Understanding Auditory Evoked Brain Signal via Physics-informed Embedding Network with Multi-Task Transformer

0
🤔
Sign in to get full access
Overview
- This blog post provides a plain English summary, technical explanation, and critical analysis of several research papers on topics related to neural decoding, sound field modeling, speech recognition, and brain function modeling.
- The papers covered include Open Vocabulary Auditory Neural Decoding Using fMRI, Physics-Informed Neural Network for Volumetric Sound Field Modeling, Transducers: Pronunciation-Aware Embeddings for Automatic Speech Recognition, Foundational GPT Model for MEG, and BrainFormer: Mimic Human Visual Brain Functions to Improve Visual Recognition.
Plain English Explanation
The research papers covered in this post explore various ways that artificial intelligence (AI) and machine learning (ML) can be used to better understand and model human brain functions and perception.
One paper looks at how fMRI data, which measures brain activity, can be used to decode the sounds a person is listening to. This could have applications in brain-computer interfaces or assistive technologies for people with hearing impairments.
Another paper presents a new way to model the 3D sound fields produced by loudspeakers or other audio devices using physics-informed neural networks. This could lead to improved audio rendering and spatial audio applications.
The paper on "Transducers" describes a technique for improving speech recognition systems by incorporating information about how words are pronounced. This helps the models better understand the nuances of human speech.
The "Foundational GPT Model for MEG" paper demonstrates how large language models like GPT can be adapted to work with brain imaging data from magnetoencephalography (MEG), providing a powerful tool for studying brain function.
Finally, the "BrainFormer" paper explores how AI models can be designed to mimic the way the human visual system processes information, potentially leading to more robust and human-like machine vision capabilities.
Overall, these papers illustrate the exciting progress being made at the intersection of neuroscience, signal processing, and artificial intelligence, with the potential to unlock new technologies and insights about ourselves.
Technical Explanation
The Open Vocabulary Auditory Neural Decoding Using fMRI paper presents a method for decoding the auditory stimuli that a person is listening to from their brain activity measured using functional magnetic resonance imaging (fMRI). The key innovation is the use of a transformer-based language model that can map the fMRI data to open-vocabulary audio concepts, rather than being limited to a fixed set of sounds. This allows the model to generalize to a much wider range of stimuli.
The Physics-Informed Neural Network for Volumetric Sound Field Modeling paper introduces a new neural network architecture that can accurately model the 3D sound fields produced by audio devices like loudspeakers. By incorporating the underlying physical principles of wave propagation, the model is able to generate high-fidelity sound field predictions from relatively sparse input data, enabling applications in spatial audio, room acoustics simulation, and audio rendering.
The Transducers: Pronunciation-Aware Embeddings for Automatic Speech Recognition paper describes a novel speech recognition model that learns "transducer" embeddings - representations that capture both the orthographic and phonetic characteristics of words. This allows the model to better handle pronunciation variations, out-of-vocabulary words, and other challenges in real-world speech, leading to improved performance on automatic speech recognition tasks.
The Foundational GPT Model for MEG paper demonstrates how large language models like GPT can be adapted to work with magnetoencephalography (MEG) brain imaging data. The authors show that this "Foundational GPT" model can be used to predict MEG signals from text inputs, and vice versa, providing a powerful tool for studying the neural representations underlying language and cognition.
Finally, the BrainFormer: Mimic Human Visual Brain Functions to Improve Visual Recognition paper presents an AI model architecture inspired by the human visual system. By incorporating mechanisms like attention, lateral connections, and predictive coding, the "BrainFormer" model is able to achieve state-of-the-art performance on various computer vision tasks while also providing insights into the computational principles underlying biological vision.
Critical Analysis
The research presented in these papers represents exciting progress in our understanding of the brain and our ability to model its functions using advanced AI and machine learning techniques. However, it's important to note some of the limitations and caveats of the work.
For the Open Vocabulary Auditory Neural Decoding research, the use of fMRI data, while valuable, is limited by its relatively low temporal resolution compared to other brain imaging modalities like EEG or MEG. Additionally, the decoding of open-vocabulary auditory concepts from fMRI data, while a significant advancement, still has room for improvement in terms of accuracy and generalization.
The Physics-Informed Neural Network for Volumetric Sound Field Modeling paper presents a promising approach, but the validation was primarily done in simulation, and real-world deployment would likely require further refinement and testing.
The Transducers paper demonstrates the potential of incorporating pronunciation information into speech recognition models, but the performance improvements were tested on a limited set of tasks and datasets. Broader evaluation would be needed to fully assess the generalizability of the approach.
The Foundational GPT Model for MEG research is an exciting step towards bridging the gap between language models and brain imaging, but the interpretation of the neural representations learned by the model would benefit from further investigation and validation.
Finally, while the BrainFormer paper demonstrates impressive results on computer vision tasks, the extent to which the model actually captures the underlying principles of biological vision remains an open question that requires more analysis and empirical validation.
Overall, these papers highlight the tremendous potential of AI and machine learning in neuroscience and brain-inspired computing, but also underscores the need for continued research, rigorous validation, and a critical eye towards the limitations and potential pitfalls of these approaches.
Conclusion
The research papers covered in this blog post illustrate the exciting progress being made at the intersection of artificial intelligence, neuroscience, and signal processing. By leveraging advanced machine learning techniques, researchers are developing new methods for decoding brain activity, modeling acoustic phenomena, improving speech recognition, and gaining insights into the computational principles underlying human perception and cognition.
These advancements have the potential to unlock a wide range of applications, from brain-computer interfaces and assistive technologies to immersive audio experiences and more human-like artificial intelligence. However, as with any rapidly advancing field, it's important to maintain a critical perspective, carefully evaluate the strengths and limitations of the research, and continue to push the boundaries of what's possible through rigorous scientific inquiry.
As these technologies continue to evolve, it will be crucial for researchers, developers, and the general public to engage in thoughtful discussions about the ethical and societal implications of these innovations. By doing so, we can ensure that the remarkable progress being made in these areas ultimately benefits humanity as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Understanding Auditory Evoked Brain Signal via Physics-informed Embedding Network with Multi-Task Transformer
Wanli Ma, Xuegang Tang, Jin Gu, Ying Wang, Yuling Xia
In the fields of brain-computer interaction and cognitive neuroscience, effective decoding of auditory signals from task-based functional magnetic resonance imaging (fMRI) is key to understanding how the brain processes complex auditory information. Although existing methods have enhanced decoding capabilities, limitations remain in information utilization and model representation. To overcome these challenges, we propose an innovative multi-task learning model, Physics-informed Embedding Network with Multi-Task Transformer (PEMT-Net), which enhances decoding performance through physics-informed embedding and deep learning techniques. PEMT-Net consists of two principal components: feature augmentation and classification. For feature augmentation, we propose a novel approach by creating neural embedding graphs via node embedding, utilizing random walks to simulate the physical diffusion of neural information. This method captures both local and non-local information overflow and proposes a position encoding based on relative physical coordinates. In the classification segment, we propose adaptive embedding fusion to maximally capture linear and non-linear characteristics. Furthermore, we propose an innovative parameter-sharing mechanism to optimize the retention and learning of extracted features. Experiments on a specific dataset demonstrate PEMT-Net's significant performance in multi-task auditory signal decoding, surpassing existing methods and offering new insights into the brain's mechanisms for processing complex auditory information.
Read more6/5/2024
🧠
0
Open-vocabulary Auditory Neural Decoding Using fMRI-prompted LLM
Xiaoyu Chen, Changde Du, Che Liu, Yizhe Wang, Huiguang He
Decoding language information from brain signals represents a vital research area within brain-computer interfaces, particularly in the context of deciphering the semantic information from the fMRI signal. However, many existing efforts concentrate on decoding small vocabulary sets, leaving space for the exploration of open vocabulary continuous text decoding. In this paper, we introduce a novel method, the textbf{Brain Prompt GPT (BP-GPT)}. By using the brain representation that is extracted from the fMRI as a prompt, our method can utilize GPT-2 to decode fMRI signals into stimulus text. Further, we introduce a text-to-text baseline and align the fMRI prompt to the text prompt. By introducing the text-to-text baseline, our BP-GPT can extract a more robust brain prompt and promote the decoding of pre-trained LLM. We evaluate our BP-GPT on the open-source auditory semantic decoding dataset and achieve a significant improvement up to $4.61%$ on METEOR and $2.43%$ on BERTScore across all the subjects compared to the state-of-the-art method. The experimental results demonstrate that using brain representation as a prompt to further drive LLM for auditory neural decoding is feasible and effective.
Read more5/14/2024
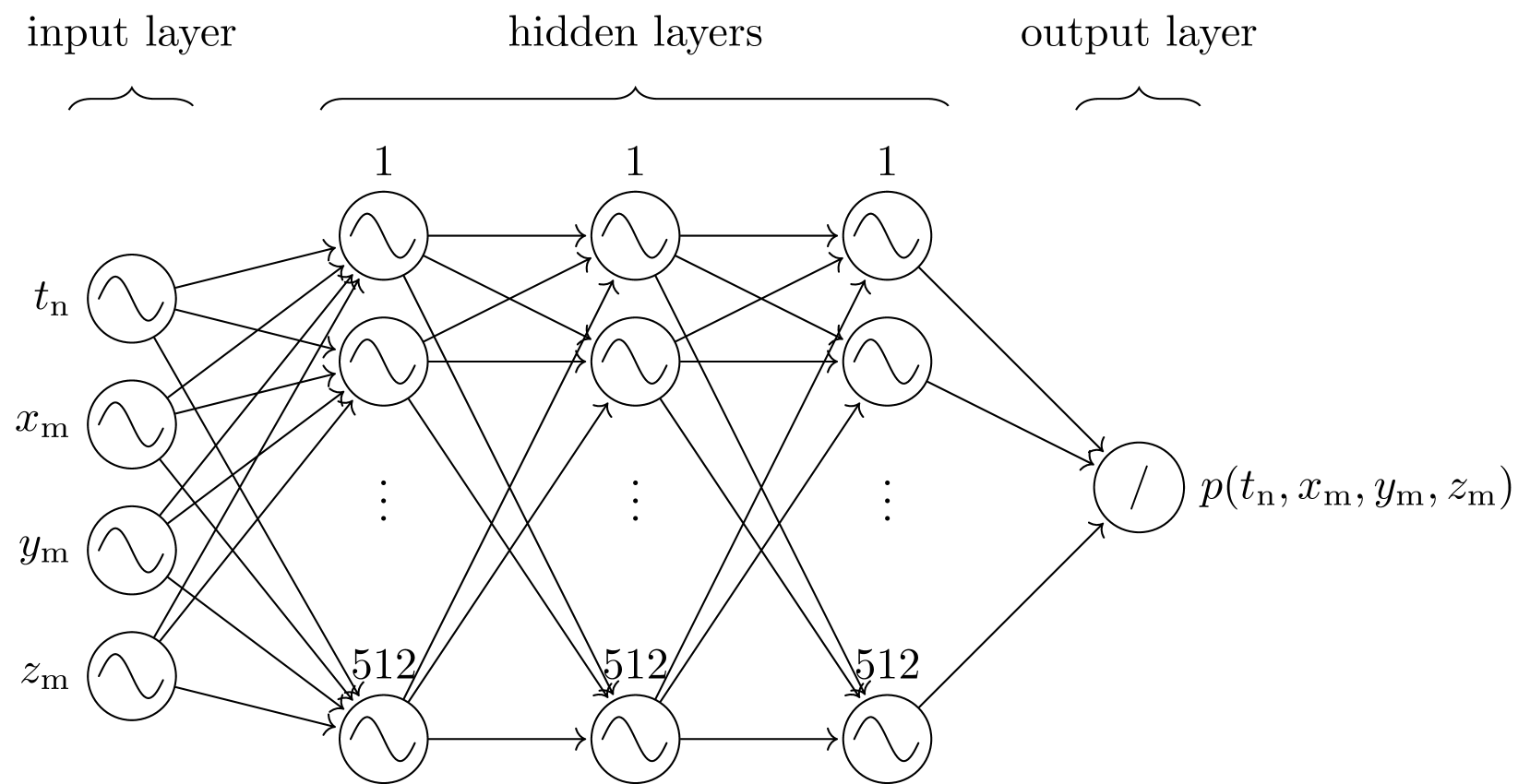
0
Physics-Informed Neural Network for Volumetric Sound field Reconstruction of Speech Signals
Marco Olivieri, Xenofon Karakonstantis, Mirco Pezzoli, Fabio Antonacci, Augusto Sarti, Efren Fernandez-Grande
Recent developments in acoustic signal processing have seen the integration of deep learning methodologies, alongside the continued prominence of classical wave expansion-based approaches, particularly in sound field reconstruction. Physics-Informed Neural Networks (PINNs) have emerged as a novel framework, bridging the gap between data-driven and model-based techniques for addressing physical phenomena governed by partial differential equations. This paper introduces a PINN-based approach for the recovery of arbitrary volumetric acoustic fields. The network incorporates the wave equation to impose a regularization on signal reconstruction in the time domain. This methodology enables the network to learn the underlying physics of sound propagation and allows for the complete characterization of the sound field based on a limited set of observations. The proposed method's efficacy is validated through experiments involving speech signals in a real-world environment, considering varying numbers of available measurements. Moreover, a comparative analysis is undertaken against state-of-the-art frequency-domain and time-domain reconstruction methods from existing literature, highlighting the increased accuracy across the various measurement configurations.
Read more4/24/2024

0
Point Neuron Learning: A New Physics-Informed Neural Network Architecture
Hanwen Bi, Thushara D. Abhayapala
Machine learning and neural networks have advanced numerous research domains, but challenges such as large training data requirements and inconsistent model performance hinder their application in certain scientific problems. To overcome these challenges, researchers have investigated integrating physics principles into machine learning models, mainly through: (i) physics-guided loss functions, generally termed as physics-informed neural networks, and (ii) physics-guided architectural design. While both approaches have demonstrated success across multiple scientific disciplines, they have limitations including being trapped to a local minimum, poor interpretability, and restricted generalizability. This paper proposes a new physics-informed neural network (PINN) architecture that combines the strengths of both approaches by embedding the fundamental solution of the wave equation into the network architecture, enabling the learned model to strictly satisfy the wave equation. The proposed point neuron learning method can model an arbitrary sound field based on microphone observations without any dataset. Compared to other PINN methods, our approach directly processes complex numbers and offers better interpretability and generalizability. We evaluate the versatility of the proposed architecture by a sound field reconstruction problem in a reverberant environment. Results indicate that the point neuron method outperforms two competing methods and can efficiently handle noisy environments with sparse microphone observations.
Read more9/2/2024