UltraMedical: Building Specialized Generalists in Biomedicine

0

Sign in to get full access
Overview
- This paper presents "UltraMedical", a dataset and approach for training specialized generalists in biomedicine.
- The key idea is to create models that can handle a wide range of biomedical tasks, rather than highly specialized models for individual tasks.
- The dataset and models are designed to enable "specialized generalists" - models that can apply broad biomedical knowledge to a variety of applications.
Plain English Explanation
The paper introduces the "UltraMedical" dataset and approach, which aims to create specialized generalist models for biomedical tasks. Rather than developing narrow, specialized models for individual applications, the researchers wanted to build more versatile models that could apply broad biomedical knowledge across a range of problems.
The motivation is that in many real-world biomedical scenarios, a single solution needs to handle diverse challenges. A doctor, for example, must draw on a wide base of medical knowledge to diagnose and treat patients. Similarly, an AI system supporting clinical decision-making should have a deep, flexible understanding of biomedicine, not just specific skills.
The UltraMedical dataset was constructed to enable training these kinds of "specialized generalist" models. It encompasses a broad range of biomedical topics and tasks, from scientific literature to electronic health records. The goal is for models trained on this dataset to develop rich, adaptable biomedical knowledge that can be applied creatively to novel challenges.
By taking this generalist approach, the researchers hope to advance the state-of-the-art in biomedical AI, moving beyond narrow task-specific models towards more flexible, knowledgeable systems. This could have important implications for medical large language models and other multimodal biomedical AI applications.
Technical Explanation
The key components of the UltraMedical approach are the dataset and the specialized generalist model training process.
The UltraMedical dataset was constructed by aggregating a diverse range of biomedical data sources, including scientific publications, clinical notes, and electronic health records. This creates a large, comprehensive corpus covering a breadth of biomedical topics and tasks, from clinical named entity recognition to digital diagnostics.
The training process aims to imbue models with specialized yet generalist biomedical capabilities. Rather than optimizing for narrow task performance, the models are trained to develop rich, adaptable biomedical knowledge that can be flexibly applied. This involves techniques like multi-task learning, where models are trained on a diverse array of biomedical tasks simultaneously.
The researchers hypothesize that this "specialized generalist" approach will enable more versatile, knowledgeable biomedical AI systems. By building models with broad biomedical understanding, they aim to create AI assistants that can fluidly handle the complex, multi-faceted challenges encountered in real-world medical practice and research.
Critical Analysis
The UltraMedical approach represents an ambitious and important step towards more capable, flexible biomedical AI systems. By focusing on specialized generalists rather than narrow task-specific models, the researchers are attempting to address a key limitation of current biomedical AI - the inability to seamlessly apply knowledge across diverse domains and challenges.
That said, the researchers acknowledge several potential limitations and areas for further exploration. For example, the dataset construction and model training processes are highly complex, and it remains to be seen whether the specialized generalist approach can truly match the performance of state-of-the-art models on individual biomedical tasks.
Additionally, the societal and ethical implications of such powerful biomedical AI systems warrant careful consideration. Issues around data privacy, algorithmic bias, and the responsible deployment of these technologies in clinical settings will need to be rigorously addressed.
Overall, the UltraMedical research represents an important step forward, but there is still significant work to be done to realize the vision of flexible, knowledgeable biomedical AI assistants. Ongoing research in medical large language models and multimodal biomedical AI will undoubtedly build on these foundations and continue to push the boundaries of what's possible.
Conclusion
The UltraMedical dataset and approach introduce a novel paradigm for biomedical AI, moving away from narrow task-specific models towards more versatile, knowledgeable "specialized generalist" systems. By training models on a diverse range of biomedical data and tasks, the researchers aim to create AI assistants that can fluidly apply broad biomedical understanding to complex, real-world challenges.
While there are still significant technical and ethical challenges to overcome, the UltraMedical research represents an important milestone in the quest for truly capable, flexible biomedical AI. As the fields of medical large language models and multimodal biomedical AI continue to evolve, the specialized generalist approach pioneered by UltraMedical may prove to be a crucial stepping stone towards the next generation of biomedical AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UltraMedical: Building Specialized Generalists in Biomedicine
Kaiyan Zhang, Sihang Zeng, Ermo Hua, Ning Ding, Zhang-Ren Chen, Zhiyuan Ma, Haoxin Li, Ganqu Cui, Biqing Qi, Xuekai Zhu, Xingtai Lv, Hu Jinfang, Zhiyuan Liu, Bowen Zhou
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains and are moving towards more specialized areas. Recent advanced proprietary models such as GPT-4 and Gemini have achieved significant advancements in biomedicine, which have also raised privacy and security challenges. The construction of specialized generalists hinges largely on high-quality datasets, enhanced by techniques like supervised fine-tuning and reinforcement learning from human or AI feedback, and direct preference optimization. However, these leading technologies (e.g., preference learning) are still significantly limited in the open source community due to the scarcity of specialized data. In this paper, we present the UltraMedical collections, which consist of high-quality manual and synthetic datasets in the biomedicine domain, featuring preference annotations across multiple advanced LLMs. By utilizing these datasets, we fine-tune a suite of specialized medical models based on Llama-3 series, demonstrating breathtaking capabilities across various medical benchmarks. Moreover, we develop powerful reward models skilled in biomedical and general reward benchmark, enhancing further online preference learning within the biomedical LLM community.
Read more6/7/2024
0
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
Felix J. Dorfner, Amin Dada, Felix Busch, Marcus R. Makowski, Tianyu Han, Daniel Truhn, Jens Kleesiek, Madhumita Sushil, Jacqueline Lammert, Lisa C. Adams, Keno K. Bressem
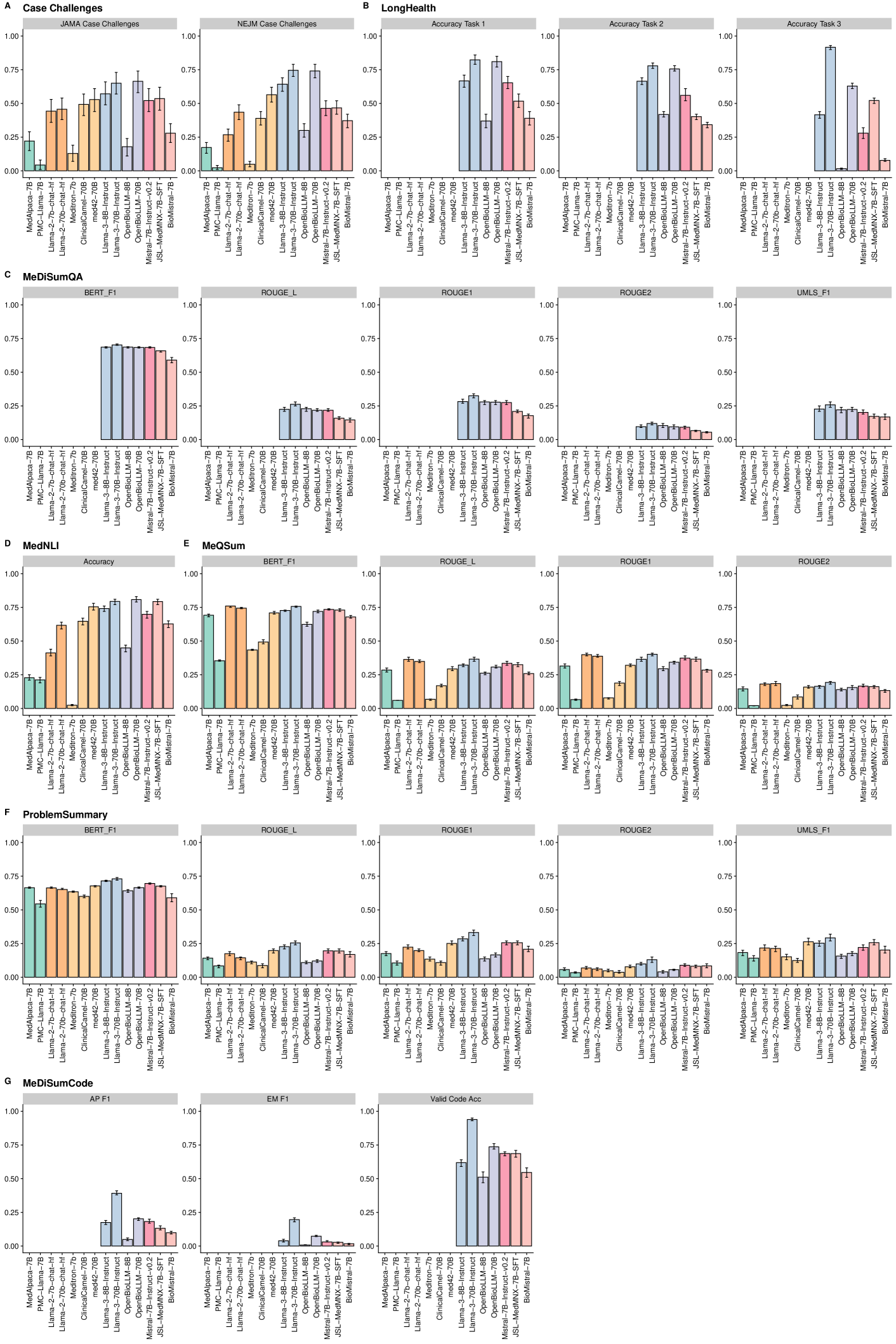
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
Read more8/27/2024
0
A Survey for Large Language Models in Biomedicine
Chong Wang, Mengyao Li, Junjun He, Zhongruo Wang, Erfan Darzi, Zan Chen, Jin Ye, Tianbin Li, Yanzhou Su, Jing Ke, Kaili Qu, Shuxin Li, Yi Yu, Pietro Li`o, Tianyun Wang, Yu Guang Wang, Yiqing Shen
Recent breakthroughs in large language models (LLMs) offer unprecedented natural language understanding and generation capabilities. However, existing surveys on LLMs in biomedicine often focus on specific applications or model architectures, lacking a comprehensive analysis that integrates the latest advancements across various biomedical domains. This review, based on an analysis of 484 publications sourced from databases including PubMed, Web of Science, and arXiv, provides an in-depth examination of the current landscape, applications, challenges, and prospects of LLMs in biomedicine, distinguishing itself by focusing on the practical implications of these models in real-world biomedical contexts. Firstly, we explore the capabilities of LLMs in zero-shot learning across a broad spectrum of biomedical tasks, including diagnostic assistance, drug discovery, and personalized medicine, among others, with insights drawn from 137 key studies. Then, we discuss adaptation strategies of LLMs, including fine-tuning methods for both uni-modal and multi-modal LLMs to enhance their performance in specialized biomedical contexts where zero-shot fails to achieve, such as medical question answering and efficient processing of biomedical literature. Finally, we discuss the challenges that LLMs face in the biomedicine domain including data privacy concerns, limited model interpretability, issues with dataset quality, and ethics due to the sensitive nature of biomedical data, the need for highly reliable model outputs, and the ethical implications of deploying AI in healthcare. To address these challenges, we also identify future research directions of LLM in biomedicine including federated learning methods to preserve data privacy and integrating explainable AI methodologies to enhance the transparency of LLMs.
Read more9/4/2024

0
A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
Read more6/18/2024