A Unified Contrastive Loss for Self-Training

0

Sign in to get full access
Overview
- This paper proposes a unified contrastive loss for self-training, which aims to improve the performance of deep learning models on unlabeled data.
- Self-training is a semi-supervised learning technique that iteratively trains a model on its own predictions, gradually improving the model's performance.
- The authors introduce a contrastive loss function that unifies various self-training approaches and demonstrate its effectiveness on several benchmark datasets.
Plain English Explanation
Deep learning models often require large amounts of labeled data to achieve good performance. However, obtaining labeled data can be time-consuming and expensive. Self-training is a technique that allows models to learn from unlabeled data by iteratively training on their own predictions.
The key idea behind this paper is to introduce a unified contrastive loss that can be used to effectively train models in a self-supervised manner. Contrastive learning is a popular technique that encourages the model to learn representations that are similar for related data points and dissimilar for unrelated data points.
The authors show that by incorporating this contrastive loss into the self-training process, the model can better leverage the unlabeled data and improve its performance on a variety of tasks, including image classification and natural language processing.
Technical Explanation
The paper begins by introducing the necessary notations and background on self-training and contrastive learning. The authors then present their unified contrastive loss for self-training, which combines the standard supervised loss with a contrastive loss that encourages the model to learn better representations from the unlabeled data.
Specifically, the contrastive loss compares the model's predictions for an unlabeled data point against its predictions for a positive example (i.e., a data point the model is confident about) and a negative example (i.e., a data point the model is less confident about). The model is trained to assign higher scores to the positive example and lower scores to the negative example, leading to more discriminative representations.
The authors evaluate their approach on several benchmark datasets and show that it outperforms other self-training methods, particularly in scenarios with limited labeled data. They also provide insights into the importance of the contrastive loss and its role in improving the model's performance on the unlabeled data.
Critical Analysis
The authors provide a thorough analysis of their proposed method and its performance compared to other self-training approaches. They acknowledge that the effectiveness of the unified contrastive loss may depend on the quality of the positive and negative examples used during training, which could be a potential limitation.
Additionally, the paper does not explore the impact of different strategies for selecting the positive and negative examples, which could be an area for further research. It would also be interesting to see how the unified contrastive loss performs on a wider range of tasks and datasets, as the current evaluation is limited to a few specific scenarios.
Overall, the paper presents a promising approach for improving self-training through the use of contrastive learning, but there are still opportunities for further investigation and refinement of the method.
Conclusion
This paper introduces a unified contrastive loss for self-training, which combines standard supervised learning with a contrastive loss that encourages the model to learn better representations from unlabeled data. The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing that it outperforms other self-training methods, particularly in scenarios with limited labeled data.
The proposed technique represents an important contribution to the field of semi-supervised learning, as it provides a way to leverage unlabeled data more effectively and improve the performance of deep learning models. The insights and findings from this paper could inspire further research into the use of contrastive learning for self-training and other semi-supervised learning tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Unified Contrastive Loss for Self-Training
Aurelien Gauffre, Julien Horvat, Massih-Reza Amini
Self-training methods have proven to be effective in exploiting abundant unlabeled data in semi-supervised learning, particularly when labeled data is scarce. While many of these approaches rely on a cross-entropy loss function (CE), recent advances have shown that the supervised contrastive loss function (SupCon) can be more effective. Additionally, unsupervised contrastive learning approaches have also been shown to capture high quality data representations in the unsupervised setting. To benefit from these advantages in a semi-supervised setting, we propose a general framework to enhance self-training methods, which replaces all instances of CE losses with a unique contrastive loss. By using class prototypes, which are a set of class-wise trainable parameters, we recover the probability distributions of the CE setting and show a theoretical equivalence with it. Our framework, when applied to popular self-training methods, results in significant performance improvements across three different datasets with a limited number of labeled data. Additionally, we demonstrate further improvements in convergence speed, transfer ability, and hyperparameter stability. The code is available at url{https://github.com/AurelienGauffre/semisupcon/}.
Read more9/12/2024

0
Self Adaptive Threshold Pseudo-labeling and Unreliable Sample Contrastive Loss for Semi-supervised Image Classification
Xuerong Zhang, Li Huang, Jing Lv, Ming Yang
Semi-supervised learning is attracting blooming attention, due to its success in combining unlabeled data. However, pseudo-labeling-based semi-supervised approaches suffer from two problems in image classification: (1) Existing methods might fail to adopt suitable thresholds since they either use a pre-defined/fixed threshold or an ad-hoc threshold adjusting scheme, resulting in inferior performance and slow convergence. (2) Discarding unlabeled data with confidence below the thresholds results in the loss of discriminating information. To solve these issues, we develop an effective method to make sufficient use of unlabeled data. Specifically, we design a self adaptive threshold pseudo-labeling strategy, which thresholds for each class can be dynamically adjusted to increase the number of reliable samples. Meanwhile, in order to effectively utilise unlabeled data with confidence below the thresholds, we propose an unreliable sample contrastive loss to mine the discriminative information in low-confidence samples by learning the similarities and differences between sample features. We evaluate our method on several classification benchmarks under partially labeled settings and demonstrate its superiority over the other approaches.
Read more7/8/2024
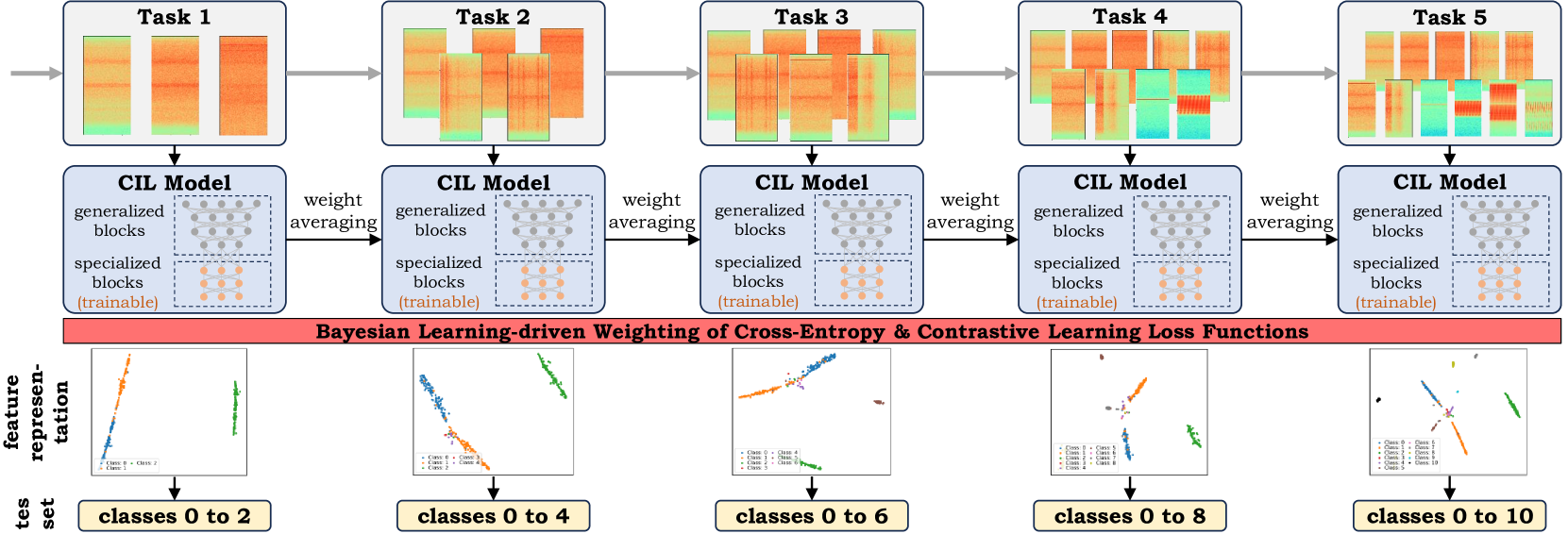
0
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 and CIFAR-100 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
Read more7/15/2024

0
Semi-Supervised Contrastive Learning of Musical Representations
Julien Guinot, Elio Quinton, Gyorgy Fazekas
Despite the success of contrastive learning in Music Information Retrieval, the inherent ambiguity of contrastive self-supervision presents a challenge. Relying solely on augmentation chains and self-supervised positive sampling strategies can lead to a pretraining objective that does not capture key musical information for downstream tasks. We introduce semi-supervised contrastive learning (SemiSupCon), a simple method for leveraging musically informed labeled data (supervision signals) in the contrastive learning of musical representations. Our approach introduces musically relevant supervision signals into self-supervised contrastive learning by combining supervised and self-supervised contrastive objectives in a simpler framework than previous approaches. This framework improves downstream performance and robustness to audio corruptions on a range of downstream MIR tasks with moderate amounts of labeled data. Our approach enables shaping the learned similarity metric through the choice of labeled data that (1) infuses the representations with musical domain knowledge and (2) improves out-of-domain performance with minimal general downstream performance loss. We show strong transfer learning performance on musically related yet not trivially similar tasks - such as pitch and key estimation. Additionally, our approach shows performance improvement on automatic tagging over self-supervised approaches with only 5% of available labels included in pretraining.
Read more7/22/2024