UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised

0

Sign in to get full access
Overview
- UdeerLID+ is a machine learning model that integrates LiDAR, image, and relative depth data for 3D scene understanding.
- It uses a semi-supervised learning approach to leverage both labeled and unlabeled data for improved performance.
- The model aims to advance the state-of-the-art in areas like 3D semantic segmentation and scene understanding.
Plain English Explanation
UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised is a research paper that presents a new machine learning model called UdeerLID+. This model is designed to improve 3D scene understanding, which is the task of analyzing and understanding the three-dimensional information in a given scene, such as the locations and types of objects present.
The key innovation of UdeerLID+ is that it integrates three different types of data: LiDAR (light detection and ranging) data, which provides precise 3D measurements; image data, which gives visual information about the scene; and relative depth data, which indicates the distance between objects. By combining these diverse data sources, the model can gain a more comprehensive understanding of the 3D environment.
Additionally, UdeerLID+ uses a semi-supervised learning approach, which means it can learn from both labeled data (where the correct answers are provided) and unlabeled data (where the answers are not known). This allows the model to leverage a larger amount of available data, which can lead to better performance, especially in situations where labeled data is scarce.
The researchers who developed UdeerLID+ believe that their approach can advance the state-of-the-art in various 3D scene understanding tasks, such as semantic segmentation (where objects are classified into different categories) and scene understanding (where the overall layout and relationships between elements are analyzed). This could have important applications in fields like autonomous vehicles, robotics, and augmented reality.
Technical Explanation
UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised presents a novel model called UdeerLID+ that combines LiDAR, image, and relative depth data for improved 3D scene understanding. The model uses a semi-supervised learning approach to leverage both labeled and unlabeled data, which can lead to better performance, especially in scenarios where labeled data is scarce.
The key components of the UdeerLID+ architecture include:
- LiDAR Encoder: This module processes the 3D point cloud data from the LiDAR sensor to extract relevant features.
- Image Encoder: This module processes the corresponding image data to capture visual information about the scene.
- Relative Depth Encoder: This module processes the relative depth data, which indicates the distances between objects in the scene.
- Multi-Modal Fusion: The features extracted by the three encoders are then combined using a fusion module to integrate the complementary information from the different data sources.
- Semi-Supervised Learning: The model is trained using both labeled and unlabeled data, with the unlabeled data helping to improve the model's generalization capabilities.
The researchers evaluated the performance of UdeerLID+ on several 3D scene understanding tasks, including semantic segmentation and 3D object detection. The results demonstrate that the integration of LiDAR, image, and relative depth data, coupled with the semi-supervised learning approach, can lead to significant improvements over single-modality or fully-supervised approaches.
Critical Analysis
The UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised paper presents a compelling approach for leveraging multimodal data and semi-supervised learning to advance the state-of-the-art in 3D scene understanding. However, the paper also acknowledges several limitations and areas for further research:
- Dataset Size and Diversity: The authors note that the performance of UdeerLID+ is highly dependent on the size and diversity of the training dataset. Larger and more comprehensive datasets may be required to fully showcase the model's capabilities.
- Computational Efficiency: The integration of multiple data modalities and the semi-supervised learning approach may increase the computational complexity of the model, which could limit its real-world deployment, especially in resource-constrained environments like autonomous vehicles.
- Robustness to Sensor Noise and Failures: The paper does not explicitly address how the model might perform in the presence of sensor noise, calibration errors, or complete sensor failures, which are common challenges in real-world 3D perception systems.
- Interpretability and Explainability: As with many deep learning models, the internal workings of UdeerLID+ may be difficult to interpret, which could limit its adoption in applications that require high levels of transparency and explainability.
To address these limitations, future research could explore techniques to improve the model's data efficiency, computational efficiency, robustness, and interpretability. Additionally, further evaluation on diverse real-world datasets and in challenging operational environments would help to better understand the model's strengths and weaknesses.
Conclusion
UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised presents a promising approach for 3D scene understanding that leverages multimodal data and semi-supervised learning. By combining LiDAR, image, and relative depth information, the UdeerLID+ model can gain a more comprehensive understanding of the 3D environment, leading to improvements in tasks like semantic segmentation and 3D object detection.
The semi-supervised learning approach adopted by UdeerLID+ is particularly noteworthy, as it allows the model to learn from both labeled and unlabeled data, which can be beneficial in scenarios where labeled data is scarce. This could have significant implications for the deployment of 3D perception systems in real-world applications, where data annotation can be a significant bottleneck.
Overall, the UdeerLID+ model represents an important step forward in the field of 3D scene understanding, with the potential to enable more robust and reliable 3D perception capabilities for a wide range of applications, from autonomous vehicles and robotics to augmented reality and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised
Tao Ni, Xin Zhan, Tao Luo, Wenbin Liu, Zhan Shi, JunBo Chen
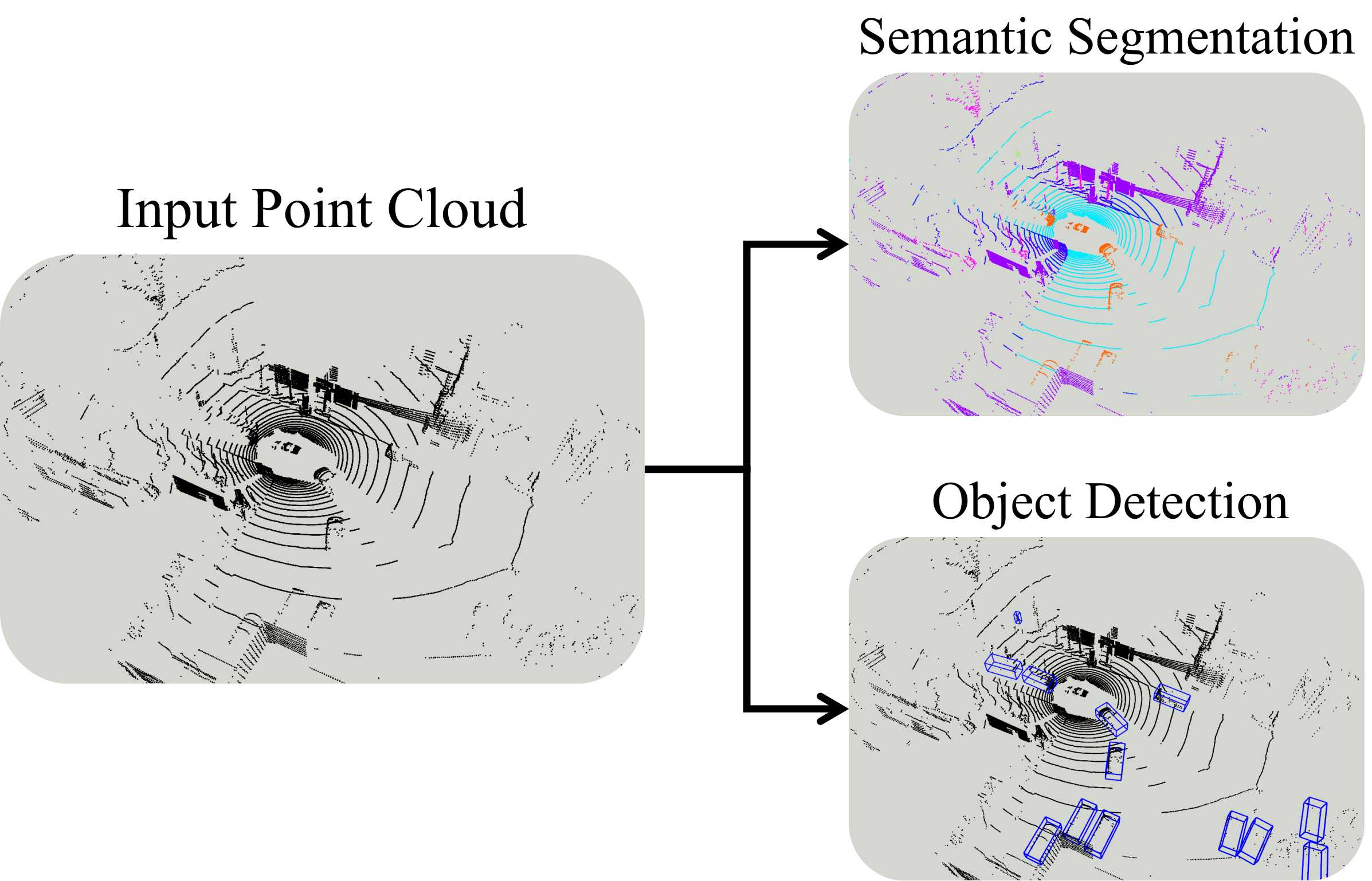
Road segmentation is a critical task for autonomous driving systems, requiring accurate and robust methods to classify road surfaces from various environmental data. Our work introduces an innovative approach that integrates LiDAR point cloud data, visual image, and relative depth maps derived from images. The integration of multiple data sources in road segmentation presents both opportunities and challenges. One of the primary challenges is the scarcity of large-scale, accurately labeled datasets that are necessary for training robust deep learning models. To address this, we have developed the [UdeerLID+] framework under a semi-supervised learning paradigm. Experiments results on KITTI datasets validate the superior performance.
Read more9/11/2024

0
Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
Lingdong Kong, Xiang Xu, Jiawei Ren, Wenwei Zhang, Liang Pan, Kai Chen, Wei Tsang Ooi, Ziwei Liu
Efficient data utilization is crucial for advancing 3D scene understanding in autonomous driving, where reliance on heavily human-annotated LiDAR point clouds challenges fully supervised methods. Addressing this, our study extends into semi-supervised learning for LiDAR semantic segmentation, leveraging the intrinsic spatial priors of driving scenes and multi-sensor complements to augment the efficacy of unlabeled datasets. We introduce LaserMix++, an evolved framework that integrates laser beam manipulations from disparate LiDAR scans and incorporates LiDAR-camera correspondences to further assist data-efficient learning. Our framework is tailored to enhance 3D scene consistency regularization by incorporating multi-modality, including 1) multi-modal LaserMix operation for fine-grained cross-sensor interactions; 2) camera-to-LiDAR feature distillation that enhances LiDAR feature learning; and 3) language-driven knowledge guidance generating auxiliary supervisions using open-vocabulary models. The versatility of LaserMix++ enables applications across LiDAR representations, establishing it as a universally applicable solution. Our framework is rigorously validated through theoretical analysis and extensive experiments on popular driving perception datasets. Results demonstrate that LaserMix++ markedly outperforms fully supervised alternatives, achieving comparable accuracy with five times fewer annotations and significantly improving the supervised-only baselines. This substantial advancement underscores the potential of semi-supervised approaches in reducing the reliance on extensive labeled data in LiDAR-based 3D scene understanding systems.
Read more5/9/2024
0
LiSD: An Efficient Multi-Task Learning Framework for LiDAR Segmentation and Detection
Jiahua Xu, Si Zuo, Chenfeng Wei, Wei Zhou
With the rapid proliferation of autonomous driving, there has been a heightened focus on the research of lidar-based 3D semantic segmentation and object detection methodologies, aiming to ensure the safety of traffic participants. In recent decades, learning-based approaches have emerged, demonstrating remarkable performance gains in comparison to conventional algorithms. However, the segmentation and detection tasks have traditionally been examined in isolation to achieve the best precision. To this end, we propose an efficient multi-task learning framework named LiSD which can address both segmentation and detection tasks, aiming to optimize the overall performance. Our proposed LiSD is a voxel-based encoder-decoder framework that contains a hierarchical feature collaboration module and a holistic information aggregation module. Different integration methods are adopted to keep sparsity in segmentation while densifying features for query initialization in detection. Besides, cross-task information is utilized in an instance-aware refinement module to obtain more accurate predictions. Experimental results on the nuScenes dataset and Waymo Open Dataset demonstrate the effectiveness of our proposed model. It is worth noting that LiSD achieves the state-of-the-art performance of 83.3% mIoU on the nuScenes segmentation benchmark for lidar-only methods.
Read more6/13/2024
🏋️
0
An Empirical Study of Training State-of-the-Art LiDAR Segmentation Models
Jiahao Sun, Chunmei Qing, Xiang Xu, Lingdong Kong, Youquan Liu, Li Li, Chenming Zhu, Jingwei Zhang, Zeqi Xiao, Runnan Chen, Tai Wang, Wenwei Zhang, Kai Chen
In the rapidly evolving field of autonomous driving, precise segmentation of LiDAR data is crucial for understanding complex 3D environments. Traditional approaches often rely on disparate, standalone codebases, hindering unified advancements and fair benchmarking across models. To address these challenges, we introduce MMDetection3D-lidarseg, a comprehensive toolbox designed for the efficient training and evaluation of state-of-the-art LiDAR segmentation models. We support a wide range of segmentation models and integrate advanced data augmentation techniques to enhance robustness and generalization. Additionally, the toolbox provides support for multiple leading sparse convolution backends, optimizing computational efficiency and performance. By fostering a unified framework, MMDetection3D-lidarseg streamlines development and benchmarking, setting new standards for research and application. Our extensive benchmark experiments on widely-used datasets demonstrate the effectiveness of the toolbox. The codebase and trained models have been publicly available, promoting further research and innovation in the field of LiDAR segmentation for autonomous driving.
Read more5/31/2024