Uncovering Biases with Reflective Large Language Models

0
💬
Sign in to get full access
Overview
- This paper explores how reflective large language models (LLMs) can be used to uncover biases in other LLMs.
- The key idea is to train a "mirror" model that can reflect the biases present in a target LLM, enabling deeper analysis and understanding.
- The authors demonstrate their approach on several well-known LLMs, revealing insights about the nature and sources of their biases.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at generating human-like text. However, these models can also pick up on and amplify biases present in their training data. This can lead to problematic outputs, such as text that exhibits racial, gender, or other harmful stereotypes.
The researchers in this paper propose a novel approach to uncover these biases. They train a special "mirror" model that is designed to reflect the biases of a target LLM. By analyzing the mirror model, the researchers can gain deeper insights into the specific biases present in the original LLM.
For example, the mirror model might reveal that the target LLM tends to associate certain occupations with particular genders. Or it might show that the LLM has a bias towards certain racial or ethnic groups. This type of detailed understanding is crucial for developing strategies to mitigate biases in LLMs and ensure they are used responsibly.
The researchers demonstrate their approach on several well-known LLMs, including GPT-3 and BERT. They show how the mirror models can uncover a range of biases, providing valuable information for researchers and developers working to build more ethical and inclusive AI systems.
Technical Explanation
The key innovation in this paper is the use of a "reflective" LLM to analyze the biases present in a target LLM. The researchers train this reflective model to mimic the behavior of the target model as closely as possible, including its biases and tendencies.
To do this, they first fine-tune the reflective model on a dataset of text generated by the target LLM. This allows the reflective model to learn the target model's language patterns, including any biases or stereotypes that may be present.
The researchers then examine the reflective model itself to uncover these biases. They analyze the model's attention weights, which indicate how much the model is focusing on different parts of the input when generating output. Patterns in the attention weights can reveal biases, such as the model focusing more on certain demographic groups when generating text about certain topics.
Additionally, the researchers use probing tasks to directly test the reflective model's understanding of concepts related to bias, such as gender and race. By examining the reflective model's performance on these tasks, they can gain further insights into the biases present in the target LLM.
Through experiments on models like GPT-3 and BERT, the researchers demonstrate the effectiveness of this reflective approach in uncovering a range of biases, from gender stereotypes to racial prejudices. This detailed understanding is a crucial step towards building more ethical and inclusive AI systems.
Critical Analysis
The researchers acknowledge several limitations and caveats in their work. First, the reflective model approach relies on the ability to closely mimic the target LLM, which may be challenging for larger or more complex models. Additionally, the probing tasks used to uncover biases are not exhaustive and may miss certain types of biases.
There are also open questions about the best way to interpret the insights gained from the reflective model. While the attention weights and probing task results provide valuable information, it's not always clear how to translate these findings into concrete strategies for mitigating biases.
Furthermore, the paper does not address the potential risks or unintended consequences of using reflective models to analyze LLMs. There are concerns about the privacy implications of generating text that closely matches a target model, as well as the possibility of the reflective model itself picking up and amplifying biases.
Despite these limitations, this work represents an important step forward in the effort to understand and address the biases present in large language models. By providing a systematic approach to uncovering these biases, the researchers are laying the groundwork for more responsible and ethical development of AI systems.
Conclusion
This paper introduces a novel approach to uncovering biases in large language models using reflective models. By training a mirror model to closely mimic the target LLM, the researchers are able to gain detailed insights into the specific biases and stereotypes present in the original model.
The findings from this work have significant implications for the development of more ethical and inclusive AI systems. By understanding the nature and sources of biases in LLMs, researchers and developers can work to mitigate these issues and ensure that these powerful models are used in a responsible and equitable manner.
Overall, this paper represents an important contribution to the growing field of AI bias research, and its insights will likely be valuable for a wide range of applications where large language models are used.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Uncovering Biases with Reflective Large Language Models
Edward Y. Chang
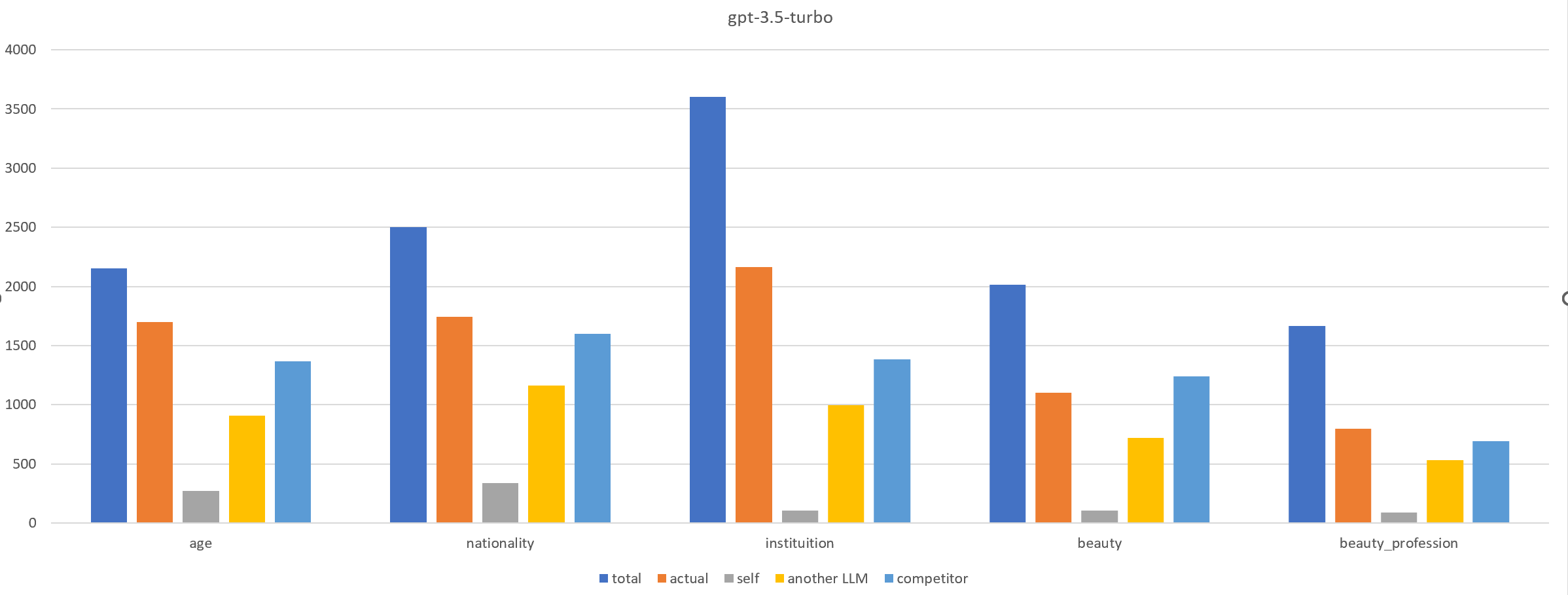
Biases inherent in human endeavors pose significant challenges for machine learning, particularly in supervised learning that relies on potentially biased ground truth data. This reliance, coupled with models' tendency to generalize based on statistical maximal likelihood, can propagate and amplify biases, exacerbating societal issues. To address this, our study proposes a reflective methodology utilizing multiple Large Language Models (LLMs) engaged in a dynamic dialogue to uncover diverse perspectives. By leveraging conditional statistics, information theory, and divergence metrics, this novel approach fosters context-dependent linguistic behaviors, promoting unbiased outputs. Furthermore, it enables measurable progress tracking and explainable remediation actions to address identified biases.
Read more8/27/2024
0
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Jiaqi Li, Aihua Pei, Zhiqiang Wang, Pengliang Ji, Haoyu Wang, Jiaqi Huo
Bias in LLMs can harm user experience and societal outcomes. However, current bias mitigation methods often require intensive human feedback, lack transferability to other topics or yield overconfident and random outputs. We find that involving LLMs in role-playing scenario boosts their ability to recognize and mitigate biases. Based on this, we propose Reinforcement Learning from Multi-role Debates as Feedback (RLDF), a novel approach for bias mitigation replacing human feedback in traditional RLHF. We utilize LLMs in multi-role debates to create a dataset that includes both high-bias and low-bias instances for training the reward model in reinforcement learning. Our approach comprises two modes: (1) self-reflection, where the same LLM participates in multi-role debates, and (2) teacher-student, where a more advanced LLM like GPT-3.5-turbo guides the LLM to perform this task. Experimental results across different LLMs demonstrate the effectiveness of our approach in bias mitigation.
Read more6/19/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024
💬
0
Exploring Subjectivity for more Human-Centric Assessment of Social Biases in Large Language Models
Paula Akemi Aoyagui, Sharon Ferguson, Anastasia Kuzminykh
An essential aspect of evaluating Large Language Models (LLMs) is identifying potential biases. This is especially relevant considering the substantial evidence that LLMs can replicate human social biases in their text outputs and further influence stakeholders, potentially amplifying harm to already marginalized individuals and communities. Therefore, recent efforts in bias detection invested in automated benchmarks and objective metrics such as accuracy (i.e., an LLMs output is compared against a predefined ground truth). Nonetheless, social biases can be nuanced, oftentimes subjective and context-dependent, where a situation is open to interpretation and there is no ground truth. While these situations can be difficult for automated evaluation systems to identify, human evaluators could potentially pick up on these nuances. In this paper, we discuss the role of human evaluation and subjective interpretation to augment automated processes when identifying biases in LLMs as part of a human-centred approach to evaluate these models.
Read more5/21/2024