Turning Text and Imagery into Captivating Visual Video
2406.01851
0
0

Abstract
The ability to visualize a structure from multiple perspectives is crucial for comprehensive planning and presentation. This paper introduces an advanced application of generative models, akin to Stable Video Diffusion, tailored for architectural visualization. We explore the potential of these models to create consistent multi-perspective videos of buildings from single images and to generate design videos directly from textual descriptions. The proposed method enhances the design process by offering rapid prototyping, cost and time efficiency, and an enriched creative space for architects and designers. By harnessing the power of AI, our approach not only accelerates the visualization of architectural concepts but also enables a more interactive and immersive experience for clients and stakeholders. This advancement in architectural visualization represents a significant leap forward, allowing for a deeper exploration of design possibilities and a more effective communication of complex architectural ideas.
Create account to get full access
Overview
- This paper presents a novel approach for turning text and imagery into captivating visual videos.
- The proposed system leverages language models and diffusion models to generate visual narratives from textual inputs.
- Key innovations include a multi-modal fusion module and a novel video rendering pipeline that can produce high-quality, dynamic video outputs.
Plain English Explanation
The researchers have developed a system that can take textual descriptions and turn them into engaging, animated videos. This is achieved by combining language models, which are good at understanding and generating human-like text, with diffusion models, which are powerful at creating images from scratch.
The core idea is to first encode the input text into a rich semantic representation using a language model. This representation is then fused with visual features extracted from reference images, allowing the system to ground the text in relevant visual information. A novel video rendering pipeline is then used to translate this multimodal representation into a coherent, dynamic video sequence.
This approach enables the system to produce visually captivating videos that closely align with the input text. It could be particularly useful for applications like From Text to Blueprint: Leveraging Text to Generate 3D Building Designs, Sketch to Architecture: Generative AI-Aided Architectural Design, or Towards Multi-Task, Multi-Modal Models for Video Generation, where textual descriptions can be transformed into visual outputs.
Technical Explanation
The proposed system consists of several key components. First, a language model is used to encode the input text into a rich semantic representation. This representation is then fused with visual features extracted from reference images using a multimodal fusion module. The fused representation is then passed through a video rendering pipeline that generates the final video sequence.
The video rendering pipeline is a novel contribution of this work. It uses a combination of diffusion models and other generative techniques to translate the multimodal representation into a cohesive, dynamic video. This includes generating individual video frames, as well as modeling temporal transitions and camera motions to create a visually compelling output.
The researchers conduct extensive experiments to evaluate the performance of their system, including comparisons to state-of-the-art text-to-image and video generation models. They demonstrate the system's ability to produce high-quality videos that closely match the input text, including capturing intricate details and complex narratives.
Critical Analysis
The researchers acknowledge several limitations of their approach. For example, the system may struggle with generating videos for highly abstract or complex textual descriptions, and the video quality is still not on par with professional-grade productions. Additionally, the system relies on reference images, which may not always be available or relevant to the input text.
Further research could explore ways to improve the system's ability to handle more challenging textual inputs, as well as investigate methods for generating video content without the need for reference images. Additionally, the integration of this technology with real-world applications, such as Exploring Text-Based Realistic Building Facades Editing or Unified Editing of Panorama 3D Scenes and Videos through Text, could yield valuable insights and drive further advancements in the field.
Conclusion
This paper presents a novel approach for turning text and imagery into captivating visual videos. By leveraging language models and diffusion models, the researchers have developed a system that can generate high-quality, dynamic video outputs from textual descriptions. While the system has some limitations, it represents an exciting step forward in the field of multimodal generation and could have a significant impact on applications where textual inputs need to be translated into engaging visual narratives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

From Text to Blueprint: Leveraging Text-to-Image Tools for Floor Plan Creation
Xiaoyu Li, Jonathan Benjamin, Xin Zhang
0
0
Artificial intelligence is revolutionizing architecture through text-to-image synthesis, converting textual descriptions into detailed visual representations. We explore AI-assisted floor plan design, focusing on technical background, practical methods, and future directions. Using tools like, Stable Diffusion, AI leverages models such as Generative Adversarial Networks and Variational Autoencoders to generate complex and functional floorplans designs. We evaluates these AI models' effectiveness in generating residential floor plans from text prompts. Through experiments with reference images, text prompts, and sketches, we assess the strengths and limitations of current text-to-image technology in architectural visualization. Architects can use these AI tools to streamline design processes, create multiple design options, and enhance creativity and collaboration. We highlight AI's potential to drive smarter, more efficient floorplan design, contributing to ongoing discussions on AI integration in the design profession and its future impact.
5/28/2024
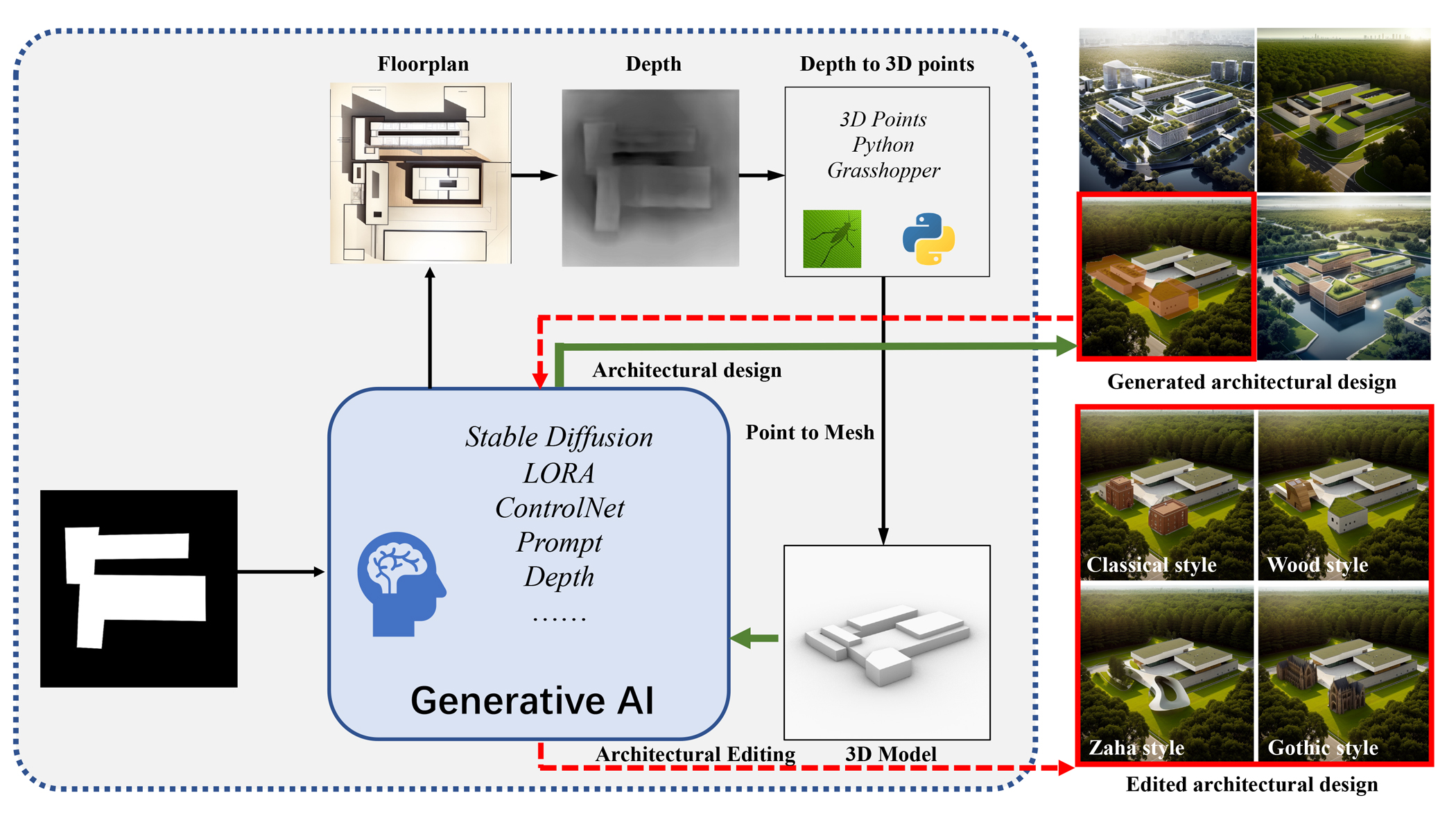
Sketch-to-Architecture: Generative AI-aided Architectural Design
Pengzhi Li, Baijuan Li, Zhiheng Li
0
0
Recently, the development of large-scale models has paved the way for various interdisciplinary research, including architecture. By using generative AI, we present a novel workflow that utilizes AI models to generate conceptual floorplans and 3D models from simple sketches, enabling rapid ideation and controlled generation of architectural renderings based on textual descriptions. Our work demonstrates the potential of generative AI in the architectural design process, pointing towards a new direction of computer-aided architectural design. Our project website is available at: https://zrealli.github.io/sketch2arc
4/1/2024

Exploring Text-based Realistic Building Facades Editing Applicaiton
Jing Wang, Xin Zhang
0
0
This paper explores the utilization of diffusion models and textual guidance for achieving localized editing of building facades, addressing the escalating demand for sophisticated editing methodologies in architectural design and urban planning. Leveraging the robust generative capabilities of diffusion models, this study presents a promising avenue for realistically synthesizing and modifying architectural facades. Through iterative diffusion and text descriptions, these models adeptly capture both the intricate global and local structures inherent in architectural facades, thus effectively navigating the complexity of such designs. Additionally, the paper examines the expansive potential of diffusion models in various facets, including the generation of novel facade designs, the enhancement of existing facades, and the realization of personalized customization. Despite their promise, diffusion models encounter obstacles such as computational resource constraints and data imbalances. To address these challenges, the study introduces the innovative Blended Latent Diffusion method for architectural facade editing, accompanied by a comprehensive visual analysis of its viability and efficacy. Through these endeavors, we aims to propel forward the field of architectural facade editing, contributing to its advancement and practical application.
5/7/2024
🌐
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective
Lijun Yu
0
0
Advancements in language foundation models have primarily fueled the recent surge in artificial intelligence. In contrast, generative learning of non-textual modalities, especially videos, significantly trails behind language modeling. This thesis chronicles our endeavor to build multi-task models for generating videos and other modalities under diverse conditions, as well as for understanding and compression applications. Given the high dimensionality of visual data, we pursue concise and accurate latent representations. Our video-native spatial-temporal tokenizers preserve high fidelity. We unveil a novel approach to mapping bidirectionally between visual observation and interpretable lexical terms. Furthermore, our scalable visual token representation proves beneficial across generation, compression, and understanding tasks. This achievement marks the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs. Within these multi-modal latent spaces, we study the design of multi-task generative models. Our masked multi-task transformer excels at the quality, efficiency, and flexibility of video generation. We enable a frozen language model, trained solely on text, to generate visual content. Finally, we build a scalable generative multi-modal transformer trained from scratch, enabling the generation of videos containing high-fidelity motion with the corresponding audio given diverse conditions. Throughout the course, we have shown the effectiveness of integrating multiple tasks, crafting high-fidelity latent representation, and generating multiple modalities. This work suggests intriguing potential for future exploration in generating non-textual data and enabling real-time, interactive experiences across various media forms.
5/28/2024