Towards Multi-Task Multi-Modal Models: A Video Generative Perspective

0
🌐
Sign in to get full access
Overview
- This paper explores how advancements in language foundation models have driven recent progress in artificial intelligence, while generative learning of non-textual modalities like videos has lagged behind.
- The researchers built multi-task models that can generate videos and other modalities, as well as understand and compress them, using concise and accurate latent representations.
- They developed a novel approach to mapping between visual observations and interpretable lexical terms, and a scalable visual token representation that benefits generation, compression, and understanding tasks.
- The paper presents the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs.
- The researchers explored the design of multi-task generative models, including a masked multi-task transformer that excels at video generation and a scalable generative multi-modal transformer trained from scratch.
Plain English Explanation
The paper describes how recent advancements in language foundation models have fueled progress in artificial intelligence, while generating non-textual content like videos has lagged behind. The researchers developed multi-task models that can create, understand, and compress videos and other modalities using concise and accurate latent representations.
They came up with a new way to connect visual observations with words, and created a flexible visual token representation that helps with generation, compression, and understanding tasks. This allowed them to create language models that outperform state-of-the-art diffusion models at visual synthesis and a video tokenizer that beats industry-standard codecs.
The researchers also explored the design of multi-task generative models, including a transformer that excels at video generation and a scalable model trained from scratch that can generate high-quality videos with corresponding audio.
Overall, this work suggests exciting possibilities for generating non-textual content and enabling interactive experiences across different media formats in the future.
Technical Explanation
The key technical contributions of this paper include:
-
Multi-Task Generative Models: The researchers developed models that can perform a variety of tasks, including generating, understanding, and compressing videos and other modalities. This allowed them to leverage shared representations and achieve better performance across these different capabilities.
-
Concise Latent Representations: Given the high dimensionality of visual data, the researchers pursued compact and accurate latent representations. Their video-native spatial-temporal tokenizers maintained high fidelity, and their scalable visual token representation proved beneficial across generation, compression, and understanding tasks.
-
Bidirectional Mapping of Visual Observations and Lexical Terms: The paper introduces a novel approach to mapping between visual observations and interpretable lexical terms, enabling more intuitive and explainable representations.
-
Language Models Outperforming Diffusion Models: The researchers demonstrated the first instances of language models surpassing diffusion models in visual synthesis, showcasing the potential of language-based approaches for generating non-textual content.
-
Video Tokenizer Outperforming Industry-Standard Codecs: The paper presents a video tokenizer that outperforms industry-standard codecs, suggesting the value of learned token representations for video compression and understanding.
-
Masked Multi-Task Transformer: The researchers developed a transformer-based model that excels at the quality, efficiency, and flexibility of video generation, leveraging a masked multi-task training approach.
-
Scalable Generative Multi-Modal Transformer: The paper also introduces a scalable generative multi-modal transformer trained from scratch, enabling the generation of high-fidelity videos with corresponding audio given diverse conditions.
Critical Analysis
The paper presents impressive technical achievements in developing multi-task generative models that can handle a variety of modalities, particularly the breakthrough in language models outperforming diffusion models for visual synthesis. However, the research also acknowledges several limitations and areas for further exploration:
-
Data and Task Diversity: The experiments focused on a limited set of datasets and tasks, and the researchers suggest expanding to a broader range of non-textual modalities and real-world applications.
-
Computational Efficiency: While the models demonstrated strong performance, the computational requirements for training and inference may still be a barrier for practical deployment, especially for resource-constrained settings.
-
Evaluation Metrics: The paper primarily relies on standard quantitative metrics, but the researchers note the need for more comprehensive and meaningful evaluation methods to assess the quality and usefulness of the generated content.
-
Interpretability and Controllability: The paper touches on the ability to map between visual observations and lexical terms, but further research is needed to improve the interpretability and controllability of the generative models.
-
Safety and Ethical Considerations: As with any powerful generative technology, there are potential concerns around the misuse of these models, such as the creation of fake or deceptive content. The paper does not address these important societal implications.
Overall, this work represents significant progress in multi-modal generative modeling and suggests promising directions for future research. However, continued advancements should be accompanied by careful consideration of the ethical and societal impacts of these technologies.
Conclusion
This paper chronicles a substantial leap forward in the development of multi-task models for generating, understanding, and compressing non-textual modalities, particularly videos. The researchers' key achievements include creating concise and accurate latent representations, a novel approach to mapping between visual observations and lexical terms, and models that outperform state-of-the-art approaches in visual synthesis and video compression.
These advancements mark an important milestone in bridging the gap between language-based and non-textual generative AI, suggesting the potential for more natural and interactive experiences across various media forms. As the field continues to progress, it will be crucial to address the remaining limitations and carefully consider the ethical implications of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective
Lijun Yu
Advancements in language foundation models have primarily fueled the recent surge in artificial intelligence. In contrast, generative learning of non-textual modalities, especially videos, significantly trails behind language modeling. This thesis chronicles our endeavor to build multi-task models for generating videos and other modalities under diverse conditions, as well as for understanding and compression applications. Given the high dimensionality of visual data, we pursue concise and accurate latent representations. Our video-native spatial-temporal tokenizers preserve high fidelity. We unveil a novel approach to mapping bidirectionally between visual observation and interpretable lexical terms. Furthermore, our scalable visual token representation proves beneficial across generation, compression, and understanding tasks. This achievement marks the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs. Within these multi-modal latent spaces, we study the design of multi-task generative models. Our masked multi-task transformer excels at the quality, efficiency, and flexibility of video generation. We enable a frozen language model, trained solely on text, to generate visual content. Finally, we build a scalable generative multi-modal transformer trained from scratch, enabling the generation of videos containing high-fidelity motion with the corresponding audio given diverse conditions. Throughout the course, we have shown the effectiveness of integrating multiple tasks, crafting high-fidelity latent representation, and generating multiple modalities. This work suggests intriguing potential for future exploration in generating non-textual data and enabling real-time, interactive experiences across various media forms.
Read more5/28/2024
3
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
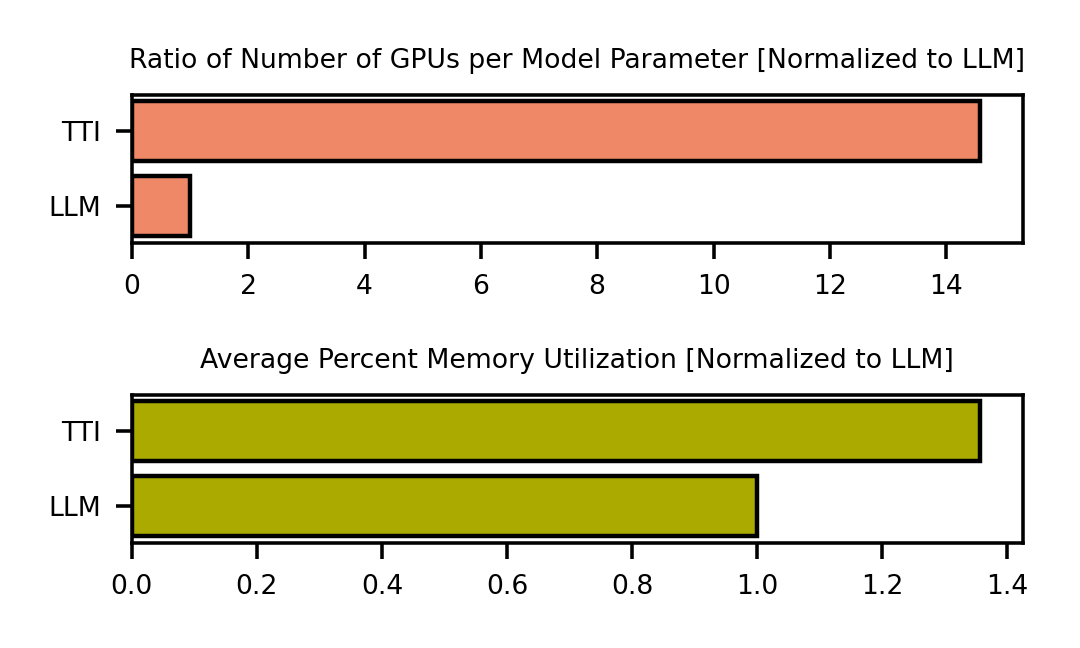
As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
Read more5/7/2024

0
A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
Read more4/3/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024