Unboxing Engagement in YouTube Influencer Videos: An Attention-Based Approach

0
📉
Sign in to get full access
Overview
- Influencer marketing videos have become increasingly popular, but there is a lack of understanding about the relationship between video features and viewer engagement.
- Deep learning models can effectively predict business outcomes using unstructured data, but they often function as "black boxes" with limited interpretability.
- The authors developed an interpretable deep learning framework that not only makes accurate predictions using unstructured data, but also provides insights into the captured relationships.
Plain English Explanation
The researchers wanted to better understand how different features of influencer marketing videos (like the content, style, or format) affect how viewers engage with the videos. Viewer engagement can be measured in different ways, from simple views to more meaningful "deep" engagement.
However, the data used in these videos is often unstructured, meaning it doesn't fit neatly into rows and columns. Deep learning models are good at making predictions from this kind of messy data, but they can be like "black boxes" - it's hard to understand how they arrive at their conclusions.
To address this, the researchers developed a new deep learning framework that not only makes accurate predictions, but also explains how it arrived at those predictions. It does this by measuring the "attention" the model pays to different features of the videos, allowing the researchers to see which video elements are most important for driving viewer engagement.
This approach is inspired by how advertisers in print media use visual "attention" to understand what parts of an ad are most impactful. By applying similar techniques to influencer marketing videos, the researchers were able to identify the video features that are most strongly linked to both shallow (e.g. views) and deep (e.g. comments, shares) forms of viewer engagement.
Technical Explanation
The researchers developed an interpretable deep learning framework that uses measures of model attention to video features in order to understand the relationships between video characteristics and viewer engagement. This approach is inspired by visual attention in print advertising and can be applied across different attention mechanisms, including additive attention, scaled dot-product attention, and gradient-based attention.
The framework involves a two-step process to eliminate spurious associations and shortlist relationships for formal causal testing. First, the model's attention weights are used to identify the most salient video features. Then, the relationships between these features and engagement metrics are further scrutinized to isolate the true, meaningful connections.
The researchers validated this approach using simulations and found that it outperformed benchmark feature selection methods. They then applied the framework to a dataset of YouTube influencer videos, linking video features to measures of both shallow and deep engagement based on the dual-system framework of thinking.
Critical Analysis
One potential limitation of this research is the reliance on observational data, which can make it challenging to establish true causal relationships between video features and engagement. While the two-step process helps to isolate the most meaningful connections, further experimental studies may be needed to confirm the causal nature of these relationships.
Additionally, the framework is focused on interpreting the model's attention weights, which may not capture all of the complex, nonlinear relationships that deep learning models can uncover. There may be value in exploring alternative interpretability techniques, such as concept-based explanations, to gain a more nuanced understanding of the model's decision-making process.
Finally, while the findings from this research provide valuable insights for influencers and brands, it will be important to continuously monitor and adapt strategies as viewer preferences and platform algorithms evolve over time. Ongoing monitoring and evaluation will be crucial for ensuring the continued relevance and effectiveness of these insights.
Conclusion
This research presents an interpretable deep learning framework that can be used to better understand the relationship between influencer marketing video features and viewer engagement. By leveraging measures of model attention, the researchers were able to identify the video characteristics that are most strongly linked to both shallow and deep forms of engagement.
These insights can help influencers and brands optimize their video content to better connect with their target audiences and drive more meaningful engagement. Moreover, the interpretability of this framework means that its findings can be easily communicated and validated, rather than relying on a "black box" approach.
Overall, this work represents an important step forward in bridging the gap between the predictive power of deep learning and the need for human-interpretable insights, particularly in the context of influencer marketing and unstructured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Unboxing Engagement in YouTube Influencer Videos: An Attention-Based Approach
Prashant Rajaram, Puneet Manchanda
Influencer marketing videos have surged in popularity, yet significant gaps remain in understanding the relationship between video features and engagement. This challenge is intensified by the complexities of interpreting unstructured data. While deep learning models effectively leverage unstructured data to predict business outcomes, they often function as black boxes with limited interpretability, particularly when human validation is hindered by the absence of a known ground truth. To address this issue, the authors develop an interpretable deep learning framework that not only makes good out-of-sample predictions using unstructured data but also provides insights into the captured relationships. Inspired by visual attention in print advertising, the interpretation approach uses measures of model attention to video features, eliminating spurious associations through a two-step process and shortlisting relationships for formal causal testing. This method is applicable across well-known attention mechanisms - additive attention, scaled dot-product attention, and gradient-based attention - when analyzing text, audio, or video image data. Validated using simulations, this approach outperforms benchmark feature selection methods. This framework is applied to YouTube influencer videos, linking video features to measures of shallow and deep engagement developed based on the dual-system framework of thinking. The findings guide influencers and brands in prioritizing video features associated with deep engagement.
Read more8/27/2024

0
A General Model for Detecting Learner Engagement: Implementation and Evaluation
Somayeh Malekshahi, Javad M. Kheyridoost, Omid Fatemi
Considering learner engagement has a mutual benefit for both learners and instructors. Instructors can help learners increase their attention, involvement, motivation, and interest. On the other hand, instructors can improve their instructional performance by evaluating the cumulative results of all learners and upgrading their training programs. This paper proposes a general, lightweight model for selecting and processing features to detect learners' engagement levels while preserving the sequential temporal relationship over time. During training and testing, we analyzed the videos from the publicly available DAiSEE dataset to capture the dynamic essence of learner engagement. We have also proposed an adaptation policy to find new labels that utilize the affective states of this dataset related to education, thereby improving the models' judgment. The suggested model achieves an accuracy of 68.57% in a specific implementation and outperforms the studied state-of-the-art models detecting learners' engagement levels.
Read more5/8/2024

0
Understanding Generative AI Content with Embedding Models
Max Vargas, Reilly Cannon, Andrew Engel, Anand D. Sarwate, Tony Chiang
The construction of high-quality numerical features is critical to any quantitative data analysis. Feature engineering has been historically addressed by carefully hand-crafting data representations based on domain expertise. This work views the internal representations of modern deep neural networks (DNNs), called embeddings, as an automated form of traditional feature engineering. For trained DNNs, we show that these embeddings can reveal interpretable, high-level concepts in unstructured sample data. We use these embeddings in natural language and computer vision tasks to uncover both inherent heterogeneity in the underlying data and human-understandable explanations for it. In particular, we find empirical evidence that there is inherent separability between real data and that generated from AI models.
Read more8/26/2024
0
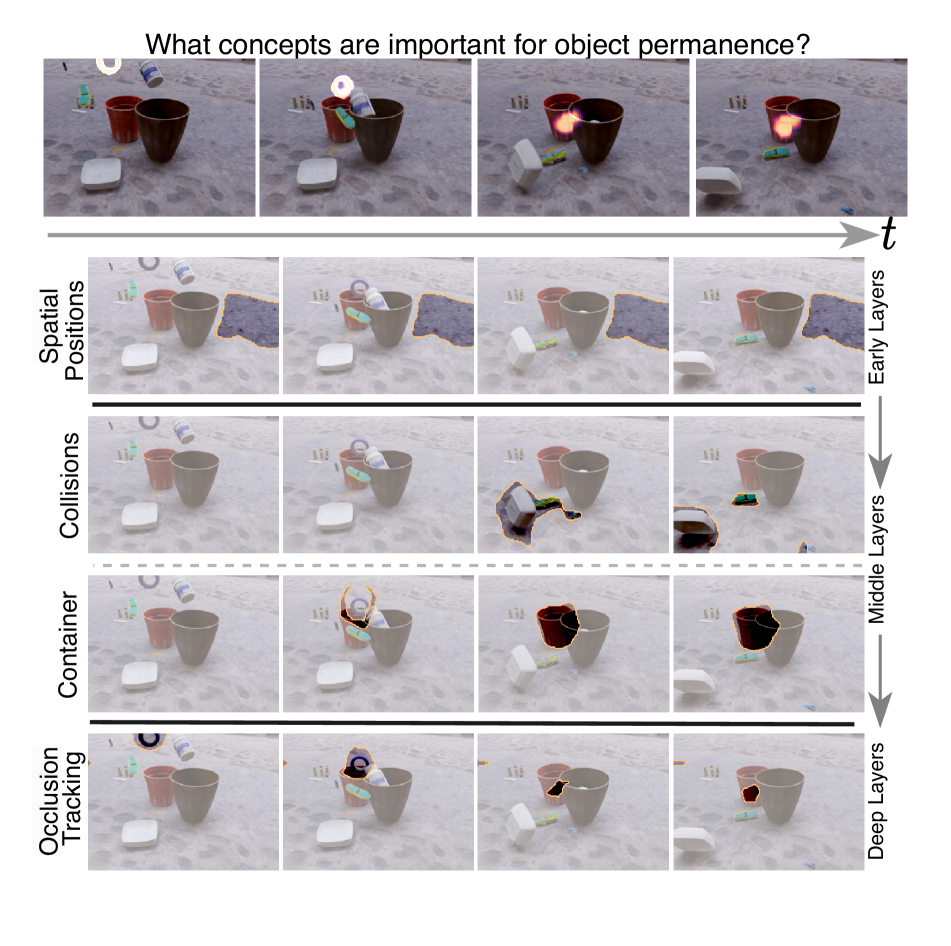
Understanding Video Transformers via Universal Concept Discovery
Matthew Kowal, Achal Dave, Rares Ambrus, Adrien Gaidon, Konstantinos G. Derpanis, Pavel Tokmakov
This paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks. Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time. In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations - concepts, and ranking their importance to the output of a model. The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and object-centric representations in unstructured video models. Performing this analysis jointly over a diverse set of supervised and self-supervised representations, we discover that some of these mechanism are universal in video transformers. Finally, we show that VTCD can be used for fine-grained action recognition and video object segmentation.
Read more4/11/2024