Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
2405.16823
0
0

Abstract
While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
Create account to get full access
Overview
- This paper presents a novel approach for unified editing of panorama, 3D scenes, and videos using disentangled self-attention injection.
- The proposed method allows for seamless and intuitive editing of various media formats, including panoramic images, 3D scenes, and video, through a single, unified framework.
- The key innovation is the use of disentangled self-attention, which enables the model to learn and manipulate distinct visual and semantic components of the input.
Plain English Explanation
The paper describes a new way to edit different types of media, like panoramic images, 3D scenes, and videos, using a single, unified system. The core idea is to use a special kind of attention mechanism, called "disentangled self-attention," which allows the model to learn and manipulate distinct visual and semantic parts of the input data.
This means you can make edits to things like the objects, lighting, or composition of a panoramic image, a 3D scene, or a video, all using the same editing tools. The disentangled self-attention helps the model understand the different elements of the media so you can make targeted changes, rather than just making broad, global adjustments.
The ability to edit multiple media formats through a single, consistent interface could be very useful for content creators, designers, and others who work with a variety of visual media. It could streamline their workflows and enable more precise, nuanced edits compared to traditional editing tools.
Technical Explanation
The paper introduces a novel framework for unified editing of panorama, 3D scenes, and videos based on disentangled self-attention injection. The key innovation is the use of a disentangled self-attention mechanism, which allows the model to learn and manipulate distinct visual and semantic components of the input.
The proposed architecture takes the input media (panorama, 3D scene, or video) and encodes it using a multi-modal encoder. This encoder leverages disentangled self-attention to extract meaningful visual and semantic features. These features are then passed to a shared editing module, which can perform various editing operations, such as object removal, lighting adjustments, and style transfer, in a unified manner across the different media formats.
The authors demonstrate the effectiveness of their approach through extensive experiments on panoramic images, 3D scenes, and videos. They show that the disentangled self-attention enables more precise and intuitive editing compared to traditional, monolithic editing tools. The framework also exhibits strong generalization capabilities, allowing it to handle a diverse range of input media and editing tasks.
Critical Analysis
The paper presents a compelling solution for unified media editing, addressing an important challenge in the field. The use of disentangled self-attention is a promising approach, as it allows the model to understand and manipulate the distinct visual and semantic components of the input.
However, the paper could have provided more details on the specific architecture and training details of the model, as well as a more thorough evaluation of its limitations and potential failure modes. For example, it would be interesting to see how the model performs on more complex or noisy input data, or how it handles edge cases where the disentanglement of visual and semantic features may be challenging.
Additionally, the paper could have discussed the potential ethical implications of such a powerful media editing tool, particularly in the context of content creation, manipulation, and distribution. As with any advanced AI-powered technology, there are concerns around the potential for misuse or unintended consequences that should be carefully considered.
Conclusion
This paper presents a novel framework for unified editing of panorama, 3D scenes, and videos using disentangled self-attention injection. The key innovation is the use of a disentangled self-attention mechanism, which allows the model to learn and manipulate distinct visual and semantic components of the input media.
The proposed approach offers a flexible and intuitive editing interface that can handle a diverse range of media formats, streamlining the workflows of content creators and designers. The strong experimental results demonstrate the effectiveness of the disentangled self-attention in enabling precise and nuanced edits across panoramic images, 3D scenes, and videos.
While the paper represents an important step forward in unified media editing, further research is needed to address potential limitations and explore the broader implications of such powerful editing capabilities. Nonetheless, this work lays the groundwork for more advanced and accessible media creation and manipulation tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
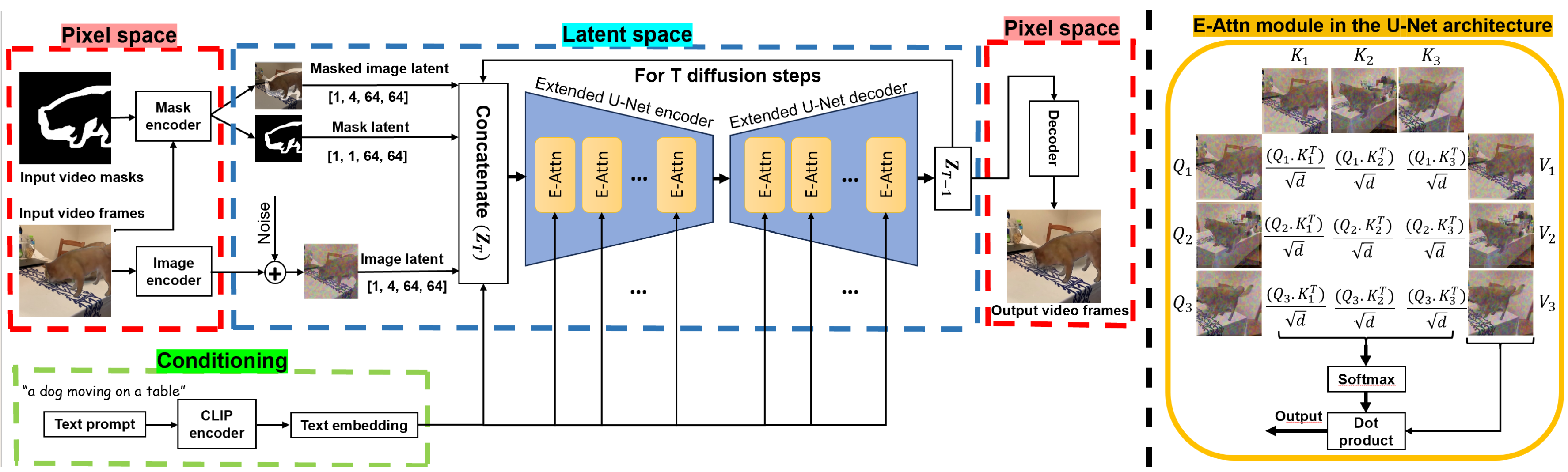
Temporally Consistent Object Editing in Videos using Extended Attention
AmirHossein Zamani, Amir G. Aghdam, Tiberiu Popa, Eugene Belilovsky
0
0
Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
6/4/2024

Investigating the Effectiveness of Cross-Attention to Unlock Zero-Shot Editing of Text-to-Video Diffusion Models
Saman Motamed, Wouter Van Gansbeke, Luc Van Gool
0
0
With recent advances in image and video diffusion models for content creation, a plethora of techniques have been proposed for customizing their generated content. In particular, manipulating the cross-attention layers of Text-to-Image (T2I) diffusion models has shown great promise in controlling the shape and location of objects in the scene. Transferring image-editing techniques to the video domain, however, is extremely challenging as object motion and temporal consistency are difficult to capture accurately. In this work, we take a first look at the role of cross-attention in Text-to-Video (T2V) diffusion models for zero-shot video editing. While one-shot models have shown potential in controlling motion and camera movement, we demonstrate zero-shot control over object shape, position and movement in T2V models. We show that despite the limitations of current T2V models, cross-attention guidance can be a promising approach for editing videos.
4/9/2024

Attention Calibration for Disentangled Text-to-Image Personalization
Yanbing Zhang, Mengping Yang, Qin Zhou, Zhe Wang
0
0
Recent thrilling progress in large-scale text-to-image (T2I) models has unlocked unprecedented synthesis quality of AI-generated content (AIGC) including image generation, 3D and video composition. Further, personalized techniques enable appealing customized production of a novel concept given only several images as reference. However, an intriguing problem persists: Is it possible to capture multiple, novel concepts from one single reference image? In this paper, we identify that existing approaches fail to preserve visual consistency with the reference image and eliminate cross-influence from concepts. To alleviate this, we propose an attention calibration mechanism to improve the concept-level understanding of the T2I model. Specifically, we first introduce new learnable modifiers bound with classes to capture attributes of multiple concepts. Then, the classes are separated and strengthened following the activation of the cross-attention operation, ensuring comprehensive and self-contained concepts. Additionally, we suppress the attention activation of different classes to mitigate mutual influence among concepts. Together, our proposed method, dubbed DisenDiff, can learn disentangled multiple concepts from one single image and produce novel customized images with learned concepts. We demonstrate that our method outperforms the current state of the art in both qualitative and quantitative evaluations. More importantly, our proposed techniques are compatible with LoRA and inpainting pipelines, enabling more interactive experiences.
4/12/2024

A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
0
0
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
6/21/2024