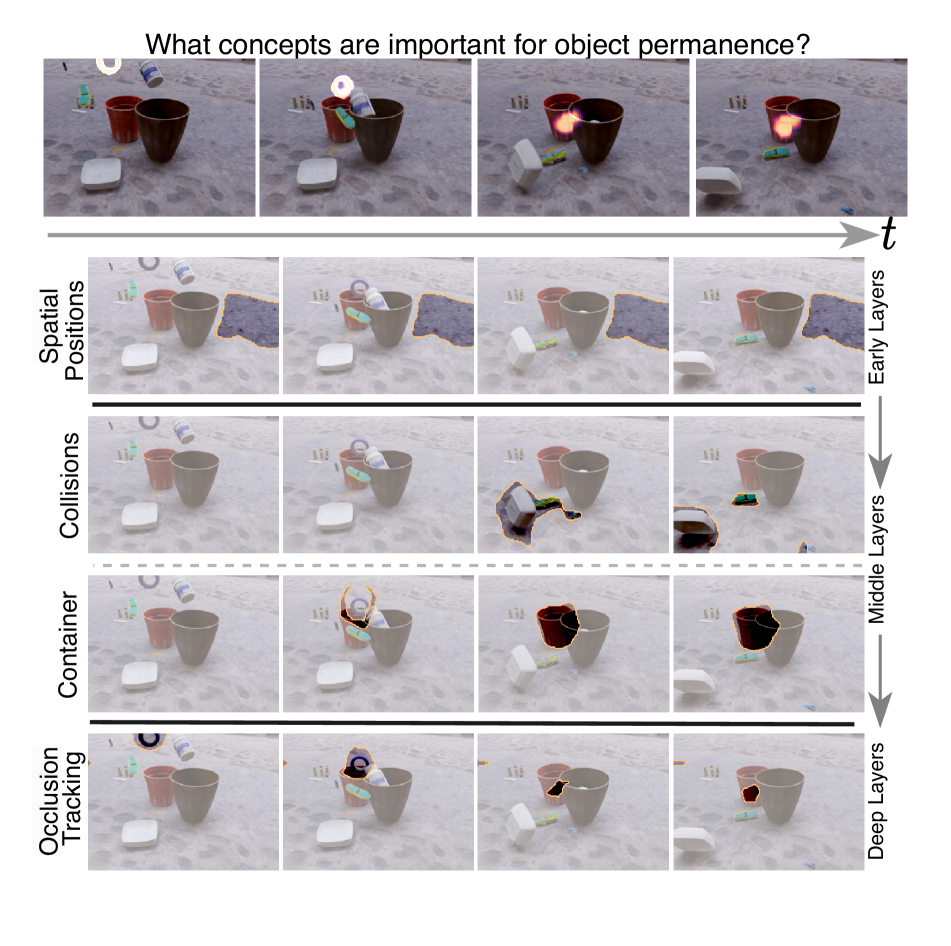
Understanding Video Transformers via Universal Concept Discovery
2401.10831
0
0
Abstract
This paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks. Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time. In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations - concepts, and ranking their importance to the output of a model. The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and object-centric representations in unstructured video models. Performing this analysis jointly over a diverse set of supervised and self-supervised representations, we discover that some of these mechanism are universal in video transformers. Finally, we show that VTCD can be used for fine-grained action recognition and video object segmentation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how to better understand the inner workings of video transformer models, which are a type of deep learning model used for video analysis tasks.
- The researchers propose a new method called "universal concept discovery" that can identify the key visual concepts that video transformers rely on to make predictions.
- By understanding these underlying concepts, the researchers aim to provide more transparent and interpretable video transformer models.
Plain English Explanation
Video transformers are a powerful type of deep learning model that have shown impressive performance on various video analysis tasks, such as action recognition and video captioning. However, these models can be difficult to interpret and understand, as they learn complex patterns from the data without always exposing the reasoning behind their predictions.
The researchers behind this paper wanted to shed light on how video transformers work under the hood. They developed a new technique called "universal concept discovery" that can identify the key visual concepts that these models rely on when making decisions. The idea is that by understanding the fundamental building blocks the models use, we can gain deeper insights into their inner workings and make them more transparent.
To illustrate this, imagine a video transformer model that is tasked with recognizing different types of sports in videos. Instead of just seeing the model output a label like "basketball," the universal concept discovery method could reveal that the model is focusing on things like the shape of the ball, the court markings, and the players' movement patterns. This type of information can help explain why the model made a particular prediction and make it more trustworthy.
By applying their universal concept discovery approach to various video transformer models, the researchers were able to uncover the specific visual concepts that these models find most useful for different video understanding tasks. This provides valuable clues about how the models are processing and interpreting the video data, which can in turn inform efforts to enhance the efficiency of vision transformer networks and advance explainable AI models.
Technical Explanation
The core of the researchers' approach is a method they call "universal concept discovery" (UCD), which aims to identify the key visual concepts that a video transformer model relies on to make its predictions. The UCD process involves several steps:
-
Concept bank generation: The researchers first create a "concept bank" - a set of visual concepts that could potentially be relevant for the video understanding tasks at hand. This concept bank is generated by leveraging existing language-informed visual concept learning techniques.
-
Concept activation mapping: Next, the researchers map the activations of the video transformer model to the concepts in the bank, revealing which concepts the model is responding to the most for a given input video.
-
Concept importance ranking: By analyzing the concept activation patterns across many input videos, the researchers can then rank the importance of each concept, identifying the most salient visual building blocks the model uses.
The researchers applied this UCD framework to analyze several state-of-the-art video transformer models, including ViViT, TimeSformer, and VideoSwin Transformer. Their analysis provided insights into the models' reliance on factors like object appearance, motion patterns, and scene context when making video understanding predictions.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the quality of the UCD analysis is dependent on the comprehensiveness of the initial concept bank. While the researchers leveraged existing methods to construct a broad set of visual concepts, there may be important concepts missing that the models are implicitly learning.
Additionally, the UCD framework relies on gradient-based attribution methods, which can be sensitive to factors like model initialization and optimization. The researchers note that alternative concept-based analysis techniques may provide complementary insights.
Another potential issue is that the UCD analysis only reveals the visual concepts the models are using, but does not necessarily explain how those concepts are being combined and weighted to arrive at final predictions. Motion inversion and video customization techniques could potentially provide a richer understanding of the models' underlying reasoning.
Despite these limitations, the universal concept discovery approach represents an important step towards making video transformer models more transparent and interpretable. By surfacing the key visual concepts these models rely on, the researchers have provided a valuable tool for advancing ante-hoc explainable AI models in the video domain.
Conclusion
This paper introduces a novel technique called "universal concept discovery" that can identify the fundamental visual building blocks underlying video transformer models. By applying this method to several state-of-the-art video transformer architectures, the researchers were able to gain valuable insights into how these models process and interpret video data.
The findings from this work not only advance our understanding of video transformers, but also have broader implications for improving the transparency and interpretability of deep learning models in the video domain. As AI systems become increasingly ubiquitous in real-world applications, techniques like universal concept discovery will be crucial for ensuring these models are trustworthy and accountable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring Explainability in Video Action Recognition
Avinab Saha, Shashank Gupta, Sravan Kumar Ankireddy, Karl Chahine, Joydeep Ghosh
0
0
Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
4/16/2024
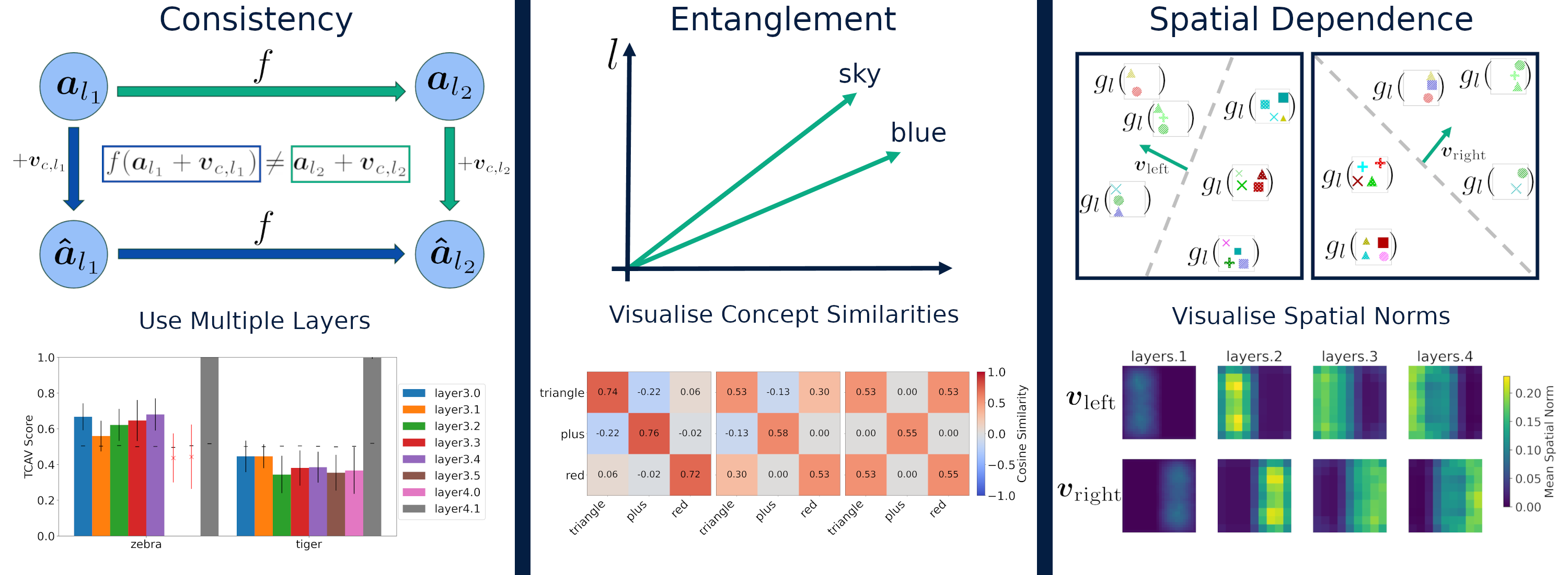
Explaining Explainability: Understanding Concept Activation Vectors
Angus Nicolson, Lisa Schut, J. Alison Noble, Yarin Gal
0
0
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
4/8/2024

Improving Interpretable Embeddings for Ad-hoc Video Search with Generative Captions and Multi-word Concept Bank
Jiaxin Wu, Chong-Wah Ngo, Wing-Kwong Chan
0
0
Aligning a user query and video clips in cross-modal latent space and that with semantic concepts are two mainstream approaches for ad-hoc video search (AVS). However, the effectiveness of existing approaches is bottlenecked by the small sizes of available video-text datasets and the low quality of concept banks, which results in the failures of unseen queries and the out-of-vocabulary problem. This paper addresses these two problems by constructing a new dataset and developing a multi-word concept bank. Specifically, capitalizing on a generative model, we construct a new dataset consisting of 7 million generated text and video pairs for pre-training. To tackle the out-of-vocabulary problem, we develop a multi-word concept bank based on syntax analysis to enhance the capability of a state-of-the-art interpretable AVS method in modeling relationships between query words. We also study the impact of current advanced features on the method. Experimental results show that the integration of the above-proposed elements doubles the R@1 performance of the AVS method on the MSRVTT dataset and improves the xinfAP on the TRECVid AVS query sets for 2016-2023 (eight years) by a margin from 2% to 77%, with an average about 20%.
4/10/2024
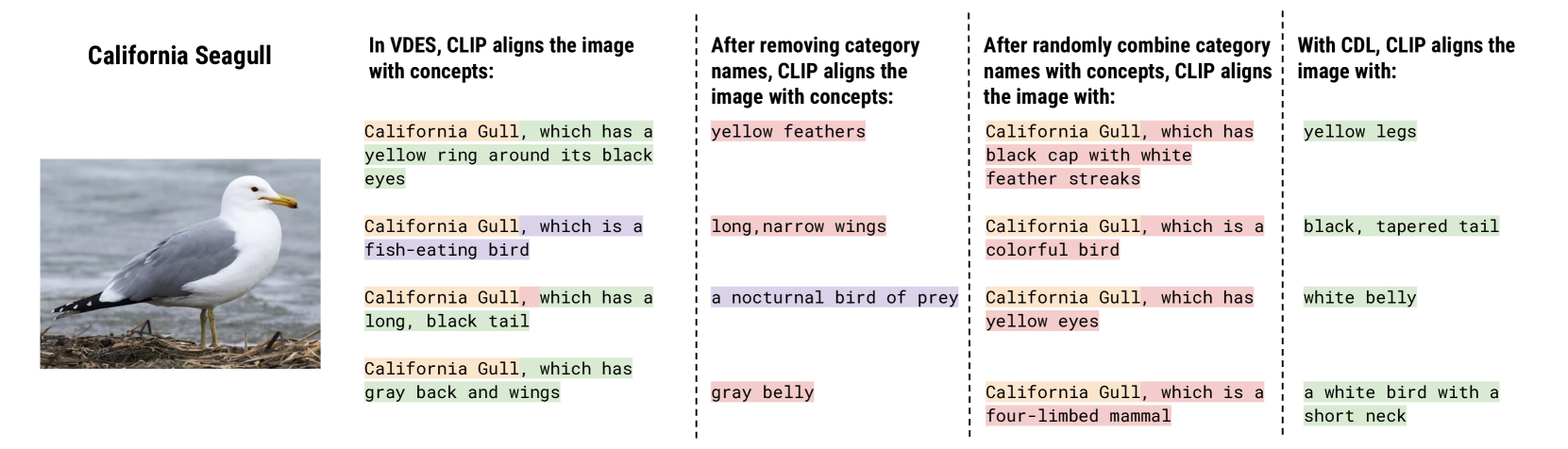
Pre-trained Vision-Language Models Learn Discoverable Visual Concepts
Yuan Zang, Tian Yun, Hao Tan, Trung Bui, Chen Sun
0
0
Do vision-language models (VLMs) pre-trained to caption an image of a durian learn visual concepts such as brown (color) and spiky (texture) at the same time? We aim to answer this question as visual concepts learned for free would enable wide applications such as neuro-symbolic reasoning or human-interpretable object classification. We assume that the visual concepts, if captured by pre-trained VLMs, can be extracted by their vision-language interface with text-based concept prompts. We observe that recent works prompting VLMs with concepts often differ in their strategies to define and evaluate the visual concepts, leading to conflicting conclusions. We propose a new concept definition strategy based on two observations: First, certain concept prompts include shortcuts that recognize correct concepts for wrong reasons; Second, multimodal information (e.g. visual discriminativeness, and textual knowledge) should be leveraged when selecting the concepts. Our proposed concept discovery and learning (CDL) framework is thus designed to identify a diverse list of generic visual concepts (e.g. spiky as opposed to spiky durian), which are ranked and selected based on visual and language mutual information. We carefully design quantitative and human evaluations of the discovered concepts on six diverse visual recognition datasets, which confirm that pre-trained VLMs do learn visual concepts that provide accurate and thorough descriptions for the recognized objects. All code and models are publicly released.
4/22/2024