Exploring Subjectivity for more Human-Centric Assessment of Social Biases in Large Language Models
2405.11048
0
0
💬
Abstract
An essential aspect of evaluating Large Language Models (LLMs) is identifying potential biases. This is especially relevant considering the substantial evidence that LLMs can replicate human social biases in their text outputs and further influence stakeholders, potentially amplifying harm to already marginalized individuals and communities. Therefore, recent efforts in bias detection invested in automated benchmarks and objective metrics such as accuracy (i.e., an LLMs output is compared against a predefined ground truth). Nonetheless, social biases can be nuanced, oftentimes subjective and context-dependent, where a situation is open to interpretation and there is no ground truth. While these situations can be difficult for automated evaluation systems to identify, human evaluators could potentially pick up on these nuances. In this paper, we discuss the role of human evaluation and subjective interpretation to augment automated processes when identifying biases in LLMs as part of a human-centred approach to evaluate these models.
Create account to get full access
Overview
- This paper explores the use of subjective human evaluations to assess social biases in large language models (LLMs), rather than relying solely on objective metrics.
- The authors argue that existing bias evaluation methods may not capture the nuanced and context-dependent nature of human perceptions of bias.
- They propose a new framework that incorporates both objective and subjective assessments, with the goal of developing more human-centric methods for evaluating the social impacts of LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. However, these models can sometimes exhibit biases, such as favoring certain genders or races over others. Traditionally, researchers have used objective metrics to measure and assess these biases.
The authors of this paper argue that these objective metrics may not tell the whole story. They suggest that human perceptions of bias can be more nuanced and context-dependent than what the numbers show. For example, a statement that may seem biased to one person may not be perceived as such by another.
To address this, the researchers propose a new framework that combines objective and subjective assessments of bias. They believe this approach can lead to a more comprehensive and human-centric understanding of the social impacts of LLMs.
By considering both the quantitative data and the subjective experiences of people, the researchers hope to develop better methods for evaluating and mitigating biases in these powerful AI systems. This could ultimately lead to the creation of more equitable and inclusive language models that are better aligned with human values.
Technical Explanation
The paper begins by discussing the limitations of existing approaches to evaluating social biases in large language models (LLMs). The authors argue that current methods, which rely heavily on objective metrics like word embedding associations, may not fully capture the nuanced, context-dependent nature of human perceptions of bias.
To address this, the researchers propose a new framework that incorporates both objective and subjective assessments of bias. The objective component involves applying established bias measurement techniques, such as those used in https://aimodels.fyi/papers/arxiv/large-language-models-are-inconsistent-biased-evaluators and https://aimodels.fyi/papers/arxiv/concerns-bias-large-language-models-when-creating.
The subjective component involves collecting human evaluations of bias, drawing inspiration from approaches like https://aimodels.fyi/papers/arxiv/rlrfreinforcement-learning-from-reflection-through-debates-as and https://aimodels.fyi/papers/arxiv/just-like-me-role-opinions-personal-experiences. The researchers conducted user studies to gather human assessments of bias in specific language model outputs, exploring factors such as personal experiences and opinions.
By combining these objective and subjective measures, the authors aim to develop a more holistic understanding of social biases in LLMs, as demonstrated in https://aimodels.fyi/papers/arxiv/bias-patterns-application-llms-clinical-decision-support. They believe this approach can lead to the creation of bias evaluation methods that are better aligned with human values and experiences.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their proposed framework. For example, they note that subjective evaluations of bias can be influenced by individual biases and backgrounds, which may introduce additional complexities to the assessment process.
Additionally, the researchers highlight the challenge of scaling up their approach to handle the vast amounts of data and language model outputs that need to be evaluated. Developing efficient and scalable methods for collecting and analyzing human-centric bias assessments remains an open challenge.
Another potential issue is the subjectivity of the human evaluations themselves. While the authors argue that this subjectivity is a strength of their approach, it also raises questions about the reliability and generalizability of the findings. Careful study design and statistical analysis will be crucial to ensure the robustness of the results.
Despite these limitations, the paper's focus on incorporating human perspectives into the assessment of social biases in LLMs is a valuable contribution to the field. By acknowledging the importance of subjective experiences, the authors encourage the AI research community to think more critically about the social impacts of these powerful language models and to develop more nuanced and inclusive evaluation methods.
Conclusion
This paper presents a novel framework for evaluating social biases in large language models (LLMs) that combines objective and subjective assessments. The authors argue that existing bias evaluation methods may not capture the full complexity of human perceptions of bias, which can be influenced by individual experiences and perspectives.
By incorporating both quantitative and qualitative measures, the proposed approach aims to develop a more human-centric understanding of the social impacts of LLMs. While the framework faces some challenges related to scalability and subjectivity, the authors' emphasis on the importance of human-centered evaluation is a valuable contribution to the ongoing discussion around the societal implications of these powerful AI systems.
As the development and deployment of LLMs continues to accelerate, the need for comprehensive, multifaceted bias assessment methods becomes increasingly crucial. This paper serves as an important step towards the creation of more equitable and inclusive language models that better align with human values and experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Ask LLMs Directly, What shapes your bias?: Measuring Social Bias in Large Language Models
Jisu Shin, Hoyun Song, Huije Lee, Soyeong Jeong, Jong C. Park
0
0
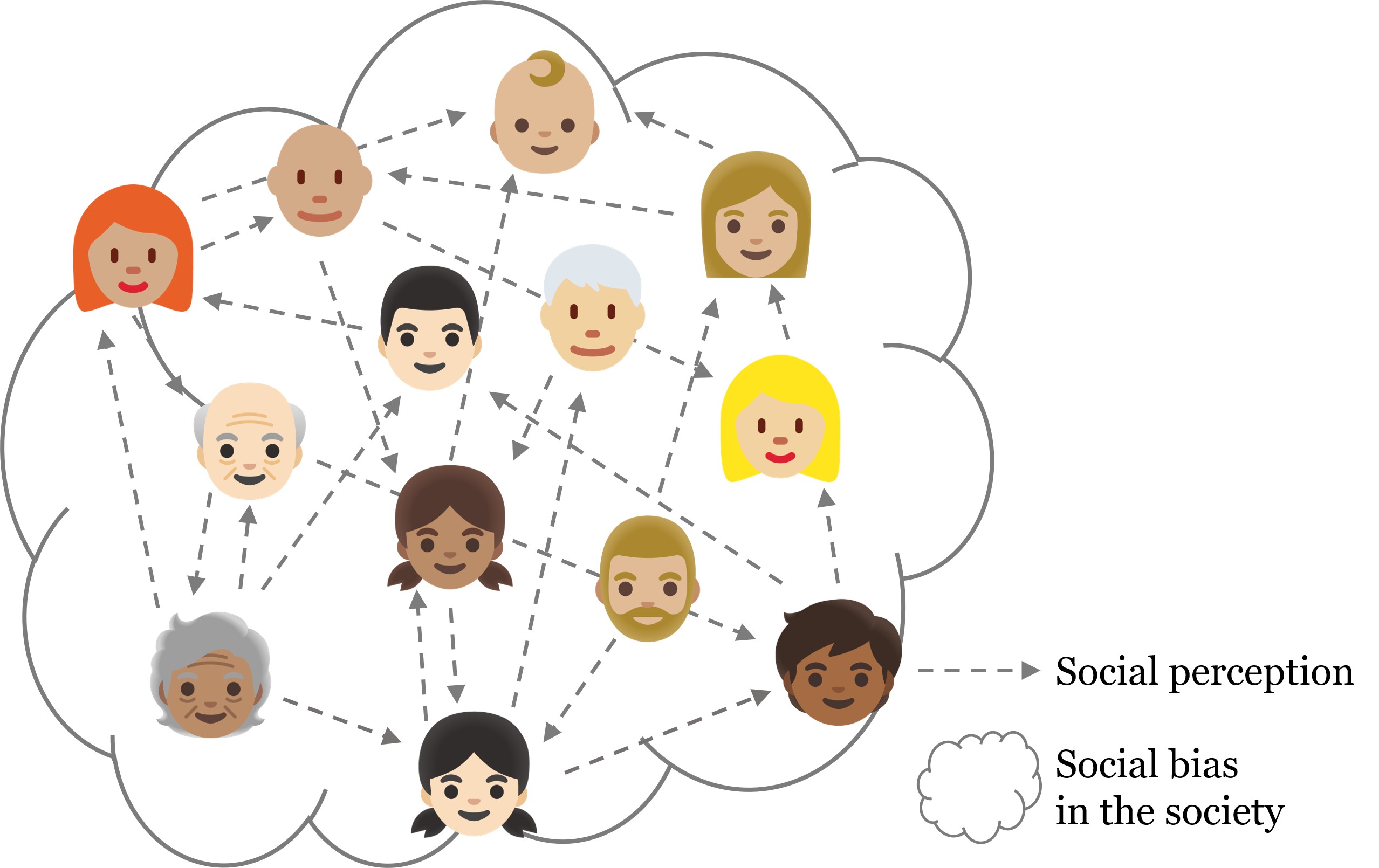
Social bias is shaped by the accumulation of social perceptions towards targets across various demographic identities. To fully understand such social bias in large language models (LLMs), it is essential to consider the composite of social perceptions from diverse perspectives among identities. Previous studies have either evaluated biases in LLMs by indirectly assessing the presence of sentiments towards demographic identities in the generated text or measuring the degree of alignment with given stereotypes. These methods have limitations in directly quantifying social biases at the level of distinct perspectives among identities. In this paper, we aim to investigate how social perceptions from various viewpoints contribute to the development of social bias in LLMs. To this end, we propose a novel strategy to intuitively quantify these social perceptions and suggest metrics that can evaluate the social biases within LLMs by aggregating diverse social perceptions. The experimental results show the quantitative demonstration of the social attitude in LLMs by examining social perception. The analysis we conducted shows that our proposed metrics capture the multi-dimensional aspects of social bias, enabling a fine-grained and comprehensive investigation of bias in LLMs.
6/7/2024
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
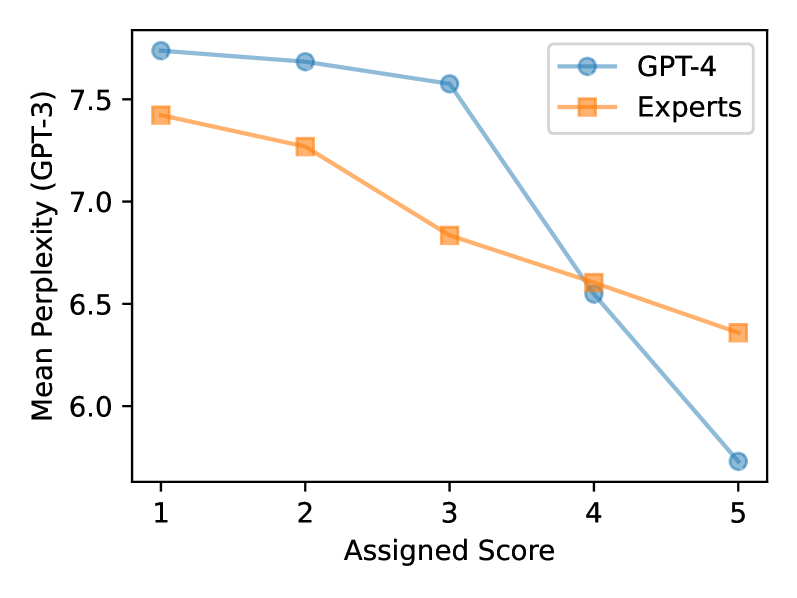
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024
💬
Concerns on Bias in Large Language Models when Creating Synthetic Personae
Helena A. Haxvig
0
0
This position paper explores the benefits, drawbacks, and ethical considerations of incorporating synthetic personae in HCI research, particularly focusing on the customization challenges beyond the limitations of current Large Language Models (LLMs). These perspectives are derived from the initial results of a sub-study employing vignettes to showcase the existence of bias within black-box LLMs and explore methods for manipulating them. The study aims to establish a foundation for understanding the challenges associated with these models, emphasizing the necessity of thorough testing before utilizing them to create synthetic personae for HCI research.
5/9/2024
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Jiaqi Li, Aihua Pei, Zhiqiang Wang, Pengliang Ji, Haoyu Wang, Jiaqi Huo
0
0
Bias in LLMs can harm user experience and societal outcomes. However, current bias mitigation methods often require intensive human feedback, lack transferability to other topics or yield overconfident and random outputs. We find that involving LLMs in role-playing scenario boosts their ability to recognize and mitigate biases. Based on this, we propose Reinforcement Learning from Multi-role Debates as Feedback (RLDF), a novel approach for bias mitigation replacing human feedback in traditional RLHF. We utilize LLMs in multi-role debates to create a dataset that includes both high-bias and low-bias instances for training the reward model in reinforcement learning. Our approach comprises two modes: (1) self-reflection, where the same LLM participates in multi-role debates, and (2) teacher-student, where a more advanced LLM like GPT-3.5-turbo guides the LLM to perform this task. Experimental results across different LLMs demonstrate the effectiveness of our approach in bias mitigation.
6/19/2024