Understanding Catastrophic Forgetting in Language Models via Implicit Inference
2309.10105
0
0

Abstract
We lack a systematic understanding of the effects of fine-tuning (via methods such as instruction-tuning or reinforcement learning from human feedback), particularly on tasks outside the narrow fine-tuning distribution. In a simplified scenario, we demonstrate that improving performance on tasks within the fine-tuning data distribution comes at the expense of capabilities on other tasks. We hypothesize that language models implicitly infer the task of the prompt and that fine-tuning skews this inference towards tasks in the fine-tuning distribution. To test this, we propose Conjugate Prompting, which artificially makes the task look farther from the fine-tuning distribution while requiring the same capability, and we find that this recovers some of the pretraining capabilities in our synthetic setup. Since real-world fine-tuning distributions are predominantly English, we apply conjugate prompting to recover pretrained capabilities in LLMs by simply translating the prompts to different languages. This allows us to recover in-context learning abilities lost via instruction tuning, natural reasoning capability lost during code fine-tuning, and, more concerningly, harmful content generation suppressed by safety fine-tuning in chatbots like ChatGPT.
Create account to get full access
Overview
- This paper investigates the phenomenon of catastrophic forgetting in language models, where models trained on a new task tend to forget previous knowledge.
- The researchers use linear regression experiments to study this issue, examining how well language models can learn and retain new linear functions.
- They find that language models exhibit implicit inference, where they learn the underlying linear relationship rather than just memorizing the input-output pairs.
- This implicit learning leads to less catastrophic forgetting compared to models that simply memorize the training data.
Plain English Explanation
The paper looks at a problem called "catastrophic forgetting" that can happen with language models. Catastrophic forgetting is when a model trained on a new task forgets what it had learned before.
The researchers use simple linear regression experiments to study this issue. They train language models to learn linear functions, which are mathematical equations that describe a straight line. The models have to learn these functions from examples of input-output pairs.
The key finding is that language models don't just memorize the training examples. Instead, they seem to
This implicit learning helps the models retain more of their previous knowledge when learning new things. They don't suffer as much catastrophic forgetting compared to models that simply memorize the training data.
The findings suggest that the way language models learn - by inferring patterns rather than just memorizing - makes them more robust to forgetting past knowledge. This could have important implications for continual learning in language models and how we design AI systems that can learn and adapt over time without losing critical information.
Technical Explanation
The paper explores catastrophic forgetting in language models using a series of linear regression experiments. The researchers set up a task where language models have to learn linear functions from examples of input-output pairs.
They find that language models exhibit "implicit inference" - they don't simply memorize the training examples, but instead learn the underlying linear relationship. This allows the models to better retain previous knowledge when learning new tasks, compared to models that just memorize the training data.
Specifically, the researchers train language models on a sequence of linear functions. They observe that models that perform implicit inference, rather than pure memorization, experience less catastrophic forgetting. The models are able to leverage their understanding of the linear patterns to adapt to new functions, rather than completely overwriting their previous knowledge.
These findings connect to prior work on the role of context learning in language models and the limitations of context learning. The implicit inference exhibited by the language models in this study suggests a more sophisticated learning process than simple context memorization.
The results have implications for continual learning in language models and highlight the importance of understanding how these models
Critical Analysis
The paper provides valuable insights into the learning dynamics of language models, but there are a few limitations and open questions worth considering:
The experiments are restricted to linear regression, which is a relatively simple task compared to the full breadth of language understanding. It remains to be seen whether the implicit inference phenomenon observed here extends to more complex language modeling challenges.
Additionally, the experiments use relatively small-scale language models. It's unclear if the same patterns would hold for larger, more powerful models that are more representative of modern language AI systems. Further research on catastrophic forgetting in large language models would help validate and expand on these findings.
The paper also does not deeply explore the mechanisms underlying the implicit inference process. A more detailed investigation into how language models extract and represent the underlying patterns in the data could lead to important insights about their learning capabilities and limitations.
Overall, this work takes an important step in understanding catastrophic forgetting in language models, but there is still much to be explored in terms of the broader applicability of these ideas and the precise cognitive processes involved.
Conclusion
This paper provides valuable insights into the phenomenon of catastrophic forgetting in language models, using linear regression experiments to demonstrate that models can engage in "implicit inference" rather than simply memorizing training data.
The key finding is that this implicit learning approach allows language models to better retain previous knowledge when adapting to new tasks, compared to models that merely memorize examples. This suggests that the way language models learn - by extracting underlying patterns rather than just remembering specific inputs and outputs - confers important advantages in terms of continual learning and knowledge retention.
These results have important implications for the design of robust and adaptable language AI systems. By understanding the learning dynamics at play, researchers can work to mitigate catastrophic forgetting and develop models that can flexibly acquire new capabilities without losing critical prior knowledge. Further exploration of these ideas in larger, more complex language models will be an important area of future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
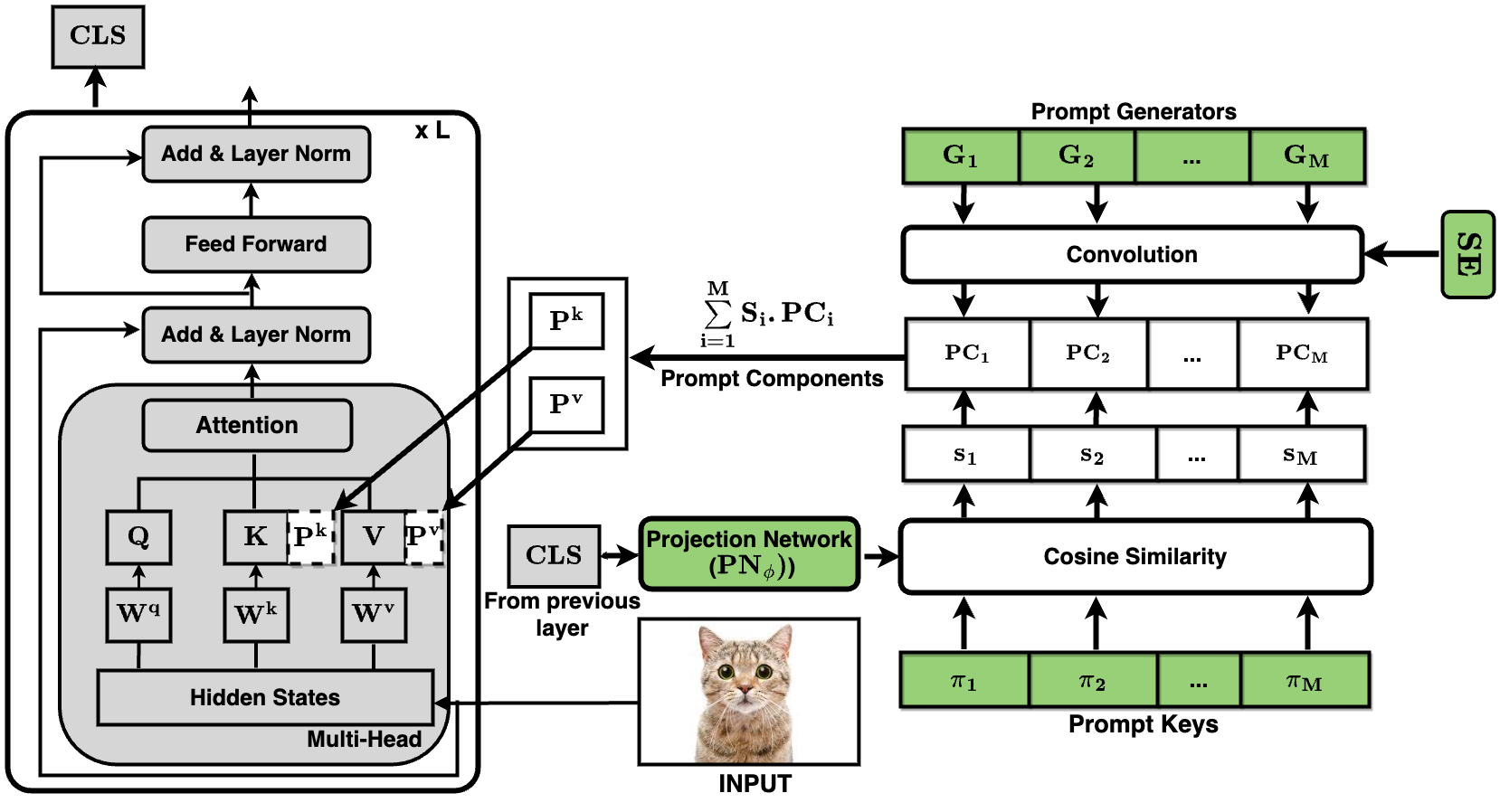
Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy, Riddhiman Moulick, Vinay K. Verma, Saptarshi Ghosh, Abir Das
0
0
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pretrained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by ~3% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components.
4/1/2024

Interpretable Catastrophic Forgetting of Large Language Model Fine-tuning via Instruction Vector
Gangwei Jiang, Caigao Jiang, Zhaoyi Li, Siqiao Xue, Jun Zhou, Linqi Song, Defu Lian, Ying Wei
0
0
Fine-tuning large language models (LLMs) can cause them to lose their general capabilities. However, the intrinsic mechanisms behind such forgetting remain unexplored. In this paper, we begin by examining this phenomenon by focusing on knowledge understanding and instruction following, with the latter identified as the main contributor to forgetting during fine-tuning. Consequently, we propose the Instruction Vector (IV) framework to capture model representations highly related to specific instruction-following capabilities, thereby making it possible to understand model-intrinsic forgetting. Through the analysis of IV dynamics pre and post-training, we suggest that fine-tuning mostly adds specialized reasoning patterns instead of erasing previous skills, which may appear as forgetting. Building on this insight, we develop IV-guided training, which aims to preserve original computation graph, thereby mitigating catastrophic forgetting. Empirical tests on three benchmarks confirm the efficacy of this new approach, supporting the relationship between IVs and forgetting. Our code will be made available soon.
6/26/2024
🌿
When Do Prompting and Prefix-Tuning Work? A Theory of Capabilities and Limitations
Aleksandar Petrov, Philip H. S. Torr, Adel Bibi
0
0
Context-based fine-tuning methods, including prompting, in-context learning, soft prompting (also known as prompt tuning), and prefix-tuning, have gained popularity due to their ability to often match the performance of full fine-tuning with a fraction of the parameters. Despite their empirical successes, there is little theoretical understanding of how these techniques influence the internal computation of the model and their expressiveness limitations. We show that despite the continuous embedding space being more expressive than the discrete token space, soft-prompting and prefix-tuning are potentially less expressive than full fine-tuning, even with the same number of learnable parameters. Concretely, context-based fine-tuning cannot change the relative attention pattern over the content and can only bias the outputs of an attention layer in a fixed direction. This suggests that while techniques like prompting, in-context learning, soft prompting, and prefix-tuning can effectively elicit skills present in the pretrained model, they may not be able to learn novel tasks that require new attention patterns.
4/10/2024
Language Models for Text Classification: Is In-Context Learning Enough?
Aleksandra Edwards, Jose Camacho-Collados
0
0
Recent foundational language models have shown state-of-the-art performance in many NLP tasks in zero- and few-shot settings. An advantage of these models over more standard approaches based on fine-tuning is the ability to understand instructions written in natural language (prompts), which helps them generalise better to different tasks and domains without the need for specific training data. This makes them suitable for addressing text classification problems for domains with limited amounts of annotated instances. However, existing research is limited in scale and lacks understanding of how text generation models combined with prompting techniques compare to more established methods for text classification such as fine-tuning masked language models. In this paper, we address this research gap by performing a large-scale evaluation study for 16 text classification datasets covering binary, multiclass, and multilabel problems. In particular, we compare zero- and few-shot approaches of large language models to fine-tuning smaller language models. We also analyse the results by prompt, classification type, domain, and number of labels. In general, the results show how fine-tuning smaller and more efficient language models can still outperform few-shot approaches of larger language models, which have room for improvement when it comes to text classification.
4/16/2024