UniDEC : Unified Dual Encoder and Classifier Training for Extreme Multi-Label Classification

0

Sign in to get full access
Overview
- Presents a unified training framework called UniDEC for extreme multi-label classification
- UniDEC combines dual encoder and multi-label classifier training in a single architecture
- Aims to address the challenges of extreme multi-label classification, where the number of labels can be very large
Plain English Explanation
UniDEC is a new approach for tackling the problem of extreme multi-label classification, where an item can be associated with a large number of possible labels. This is a common challenge in many real-world applications, such as ICXML-Context Learning Framework for Zero-Shot Extreme and Positive Label is All You Need for Multi.
The key idea behind UniDEC is to combine two important components in a single unified framework: a dual encoder that learns effective representations of the input, and a multi-label classifier that can handle the large number of possible labels. By training these components jointly, the model can learn more effective representations that are tailored for the specific classification task at hand.
This approach aims to address some of the challenges faced by existing methods, such as the need for complex architectures or separate training of different components. UniDEC provides a simpler and more efficient way to tackle extreme multi-label classification, potentially leading to improved performance and easier deployment in real-world applications.
Technical Explanation
The UniDEC framework Masked Two-Channel Decoupling Framework for Incomplete Multi consists of two main components:
-
Dual Encoder: This component learns effective representations of the input data, such as text or images, by using a dual encoding architecture. The encoders can be pre-trained on large-scale datasets and then fine-tuned for the specific multi-label classification task.
-
Multi-Label Classifier: The classifier module takes the learned representations from the dual encoder and outputs predictions for the relevant labels. The authors explore different approaches for the classifier, including attention-based and transformer-based models, to handle the large number of labels efficiently.
The key innovation of UniDEC is that these two components are trained jointly in a unified framework, rather than being trained separately. This allows the dual encoder to learn representations that are specifically tailored for the multi-label classification task, and the classifier to be optimized for the given input representations.
The authors How to Encode Domain Information for Relation Classification evaluate UniDEC on several benchmark datasets for extreme multi-label classification and demonstrate its effectiveness compared to existing state-of-the-art methods.
Critical Analysis
The paper provides a comprehensive evaluation of UniDEC and shows its promising performance on a range of extreme multi-label classification benchmarks. However, there are a few potential limitations and areas for further research:
-
The authors acknowledge that the performance of UniDEC is still dependent on the quality of the pre-trained encoders used. Exploring methods to Data-Efficient Multimodal Fusion on a Single GPU can help reduce the reliance on large-scale pre-training and make the approach more data-efficient.
-
The authors focus on textual and image-based multi-label classification tasks. It would be interesting to see how UniDEC performs on other types of data, such as structured or multimodal data, and whether the unified training framework can be generalized to these domains.
-
While the paper presents extensive experimental results, a deeper analysis of the learned representations and the inner workings of the dual encoder and classifier components could provide additional insights into the strengths and limitations of the approach.
Overall, the UniDEC framework presents a promising and versatile approach for tackling the challenges of extreme multi-label classification, and the paper makes a valuable contribution to the field.
Conclusion
The UniDEC framework proposed in this paper offers a novel and effective solution for extreme multi-label classification tasks. By unifying the training of a dual encoder and a multi-label classifier, the approach can learn representations that are tailored for the specific classification problem at hand, leading to improved performance compared to existing methods.
The authors' comprehensive evaluation and analysis demonstrate the potential of UniDEC to address the challenges posed by large-scale multi-label classification, with applications in areas such as ICXML-Context Learning Framework for Zero-Shot Extreme, Positive Label is All You Need for Multi, and Masked Two-Channel Decoupling Framework for Incomplete Multi. The unified training approach and the versatility of the framework suggest that UniDEC could have a significant impact on real-world applications that require efficient and effective multi-label classification.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UniDEC : Unified Dual Encoder and Classifier Training for Extreme Multi-Label Classification
Siddhant Kharbanda, Devaansh Gupta, Gururaj K, Pankaj Malhotra, Cho-Jui Hsieh, Rohit Babbar
Extreme Multi-label Classification (XMC) involves predicting a subset of relevant labels from an extremely large label space, given an input query and labels with textual features. Models developed for this problem have conventionally used modular approach with (i) a Dual Encoder (DE) to embed the queries and label texts, (ii) a One-vs-All classifier to rerank the shortlisted labels mined through meta-classifier training. While such methods have shown empirical success, we observe two key uncharted aspects, (i) DE training typically uses only a single positive relation even for datasets which offer more, (ii) existing approaches fixate on using only OvA reduction of the multi-label problem. This work aims to explore these aspects by proposing UniDEC, a novel end-to-end trainable framework which trains the dual encoder and classifier in together in a unified fashion using a multi-class loss. For the choice of multi-class loss, the work proposes a novel pick-some-label (PSL) reduction of the multi-label problem with leverages multiple (in come cases, all) positives. The proposed framework achieves state-of-the-art results on a single GPU, while achieving on par results with respect to multi-GPU SOTA methods on various XML benchmark datasets, all while using 4-16x lesser compute and being practically scalable even beyond million label scale datasets.
Read more5/8/2024

0
Zero-Shot Learning Over Large Output Spaces : Utilizing Indirect Knowledge Extraction from Large Language Models
Jinbin Zhang, Nasib Ullah, Rohit Babbar
Extreme Multi-label Learning (XMC) is a task that allocates the most relevant labels for an instance from a predefined label set. Extreme Zero-shot XMC (EZ-XMC) is a special setting of XMC wherein no supervision is provided; only the instances (raw text of the document) and the predetermined label set are given. The scenario is designed to address cold-start problems in categorization and recommendation. Traditional state-of-the-art methods extract pseudo labels from the document title or segments. These labels from the document are used to train a zero-shot bi-encoder model. The main issue with these generated labels is their misalignment with the tagging task. In this work, we propose a framework to train a small bi-encoder model via the feedback from the large language model (LLM), the bi-encoder model encodes the document and labels into embeddings for retrieval. Our approach leverages the zero-shot ability of LLM to assess the correlation between labels and the document instead of using the low-quality labels extracted from the document itself. Our method also guarantees fast inference without the involvement of LLM. The performance of our approach outperforms the SOTA methods on various datasets while retaining a similar training time for large datasets.
Read more6/14/2024
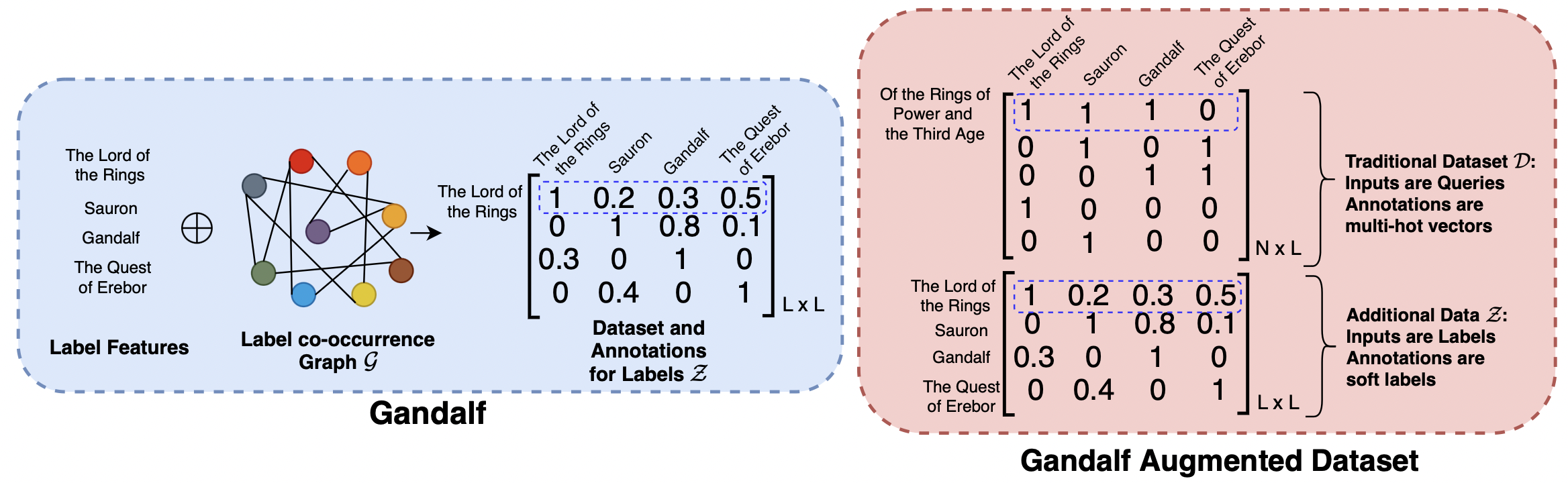
0
Learning label-label correlations in Extreme Multi-label Classification via Label Features
Siddhant Kharbanda, Devaansh Gupta, Erik Schultheis, Atmadeep Banerjee, Cho-Jui Hsieh, Rohit Babbar
Extreme Multi-label Text Classification (XMC) involves learning a classifier that can assign an input with a subset of most relevant labels from millions of label choices. Recent works in this domain have increasingly focused on a symmetric problem setting where both input instances and label features are short-text in nature. Short-text XMC with label features has found numerous applications in areas such as query-to-ad-phrase matching in search ads, title-based product recommendation, prediction of related searches. In this paper, we propose Gandalf, a novel approach which makes use of a label co-occurrence graph to leverage label features as additional data points to supplement the training distribution. By exploiting the characteristics of the short-text XMC problem, it leverages the label features to construct valid training instances, and uses the label graph for generating the corresponding soft-label targets, hence effectively capturing the label-label correlations. Surprisingly, models trained on these new training instances, although being less than half of the original dataset, can outperform models trained on the original dataset, particularly on the PSP@k metric for tail labels. With this insight, we aim to train existing XMC algorithms on both, the original and new training instances, leading to an average 5% relative improvements for 6 state-of-the-art algorithms across 4 benchmark datasets consisting of up to 1.3M labels. Gandalf can be applied in a plug-and-play manner to various methods and thus forwards the state-of-the-art in the domain, without incurring any additional computational overheads.
Read more5/9/2024
🏷️
0
ICXML: An In-Context Learning Framework for Zero-Shot Extreme Multi-Label Classification
Yaxin Zhu, Hamed Zamani
This paper focuses on the task of Extreme Multi-Label Classification (XMC) whose goal is to predict multiple labels for each instance from an extremely large label space. While existing research has primarily focused on fully supervised XMC, real-world scenarios often lack supervision signals, highlighting the importance of zero-shot settings. Given the large label space, utilizing in-context learning approaches is not trivial. We address this issue by introducing In-Context Extreme Multilabel Learning (ICXML), a two-stage framework that cuts down the search space by generating a set of candidate labels through incontext learning and then reranks them. Extensive experiments suggest that ICXML advances the state of the art on two diverse public benchmarks.
Read more4/16/2024