. In addition, it is almost impossible to entirely eliminate noise in diverse user-generated multi-modal content. To solve these problems, we propose a trustworthy sequential recommendation method via noisy user-generated multi-modal content. Specifically, we explicitly capture the consistency and complementarity of user-generated multi-modal content to mitigate noise interference. We also achieve the modeling of the user's multi-modal sequential preferences. In addition, we design a trustworthy decision mechanism that integrates subjective user perspective and objective item perspective to dynamically evaluate the uncertainty of prediction results. Experimental evaluation on four widely-used datasets demonstrates the superior performance of our model compared to state-of-the-art methods. The code is released at https://github.com/FairyMeng/TrustSR.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers are exploring ways to improve sequential recommendation systems by utilizing user-generated multi-modal content (e.g., reviews, images)
- This content often contains noise, and some studies have tried to suppress cross-modal inconsistent information to reduce noise interference
- However, this approach can constrain the capturing of personalized user preferences, and it's challenging to entirely eliminate noise in diverse user-generated content
- The proposed method aims to capture the consistency and complementarity of user-generated multi-modal content to mitigate noise and model users' multi-modal sequential preferences
- It also includes a trustworthy decision mechanism that integrates subjective user perspective and objective item perspective to dynamically evaluate the uncertainty of prediction results
Plain English Explanation
Sequential recommendation systems learn user preferences and behaviors from their past interactions to suggest relevant items. Researchers are now looking to improve these systems by incorporating additional user-generated content, such as reviews and images.
However, this user-generated content often contains noise, which can interfere with accurately capturing a user's preferences. Some studies have tried to address this by suppressing information that is inconsistent across different content types. But this approach risks limiting the system's ability to understand the user's unique preferences.
Additionally, it's extremely difficult to completely remove all noise from diverse user-generated content. To solve these problems, the researchers propose a new method that explicitly captures the consistency and complementarity of the multi-modal content. This helps mitigate the noise while still allowing the system to model the user's preferences across different content types.
The method also includes a "trustworthy" decision mechanism that considers both the user's perspective and the item's characteristics to dynamically evaluate the uncertainty of the recommendation predictions. This helps ensure the recommendations are reliable and tailored to the individual user.
Technical Explanation
The proposed "trustworthy sequential recommendation" method has several key components:
-
Multi-Modal Content Modeling: The system explicitly captures the consistency and complementarity of user-generated multi-modal content (e.g., reviews, images) to mitigate noise interference. This allows it to effectively model the user's multi-modal sequential preferences.
-
Trustworthy Decision Mechanism: The method integrates the subjective user perspective and the objective item perspective to dynamically evaluate the uncertainty of the prediction results. This helps ensure the recommendations are reliable and personalized for each user.
The researchers evaluated their model on four widely-used datasets and found it outperformed state-of-the-art sequential recommendation approaches. The code for the method is publicly available.
Critical Analysis
The researchers acknowledge that it is almost impossible to entirely eliminate noise from diverse user-generated multi-modal content. While their proposed method aims to mitigate the noise interference, it is unclear how effective it is at handling extreme levels of noise or particularly complex user-item interactions.
Additionally, the trustworthy decision mechanism, while a promising approach, relies on integrating both user and item perspectives. The paper does not provide a detailed explanation of how these perspectives are quantified and balanced, which could be an area for further investigation.
Lastly, the experimental evaluation, while comprehensive, was conducted on relatively standard datasets. Applying the method to more diverse or real-world scenarios may reveal additional challenges or limitations that were not addressed in this research.
Conclusion
This study presents a novel approach to sequential recommendation that leverages user-generated multi-modal content while addressing the challenges of noise interference. By explicitly modeling the consistency and complementarity of the content, the method is able to capture personalized user preferences more effectively than traditional techniques.
The inclusion of a trustworthy decision mechanism is a promising step towards developing more reliable and transparent recommendation systems. As user-generated data continues to proliferate, approaches like this that can extract valuable insights while mitigating noise will become increasingly important for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Multimodal Pretraining and Generation for Recommendation: A Tutorial
Jieming Zhu, Chuhan Wu, Rui Zhang, Zhenhua Dong
0
0
Personalized recommendation stands as a ubiquitous channel for users to explore information or items aligned with their interests. Nevertheless, prevailing recommendation models predominantly rely on unique IDs and categorical features for user-item matching. While this ID-centric approach has witnessed considerable success, it falls short in comprehensively grasping the essence of raw item contents across diverse modalities, such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, particularly in the realm of multimedia services like news, music, and short-video platforms. The recent surge in pretraining and generation techniques presents both opportunities and challenges in the development of multimodal recommender systems. This tutorial seeks to provide a thorough exploration of the latest advancements and future trajectories in multimodal pretraining and generation techniques within the realm of recommender systems. The tutorial comprises three parts: multimodal pretraining, multimodal generation, and industrial applications and open challenges in the field of recommendation. Our target audience encompasses scholars, practitioners, and other parties interested in this domain. By providing a succinct overview of the field, we aspire to facilitate a swift understanding of multimodal recommendation and foster meaningful discussions on the future development of this evolving landscape.
5/14/2024
🤿
Formalizing Multimedia Recommendation through Multimodal Deep Learning
Daniele Malitesta, Giandomenico Cornacchia, Claudio Pomo, Felice Antonio Merra, Tommaso Di Noia, Eugenio Di Sciascio
0
0
Recommender systems (RSs) offer personalized navigation experiences on online platforms, but recommendation remains a challenging task, particularly in specific scenarios and domains. Multimodality can help tap into richer information sources and construct more refined user/item profiles for recommendations. However, existing literature lacks a shared and universal schema for modeling and solving the recommendation problem through the lens of multimodality. This work aims to formalize a general multimodal schema for multimedia recommendation. It provides a comprehensive literature review of multimodal approaches for multimedia recommendation from the last eight years, outlines the theoretical foundations of a multimodal pipeline, and demonstrates its rationale by applying it to selected state-of-the-art approaches. The work also conducts a benchmarking analysis of recent algorithms for multimedia recommendation within Elliot, a rigorous framework for evaluating recommender systems. The main aim is to provide guidelines for designing and implementing the next generation of multimodal approaches in multimedia recommendation.
4/30/2024
Dataset and Models for Item Recommendation Using Multi-Modal User Interactions
Simone Borg Bruun, Krisztian Balog, Maria Maistro
0
0
While recommender systems with multi-modal item representations (image, audio, and text), have been widely explored, learning recommendations from multi-modal user interactions (e.g., clicks and speech) remains an open problem. We study the case of multi-modal user interactions in a setting where users engage with a service provider through multiple channels (website and call center). In such cases, incomplete modalities naturally occur, since not all users interact through all the available channels. To address these challenges, we publish a real-world dataset that allows progress in this under-researched area. We further present and benchmark various methods for leveraging multi-modal user interactions for item recommendations, and propose a novel approach that specifically deals with missing modalities by mapping user interactions to a common feature space. Our analysis reveals important interactions between the different modalities and that a frequently occurring modality can enhance learning from a less frequent one.
5/8/2024
Sequential Recommendation for Optimizing Both Immediate Feedback and Long-term Retention
Ziru Liu, Shuchang Liu, Zijian Zhang, Qingpeng Cai, Xiangyu Zhao, Kesen Zhao, Lantao Hu, Peng Jiang, Kun Gai
0
0
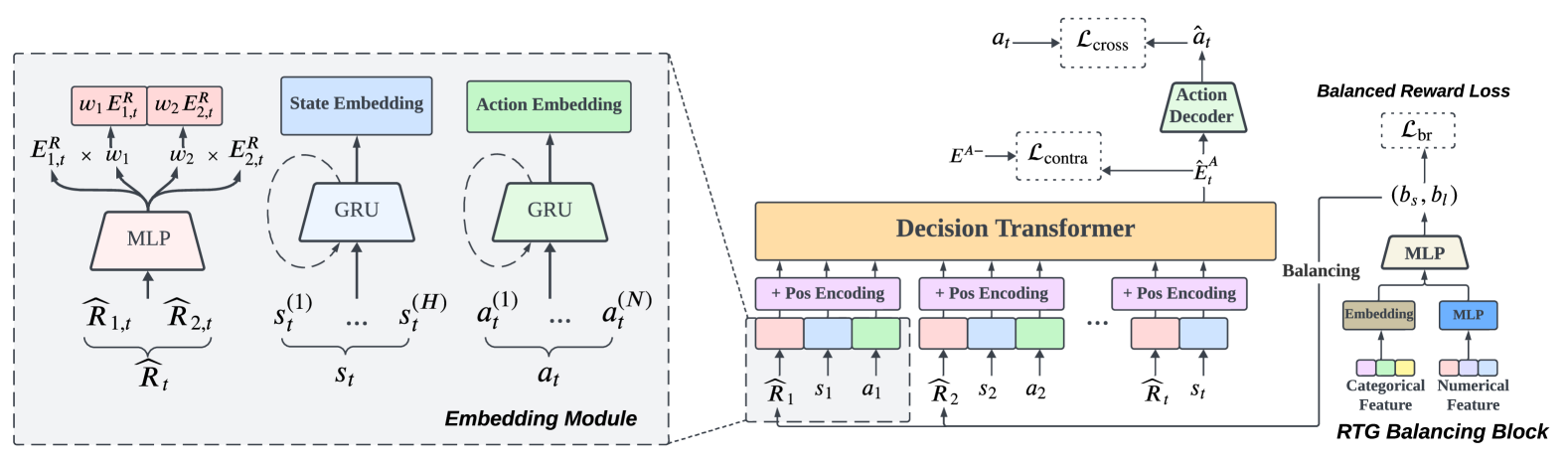
In the landscape of Recommender System (RS) applications, reinforcement learning (RL) has recently emerged as a powerful tool, primarily due to its proficiency in optimizing long-term rewards. Nevertheless, it suffers from instability in the learning process, stemming from the intricate interactions among bootstrapping, off-policy training, and function approximation. Moreover, in multi-reward recommendation scenarios, designing a proper reward setting that reconciles the inner dynamics of various tasks is quite intricate. In response to these challenges, we introduce DT4IER, an advanced decision transformer-based recommendation model that is engineered to not only elevate the effectiveness of recommendations but also to achieve a harmonious balance between immediate user engagement and long-term retention. The DT4IER applies an innovative multi-reward design that adeptly balances short and long-term rewards with user-specific attributes, which serve to enhance the contextual richness of the reward sequence ensuring a more informed and personalized recommendation process. To enhance its predictive capabilities, DT4IER incorporates a high-dimensional encoder, skillfully designed to identify and leverage the intricate interrelations across diverse tasks. Furthermore, we integrate a contrastive learning approach within the action embedding predictions, a strategy that significantly boosts the model's overall performance. Experiments on three real-world datasets demonstrate the effectiveness of DT4IER against state-of-the-art Sequential Recommender Systems (SRSs) and Multi-Task Learning (MTL) models in terms of both prediction accuracy and effectiveness in specific tasks. The source code is accessible online to facilitate replication
4/5/2024