Unconditional Latent Diffusion Models Memorize Patient Imaging Data: Implications for Openly Sharing Synthetic Data

0

Sign in to get full access
Overview
- This paper investigates the ability of unconditional latent diffusion models to memorize patient imaging data.
- The researchers found that these models can effectively memorize and reconstruct specific patient images, raising concerns about the potential misuse of such models in medical applications.
- The paper also discusses strategies for mitigating the risk of memorization, such as MemControl and Could It Be Generated.
Plain English Explanation
Diffusion models are a type of machine learning algorithm that can generate new images by starting with random noise and gradually transforming it into something more meaningful. These models are trained on large datasets of images, and they learn to recognize patterns and features that can be used to create new images.
In this paper, the researchers looked at how well these diffusion models can memorize and reconstruct specific patient medical images, such as X-rays or MRI scans. They found that the models were able to essentially "memorize" the individual patient images, rather than just learning general patterns from the dataset.
This is a concern because it means that these models could potentially be used to generate fake medical images, or to accidentally reveal sensitive patient information. The researchers suggest that this kind of memorization could be a problem in medical applications, where it's important to protect patient privacy and ensure the accuracy of medical data.
To address this issue, the researchers discuss some potential solutions, such as MemControl, which aims to reduce the amount of memorization in diffusion models, and Could It Be Generated, which provides a way to analyze whether a given image was generated by a diffusion model or not.
Overall, this research highlights an important challenge in the development of diffusion models for medical applications, and suggests that more work is needed to ensure the privacy and security of patient data.
Technical Explanation
The paper focuses on the ability of unconditional latent diffusion models to memorize patient imaging data. Latent diffusion models are a type of generative model that learn to transform random noise into realistic-looking images by iteratively adding and removing noise.
The researchers trained several unconditional latent diffusion models on large datasets of medical images, such as X-rays and MRI scans. They then tested the models' ability to reconstruct specific patient images that were part of the training data. The researchers found that the models were able to effectively memorize and reconstruct these individual patient images, rather than just learning general patterns from the dataset.
To quantify this effect, the researchers developed a metric called the "memorization score," which measures how well a model can reconstruct images that were part of its training data. They showed that the unconditional latent diffusion models had high memorization scores, indicating a concerning level of memorization.
The researchers also discussed strategies for mitigating the risk of memorization, such as MemControl, which aims to reduce the amount of memorization in diffusion models, and Could It Be Generated, which provides a way to analyze whether a given image was generated by a diffusion model or not.
Additionally, the paper draws connections to other relevant research, such as Beware Diffusion Models and Extracting Training Data, which also explore the potential for diffusion models to memorize and reproduce specific training data.
Critical Analysis
The paper raises important concerns about the potential misuse of unconditional latent diffusion models in medical applications, where the ability to accurately reconstruct individual patient images could pose significant privacy and security risks.
While the researchers' findings are compelling, it's worth noting that the study was limited to a specific set of medical imaging datasets and model architectures. The extent to which these results generalize to other medical imaging modalities or diffusion model variants remains to be seen.
Additionally, the paper does not delve deeply into the technical mechanisms underlying the observed memorization behavior. Further research may be needed to fully understand the factors that contribute to this phenomenon and to develop more robust solutions.
The proposed mitigation strategies, such as MemControl and Could It Be Generated, are promising, but their effectiveness and real-world applicability will need to be thoroughly evaluated.
Overall, this paper highlights an important issue that deserves further attention from the research community. As the use of diffusion models in medical applications continues to grow, it will be crucial to develop robust safeguards and best practices to ensure the privacy and security of patient data.
Conclusion
This paper presents a concerning finding about the ability of unconditional latent diffusion models to effectively memorize and reconstruct individual patient medical images. The researchers' work suggests that these models may pose significant risks in terms of patient privacy and data security, particularly in medical applications.
The paper also discusses potential mitigation strategies, such as MemControl and Could It Be Generated, which aim to reduce the risk of memorization and improve the trustworthiness of diffusion models in sensitive domains.
As diffusion models continue to advance and find wider applications, it will be crucial for the research community to address these challenges and ensure that the benefits of these powerful generative models are balanced against the need to protect sensitive data and preserve individual privacy. This paper serves as an important step in that direction, highlighting a critical issue that deserves further investigation and solution-oriented research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unconditional Latent Diffusion Models Memorize Patient Imaging Data: Implications for Openly Sharing Synthetic Data
Salman Ul Hassan Dar, Marvin Seyfarth, Jannik Kahmann, Isabelle Ayx, Theano Papavassiliu, Stefan O. Schoenberg, Norbert Frey, Bettina Bae{ss}ler, Sebastian Foersch, Daniel Truhn, Jakob Nikolas Kather, Sandy Engelhardt
AI models present a wide range of applications in the field of medicine. However, achieving optimal performance requires access to extensive healthcare data, which is often not readily available. Furthermore, the imperative to preserve patient privacy restricts patient data sharing with third parties and even within institutes. Recently, generative AI models have been gaining traction for facilitating open-data sharing by proposing synthetic data as surrogates of real patient data. Despite the promise, these models are susceptible to patient data memorization, where models generate patient data copies instead of novel synthetic samples. Considering the importance of the problem, it has received little attention in the medical imaging community. To this end, we assess memorization in unconditional latent diffusion models. We train 2D and 3D latent diffusion models on CT, MR, and X-ray datasets for synthetic data generation. Afterwards, we detect the amount of training data memorized utilizing our self-supervised approach and further investigate various factors that can influence memorization. Our findings show a surprisingly high degree of patient data memorization across all datasets, with approximately 40.9% of patient data being memorized and 78.5% of synthetic samples identified as patient data copies on average in our experiments. Further analyses reveal that using augmentation strategies during training can reduce memorization while over-training the models can enhance it. Although increasing the dataset size does not reduce memorization and might even enhance it, it does lower the probability of a synthetic sample being a patient data copy. Collectively, our results emphasize the importance of carefully training generative models on private medical imaging datasets, and examining the synthetic data to ensure patient privacy before sharing it for medical research and applications.
Read more7/16/2024
0
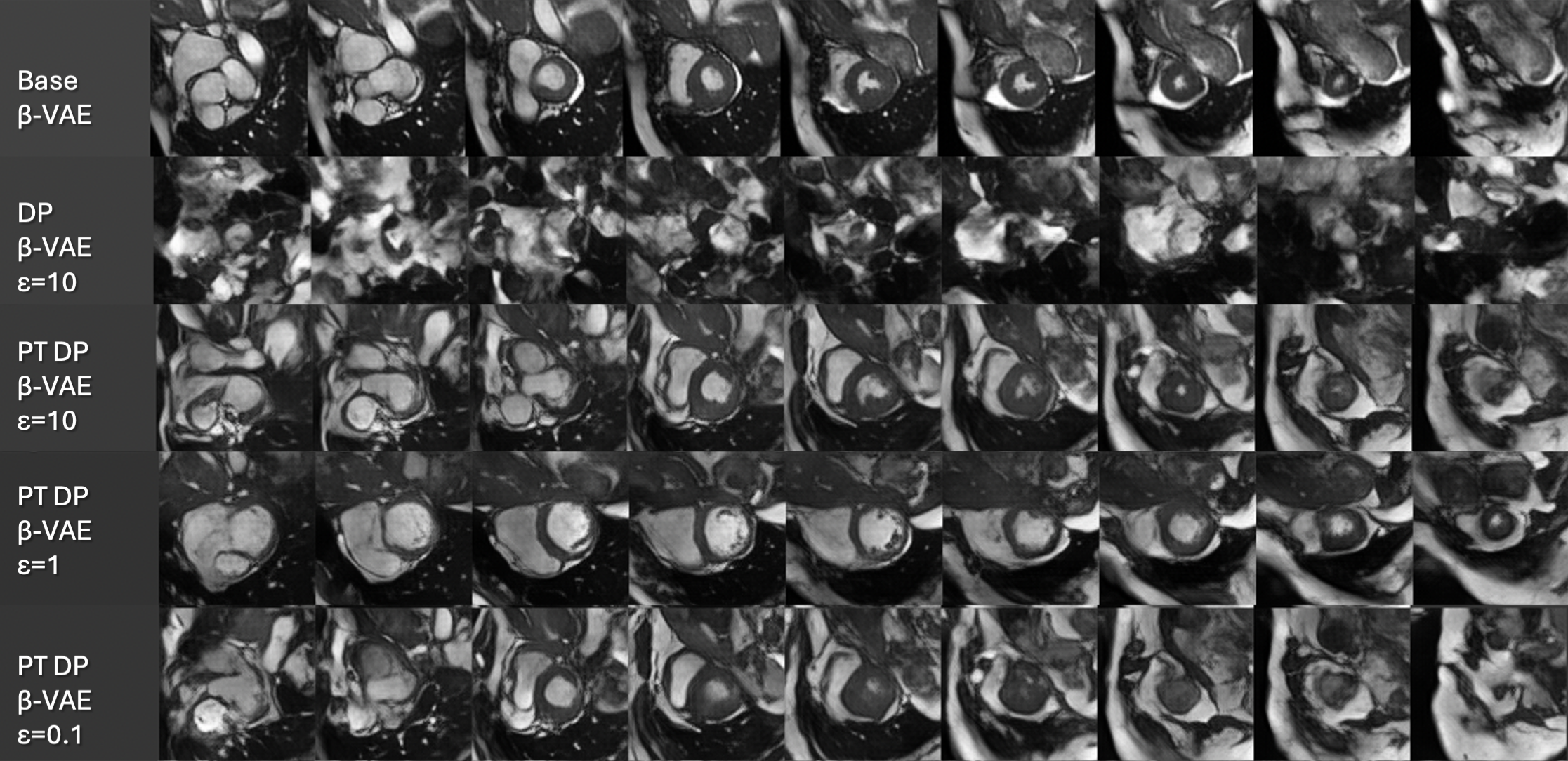
On Differentially Private 3D Medical Image Synthesis with Controllable Latent Diffusion Models
Deniz Daum, Richard Osuala, Anneliese Riess, Georgios Kaissis, Julia A. Schnabel, Maxime Di Folco
Generally, the small size of public medical imaging datasets coupled with stringent privacy concerns, hampers the advancement of data-hungry deep learning models in medical imaging. This study addresses these challenges for 3D cardiac MRI images in the short-axis view. We propose Latent Diffusion Models that generate synthetic images conditioned on medical attributes, while ensuring patient privacy through differentially private model training. To our knowledge, this is the first work to apply and quantify differential privacy in 3D medical image generation. We pre-train our models on public data and finetune them with differential privacy on the UK Biobank dataset. Our experiments reveal that pre-training significantly improves model performance, achieving a Fr'echet Inception Distance (FID) of 26.77 at $epsilon=10$, compared to 92.52 for models without pre-training. Additionally, we explore the trade-off between privacy constraints and image quality, investigating how tighter privacy budgets affect output controllability and may lead to degraded performance. Our results demonstrate that proper consideration during training with differential privacy can substantially improve the quality of synthetic cardiac MRI images, but there are still notable challenges in achieving consistent medical realism.
Read more7/24/2024
🐍
0
Beware of diffusion models for synthesizing medical images -- A comparison with GANs in terms of memorizing brain MRI and chest x-ray images
Muhammad Usman Akbar, Wuhao Wang, Anders Eklund
Diffusion models were initially developed for text-to-image generation and are now being utilized to generate high quality synthetic images. Preceded by GANs, diffusion models have shown impressive results using various evaluation metrics. However, commonly used metrics such as FID and IS are not suitable for determining whether diffusion models are simply reproducing the training images. Here we train StyleGAN and a diffusion model, using BRATS20, BRATS21 and a chest x-ray pneumonia dataset, to synthesize brain MRI and chest x-ray images, and measure the correlation between the synthetic images and all training images. Our results show that diffusion models are more likely to memorize the training images, compared to StyleGAN, especially for small datasets and when using 2D slices from 3D volumes. Researchers should be careful when using diffusion models (and to some extent GANs) for medical imaging, if the final goal is to share the synthetic images.
Read more7/9/2024

0
Extracting Training Data from Unconditional Diffusion Models
Yunhao Chen, Xingjun Ma, Difan Zou, Yu-Gang Jiang
As diffusion probabilistic models (DPMs) are being employed as mainstream models for generative artificial intelligence (AI), the study of their memorization of the raw training data has attracted growing attention. Existing works in this direction aim to establish an understanding of whether or to what extent DPMs learn by memorization. Such an understanding is crucial for identifying potential risks of data leakage and copyright infringement in diffusion models and, more importantly, for more controllable generation and trustworthy application of Artificial Intelligence Generated Content (AIGC). While previous works have made important observations of when DPMs are prone to memorization, these findings are mostly empirical, and the developed data extraction methods only work for conditional diffusion models. In this work, we aim to establish a theoretical understanding of memorization in DPMs with 1) a memorization metric for theoretical analysis, 2) an analysis of conditional memorization with informative and random labels, and 3) two better evaluation metrics for measuring memorization. Based on the theoretical analysis, we further propose a novel data extraction method called textbf{Surrogate condItional Data Extraction (SIDE)} that leverages a classifier trained on generated data as a surrogate condition to extract training data directly from unconditional diffusion models. Our empirical results demonstrate that SIDE can extract training data from diffusion models where previous methods fail, and it is on average over 50% more effective across different scales of the CelebA dataset.
Read more6/19/2024