TTT-Unet: Enhancing U-Net with Test-Time Training Layers for biomedical image segmentation

0

Sign in to get full access
Overview
- The paper proposes a new model called TTT-Unet, which enhances the popular U-Net architecture for biomedical image segmentation.
- The key idea is to add "test-time training" (TTT) layers to U-Net, which can be fine-tuned on test images during inference to improve performance.
- Experiments show TTT-Unet outperforms standard U-Net on several biomedical segmentation tasks.
Plain English Explanation
The paper introduces a new deep learning model called TTT-Unet that builds on the popular U-Net architecture for biomedical image segmentation. U-Net is a widely used model that has achieved impressive results, but the authors wanted to see if they could make it even better.
The key innovation in TTT-Unet is the addition of "test-time training" (TTT) layers. These are extra layers that get added on top of the standard U-Net model. During the normal training process, the whole TTT-Unet model is trained end-to-end. But then, when you use the model to make predictions on new test images, the TTT layers can be quickly fine-tuned or "adapted" to the specific characteristics of those test images.
The authors hypothesized that this extra adaptation step would allow TTT-Unet to achieve better performance than standard U-Net, especially on challenging biomedical segmentation tasks where the test images may look quite different from the training data. And their experiments showed that TTT-Unet did indeed outperform U-Net on several benchmark datasets.
So in summary, the main contribution of this paper is a new deep learning architecture called TTT-Unet that leverages test-time training to enhance the popular U-Net model for biomedical image segmentation. The authors demonstrate that this approach can lead to improved performance compared to the standard U-Net.
Technical Explanation
The paper proposes a new model called TTT-Unet that builds on the U-Net architecture for biomedical image segmentation. U-Net is a widely used convolutional neural network (CNN) that has achieved state-of-the-art results on many biomedical image segmentation tasks.
The key innovation in TTT-Unet is the addition of "test-time training" (TTT) layers on top of the standard U-Net model. These extra layers can be quickly fine-tuned or "adapted" to the specific characteristics of the test images during inference, in addition to the normal end-to-end training of the whole model.
Specifically, the TTT layers consist of a small number of convolutional and pooling layers that take the features from the U-Net encoder as input and produce a segmentation map as output. During training, the TTT layers are trained jointly with the rest of the U-Net model. But at test time, the TTT layers can be further optimized (using gradient descent on the test images) to improve the segmentation performance for those specific test cases.
The authors hypothesized that this extra adaptation step would allow TTT-Unet to achieve better performance than standard U-Net, especially on challenging biomedical segmentation tasks where the test images may look quite different from the training data. Their experiments on multiple biomedical datasets showed that TTT-Unet consistently outperformed the standard U-Net model in terms of segmentation accuracy.
Critical Analysis
The paper makes a compelling case for the effectiveness of the TTT-Unet model, demonstrating its superior performance over standard U-Net on several challenging biomedical image segmentation tasks. However, there are a few potential limitations and areas for further research that could be explored:
-
Computational Overhead: The addition of the TTT layers and the need to fine-tune them at test time may incur some computational overhead compared to the simpler U-Net model. The authors do not provide detailed benchmarks on the inference speed or memory usage of TTT-Unet, which would be helpful to understand the practical tradeoffs.
-
Generalization to Other Domains: The paper focuses solely on biomedical image segmentation, leaving open the question of whether the TTT-Unet approach can be effectively applied to other image segmentation domains beyond healthcare. Further research would be needed to assess its generalizability.
-
Interpretability: As with many deep learning models, the internal workings of TTT-Unet may be difficult to interpret. It would be interesting to see if any analysis could be done to understand how the TTT layers are able to adapt the model to the test data and what specific features or patterns they are leveraging.
-
Real-World Deployment: The paper evaluates TTT-Unet on standard benchmark datasets, but real-world biomedical imaging applications may introduce additional challenges such as noisy, incomplete, or domain-shifted data. Further research would be needed to assess the model's robustness and practical feasibility in such settings.
Overall, the TTT-Unet model presented in this paper represents an interesting and promising approach to enhancing the popular U-Net architecture for biomedical image segmentation. While the results are compelling, the above considerations suggest there are still opportunities to further develop and rigorously evaluate the TTT-Unet concept.
Conclusion
In this paper, the authors have proposed a new deep learning model called TTT-Unet that builds on the U-Net architecture for biomedical image segmentation. The key innovation is the addition of "test-time training" (TTT) layers that can be fine-tuned on the test images during inference to improve performance.
The authors' experiments demonstrate that TTT-Unet consistently outperforms the standard U-Net model across multiple biomedical image segmentation benchmarks. This suggests the TTT approach is an effective way to enhance the capabilities of U-Net, particularly for challenging tasks where the test data may differ significantly from the training distribution.
While the paper makes a strong case for the TTT-Unet model, there are still some open questions and potential limitations that warrant further exploration, such as the computational overhead, generalizability to other domains, interpretability, and real-world deployment challenges. Nonetheless, this work represents an interesting and promising contribution to the field of biomedical image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!TTT-Unet: Enhancing U-Net with Test-Time Training Layers for biomedical image segmentation
Rong Zhou, Zhengqing Yuan, Zhiling Yan, Weixiang Sun, Kai Zhang, Yiwei Li, Yanfang Ye, Xiang Li, Lifang He, Lichao Sun
Biomedical image segmentation is crucial for accurately diagnosing and analyzing various diseases. However, Convolutional Neural Networks (CNNs) and Transformers, the most commonly used architectures for this task, struggle to effectively capture long-range dependencies due to the inherent locality of CNNs and the computational complexity of Transformers. To address this limitation, we introduce TTT-Unet, a novel framework that integrates Test-Time Training (TTT) layers into the traditional U-Net architecture for biomedical image segmentation. TTT-Unet dynamically adjusts model parameters during the testing time, enhancing the model's ability to capture both local and long-range features. We evaluate TTT-Unet on multiple medical imaging datasets, including 3D abdominal organ segmentation in CT and MR images, instrument segmentation in endoscopy images, and cell segmentation in microscopy images. The results demonstrate that TTT-Unet consistently outperforms state-of-the-art CNN-based and Transformer-based segmentation models across all tasks. The code is available at https://github.com/rongzhou7/TTT-Unet.
Read more9/20/2024

0
TBConvL-Net: A Hybrid Deep Learning Architecture for Robust Medical Image Segmentation
Shahzaib Iqbal, Tariq M. Khan, Syed S. Naqvi, Asim Naveed, Erik Meijering
Deep learning has shown great potential for automated medical image segmentation to improve the precision and speed of disease diagnostics. However, the task presents significant difficulties due to variations in the scale, shape, texture, and contrast of the pathologies. Traditional convolutional neural network (CNN) models have certain limitations when it comes to effectively modelling multiscale context information and facilitating information interaction between skip connections across levels. To overcome these limitations, a novel deep learning architecture is introduced for medical image segmentation, taking advantage of CNNs and vision transformers. Our proposed model, named TBConvL-Net, involves a hybrid network that combines the local features of a CNN encoder-decoder architecture with long-range and temporal dependencies using biconvolutional long-short-term memory (LSTM) networks and vision transformers (ViT). This enables the model to capture contextual channel relationships in the data and account for the uncertainty of segmentation over time. Additionally, we introduce a novel composite loss function that considers both the segmentation robustness and the boundary agreement of the predicted output with the gold standard. Our proposed model shows consistent improvement over the state of the art on ten publicly available datasets of seven different medical imaging modalities.
Read more9/6/2024
🌐
0
GCtx-UNet: Efficient Network for Medical Image Segmentation
Khaled Alrfou, Tian Zhao
Medical image segmentation is crucial for disease diagnosis and monitoring. Though effective, the current segmentation networks such as UNet struggle with capturing long-range features. More accurate models such as TransUNet, Swin-UNet, and CS-UNet have higher computation complexity. To address this problem, we propose GCtx-UNet, a lightweight segmentation architecture that can capture global and local image features with accuracy better or comparable to the state-of-the-art approaches. GCtx-UNet uses vision transformer that leverages global context self-attention modules joined with local self-attention to model long and short range spatial dependencies. GCtx-UNet is evaluated on the Synapse multi-organ abdominal CT dataset, the ACDC cardiac MRI dataset, and several polyp segmentation datasets. In terms of Dice Similarity Coefficient (DSC) and Hausdorff Distance (HD) metrics, GCtx-UNet outperformed CNN-based and Transformer-based approaches, with notable gains in the segmentation of complex and small anatomical structures. Moreover, GCtx-UNet is much more efficient than the state-of-the-art approaches with smaller model size, lower computation workload, and faster training and inference speed, making it a practical choice for clinical applications.
Read more6/11/2024
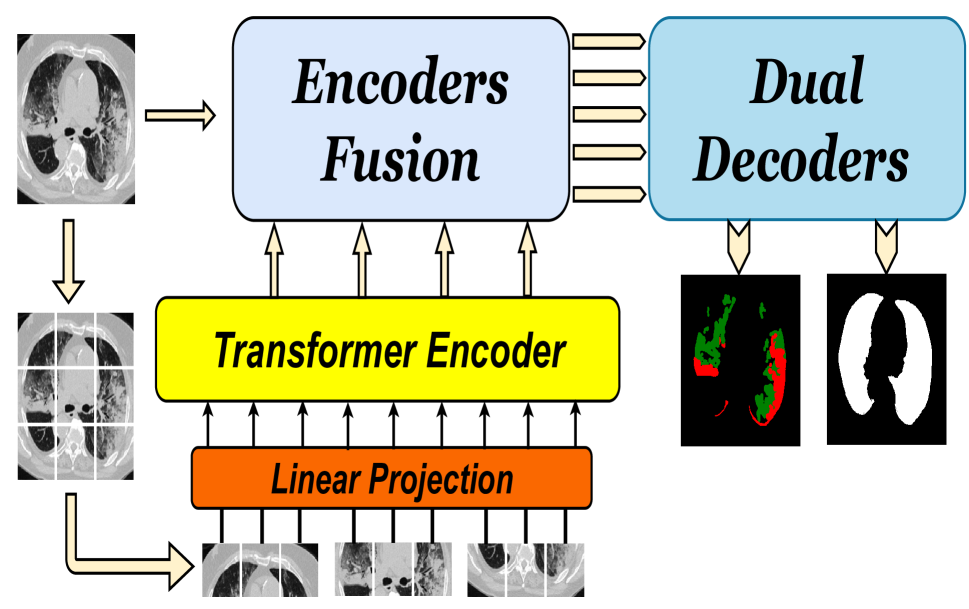
0
D-TrAttUnet: Toward Hybrid CNN-Transformer Architecture for Generic and Subtle Segmentation in Medical Images
Fares Bougourzi, Fadi Dornaika, Cosimo Distante, Abdelmalik Taleb-Ahmed
Over the past two decades, machine analysis of medical imaging has advanced rapidly, opening up significant potential for several important medical applications. As complicated diseases increase and the number of cases rises, the role of machine-based imaging analysis has become indispensable. It serves as both a tool and an assistant to medical experts, providing valuable insights and guidance. A particularly challenging task in this area is lesion segmentation, a task that is challenging even for experienced radiologists. The complexity of this task highlights the urgent need for robust machine learning approaches to support medical staff. In response, we present our novel solution: the D-TrAttUnet architecture. This framework is based on the observation that different diseases often target specific organs. Our architecture includes an encoder-decoder structure with a composite Transformer-CNN encoder and dual decoders. The encoder includes two paths: the Transformer path and the Encoders Fusion Module path. The Dual-Decoder configuration uses two identical decoders, each with attention gates. This allows the model to simultaneously segment lesions and organs and integrate their segmentation losses. To validate our approach, we performed evaluations on the Covid-19 and Bone Metastasis segmentation tasks. We also investigated the adaptability of the model by testing it without the second decoder in the segmentation of glands and nuclei. The results confirmed the superiority of our approach, especially in Covid-19 infections and the segmentation of bone metastases. In addition, the hybrid encoder showed exceptional performance in the segmentation of glands and nuclei, solidifying its role in modern medical image analysis.
Read more5/8/2024