UELLM: A Unified and Efficient Approach for LLM Inference Serving

0
Sign in to get full access
Overview
- Provides a unified and efficient approach for serving large language models (LLMs) called UELLM
- Aims to improve the performance and resource efficiency of LLM inference serving
- Introduces a novel scheduling algorithm and resource management techniques
Plain English Explanation
The paper presents a new system called UELLM that is designed to make it easier and more efficient to use large language models (LLMs) in applications. LLMs are powerful AI models that can generate human-like text, answer questions, and perform other language-related tasks. However, running these models can be computationally intensive and resource-hungry, which can make it challenging to use them in real-world applications.
UELLM addresses this challenge by introducing a unified and efficient approach to serving LLMs. The key ideas include:
- A novel scheduling algorithm that optimizes the use of computing resources to improve performance and efficiency.
- Resource management techniques that dynamically allocate and scale computing resources based on demand, avoiding over-provisioning or under-provisioning.
- A unified system that can handle a variety of LLM models and use cases, rather than requiring separate systems for different models or applications.
By using these techniques, UELLM aims to make it easier and more cost-effective to deploy LLMs in a wide range of applications, from chatbots and virtual assistants to content generation and language analysis tools.
Technical Explanation
The paper first provides background on the challenges of serving LLMs, including the need to manage compute resources efficiently, handle heterogeneous LLM models, and support diverse use cases. [The authors motivate the need for a unified and efficient approach to LLM inference serving.]
The core of the UELLM system is a novel scheduling algorithm that optimizes the allocation of computing resources to LLM inference tasks. The algorithm takes into account factors like model size, hardware requirements, and expected latency to schedule tasks in a way that maximizes overall system throughput and efficiency.
UELLM also introduces resource management techniques that dynamically scale computing resources up or down based on demand. This helps avoid over-provisioning (wasting resources) or under-provisioning (causing performance issues) when serving LLMs.
The paper describes the UELLM system architecture, which includes components for task scheduling, resource management, and model abstraction. This allows UELLM to handle a variety of LLM models and use cases within a unified framework.
The authors evaluate UELLM using real-world LLM models and workloads, demonstrating significant improvements in throughput, latency, and resource efficiency compared to baseline approaches.
Critical Analysis
The paper makes a compelling case for the need for a unified and efficient system for serving LLMs, and the UELLM approach appears to be a promising solution. The novel scheduling algorithm and resource management techniques are well-designed and seem to offer substantial benefits.
However, the paper does not address some potential limitations or areas for further research. For example, it does not discuss how UELLM would handle LLM models that are updated or fine-tuned over time, or how it would scale to support very large numbers of concurrent users or requests.
Additionally, the paper does not delve into the potential energy and environmental impact of running LLM inference at scale, which is an important consideration as these models become more widely adopted. [Addressing the energy efficiency and sustainability of LLM serving systems could be an important area for future work.]
Overall, the UELLM approach represents a significant advance in the state of the art for LLM inference serving, and the paper provides a solid technical foundation for further research and development in this area.
Conclusion
The UELLM paper introduces a unified and efficient approach for serving large language models (LLMs) that addresses key challenges in performance, resource efficiency, and model heterogeneity. By leveraging a novel scheduling algorithm and dynamic resource management techniques, UELLM aims to make it easier and more cost-effective to deploy LLMs in a wide range of real-world applications.
The technical details and evaluation results presented in the paper suggest that UELLM could have a substantial impact on the way LLMs are served and utilized in the future. However, the paper also highlights the need for further research to address potential limitations and explore the broader implications of large-scale LLM inference, such as its environmental impact.
As LLMs continue to grow in importance and become more widely adopted, systems like UELLM will play a crucial role in ensuring that these powerful AI models can be leveraged efficiently and effectively across a wide range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UELLM: A Unified and Efficient Approach for LLM Inference Serving
Yiyuan He, Minxian Xu, Jingfeng Wu, Wanyi Zheng, Kejiang Ye, Chengzhong Xu
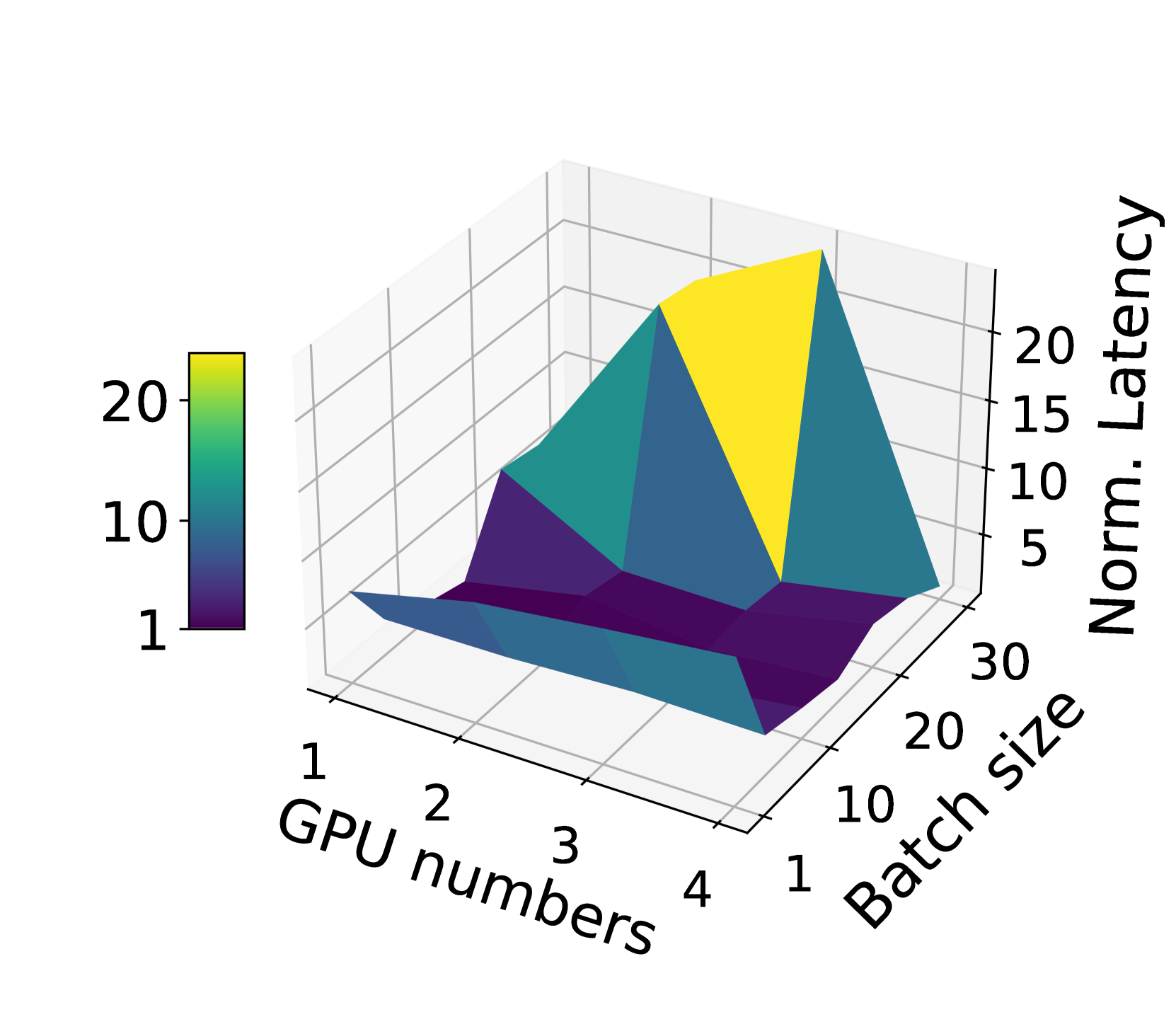
In the context of Machine Learning as a Service (MLaaS) clouds, the extensive use of Large Language Models (LLMs) often requires efficient management of significant query loads. When providing real-time inference services, several challenges arise. Firstly, increasing the number of GPUs may lead to a decrease in inference speed due to heightened communication overhead, while an inadequate number of GPUs can lead to out-of-memory errors. Secondly, different deployment strategies need to be evaluated to guarantee optimal utilization and minimal inference latency. Lastly, inefficient orchestration of inference queries can easily lead to significant Service Level Objective (SLO) violations. Lastly, inefficient orchestration of inference queries can easily lead to significant Service Level Objective (SLO) violations. To address these challenges, we propose a Unified and Efficient approach for Large Language Model inference serving (UELLM), which consists of three main components: 1) resource profiler, 2) batch scheduler, and 3) LLM deployer. UELLM minimizes resource overhead, reduces inference latency, and lowers SLO violation rates. Compared with state-of-the-art (SOTA) techniques, UELLM reduces the inference latency by 72.3% to 90.3%, enhances GPU utilization by 1.2X to 4.1X, and increases throughput by 1.92X to 4.98X, it can also serve without violating the inference latency SLO.
Read more9/25/2024

0
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
Yuhang Yao, Han Jin, Alay Dilipbhai Shah, Shanshan Han, Zijian Hu, Yide Ran, Dimitris Stripelis, Zhaozhuo Xu, Salman Avestimehr, Chaoyang He
Large language models (LLMs) have surged in popularity and are extensively used in commercial applications, where the efficiency of model serving is crucial for the user experience. Most current research focuses on optimizing individual sub-procedures, e.g. local inference and communication, however, there is no comprehensive framework that provides a holistic system view for optimizing LLM serving in an end-to-end manner. In this work, we conduct a detailed analysis to identify major bottlenecks that impact end-to-end latency in LLM serving systems. Our analysis reveals that a comprehensive LLM serving endpoint must address a series of efficiency bottlenecks that extend beyond LLM inference. We then propose ScaleLLM, an optimized system for resource-efficient LLM serving. Our extensive experiments reveal that with 64 concurrent requests, ScaleLLM achieves a 4.3x speed up over vLLM and outperforms state-of-the-arts with 1.5x higher throughput.
Read more9/12/2024
0
Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference
Jovan Stojkovic, Esha Choukse, Chaojie Zhang, Inigo Goiri, Josep Torrellas
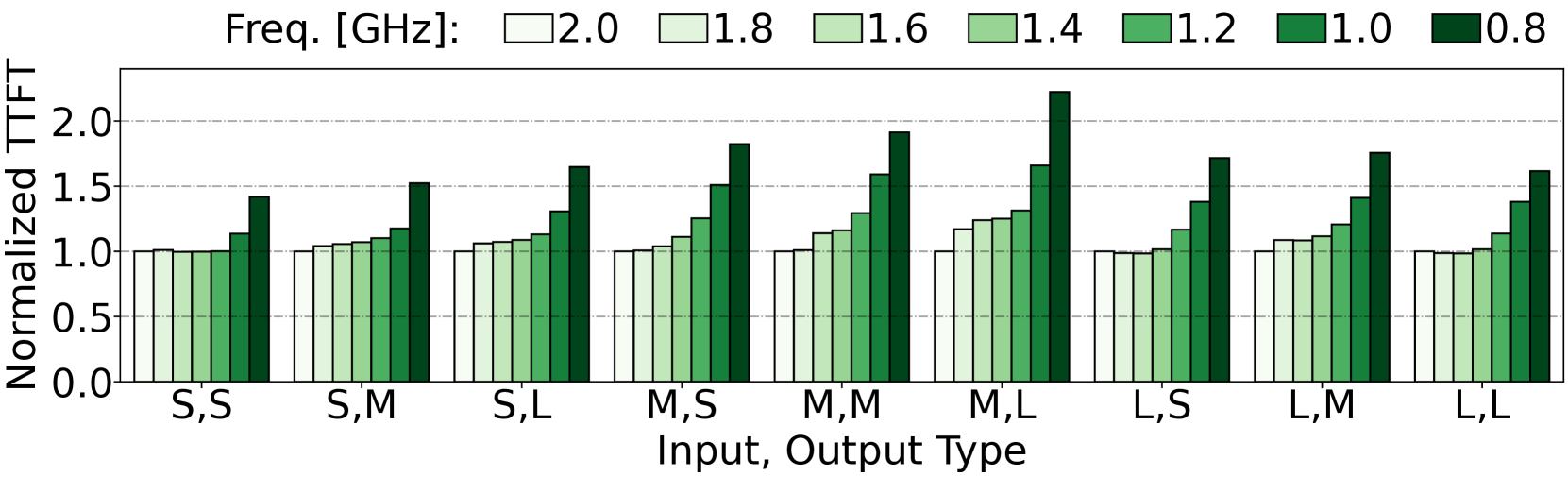
With the ubiquitous use of modern large language models (LLMs) across industries, the inference serving for these models is ever expanding. Given the high compute and memory requirements of modern LLMs, more and more top-of-the-line GPUs are being deployed to serve these models. Energy availability has come to the forefront as the biggest challenge for data center expansion to serve these models. In this paper, we present the trade-offs brought up by making energy efficiency the primary goal of LLM serving under performance SLOs. We show that depending on the inputs, the model, and the service-level agreements, there are several knobs available to the LLM inference provider to use for being energy efficient. We characterize the impact of these knobs on the latency, throughput, as well as the energy. By exploring these trade-offs, we offer valuable insights into optimizing energy usage without compromising on performance, thereby paving the way for sustainable and cost-effective LLM deployment in data center environments.
Read more4/1/2024

0
ELMS: Elasticized Large Language Models On Mobile Devices
Wangsong Yin, Rongjie Yi, Daliang Xu, Gang Huang, Mengwei Xu, Xuanzhe Liu
On-device Large Language Models (LLMs) are revolutionizing mobile AI, enabling applications such as UI automation while addressing privacy concerns. Currently, the standard approach involves deploying a single, robust LLM as a universal solution for various applications, often referred to as LLM-as-a-Service (LLMaaS). However, this approach faces a significant system challenge: existing LLMs lack the flexibility to accommodate the diverse Service-Level Objectives (SLOs) regarding inference latency across different applications. To address this issue, we introduce ELMS, an on-device LLM service designed to provide elasticity in both the model and prompt dimensions of an LLMaaS. This system includes: A one-time neuron reordering technique, which utilizes the inherent permutation consistency within transformer models to create high-quality, elastic sub-models with minimal runtime switching costs. A dual-head compact language model, which efficiently refines prompts and coordinates the elastic adaptation between the model and the prompt. We have implemented this elastic on-device LLM service on several off-the-shelf (COTS) smartphones and evaluate ELMS using both standalone NLP/mobile-agent datasets and synthesized end-to-end traces. Across a range of SLOs, ELMS surpasses four strong baselines by up to 16.83% and 11.04% in absolute accuracy on average, with less than 1% Time-To-First-Token (TTFT) switching overhead, comparable memory usage, and fewer than 100 offline GPU hours.
Read more9/17/2024