Unified Embedding Based Personalized Retrieval in Etsy Search

0
🔄
Sign in to get full access
Overview
- This paper presents a novel approach to address the semantic gap problem and improve personalized semantic retrieval in product search.
- It describes a unified embedding model that combines graph, transformer, and term-based embeddings to achieve an optimal tradeoff between performance and efficiency.
- The model significantly improved search experience, as measured by a 5.58% increase in search purchase rate and a 2.63% increase in site-wide conversion rate.
Plain English Explanation
When people search for products online, they often use words that don't quite match the product descriptions. This creates a "semantic gap" between what the customer is looking for and what the search engine can find. The paper's authors tackled this problem by developing a new way to match customer searches to relevant products.
Their approach combines several different techniques to create a "unified embedding model." This model learns how words and products are related, using information from customer browsing history, product descriptions, and other sources. By training this model end-to-end, the authors were able to make the search results more personalized and relevant for each customer.
The authors also put a lot of work into engineering the model features, finding effective "negative" examples to train on, and optimizing the model architecture for both performance and efficiency. When they tested this new search system, they saw a significant improvement in key metrics like the rate of purchases from search results and the overall conversion rate on the website.
Technical Explanation
The paper presents a unified embedding-based personalized retrieval model for product search. This model aims to address two key challenges: the semantic gap problem for tail queries and the broad intent of popular queries that can benefit from additional user context.
The authors propose learning a unified embedding model that incorporates graph, transformer, and term-based embeddings in an end-to-end fashion. This allows the model to capture various semantic relationships and user preferences.
Key aspects of the technical approach include:
- Feature engineering to effectively leverage different data sources
- A hard negative sampling strategy to improve training
- Application of transformer models with a novel pre-training strategy
The resulting personalized retrieval model demonstrated significant improvements in search purchase rate (5.58%) and site-wide conversion rate (2.63%) through A/B testing on live traffic.
Critical Analysis
The paper provides a comprehensive overview of the authors' approach to addressing the semantic gap and personalization challenges in product search. The technical details are well-explained, and the empirical results are compelling.
One potential limitation is the reliance on a unified embedding model, which may be complex to train and deploy at scale. The authors acknowledge the tradeoffs between performance and efficiency and mention that further optimization may be required for certain use cases.
Additionally, the paper does not provide much detail on the specific data sources and user interaction features used to train the model. Further research could explore the impact of different data modalities and the generalizability of the approach to other e-commerce domains.
Overall, the paper presents a novel and effective solution to a significant problem in product search, and the insights shared could inspire further advancements in this field.
Conclusion
This paper introduces a unified embedding-based personalized retrieval model that significantly improves the search experience for e-commerce customers. By combining graph, transformer, and term-based embeddings, the model is able to bridge the semantic gap and provide more relevant and personalized search results.
The technical approach, featuring innovative feature engineering, hard negative sampling, and transformer model optimization, demonstrates the authors' deep understanding of the challenges in this domain. The impressive performance gains observed in A/B testing underline the practical impact of this research.
As e-commerce continues to grow, the ability to provide seamless and personalized search experiences will be increasingly crucial. The insights and techniques presented in this paper offer a valuable contribution to the field and could inspire future advancements in product search and recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Unified Embedding Based Personalized Retrieval in Etsy Search
Rishikesh Jha, Siddharth Subramaniyam, Ethan Benjamin, Thrivikrama Taula
Embedding-based neural retrieval is a prevalent approach to address the semantic gap problem which often arises in product search on tail queries. In contrast, popular queries typically lack context and have a broad intent where additional context from users historical interaction can be helpful. In this paper, we share our novel approach to address both: the semantic gap problem followed by an end to end trained model for personalized semantic retrieval. We propose learning a unified embedding model incorporating graph, transformer and term-based embeddings end to end and share our design choices for optimal tradeoff between performance and efficiency. We share our learnings in feature engineering, hard negative sampling strategy, and application of transformer model, including a novel pre-training strategy and other tricks for improving search relevance and deploying such a model at industry scale. Our personalized retrieval model significantly improves the overall search experience, as measured by a 5.58% increase in search purchase rate and a 2.63% increase in site-wide conversion rate, aggregated across multiple A/B tests - on live traffic.
Read more9/26/2024
0
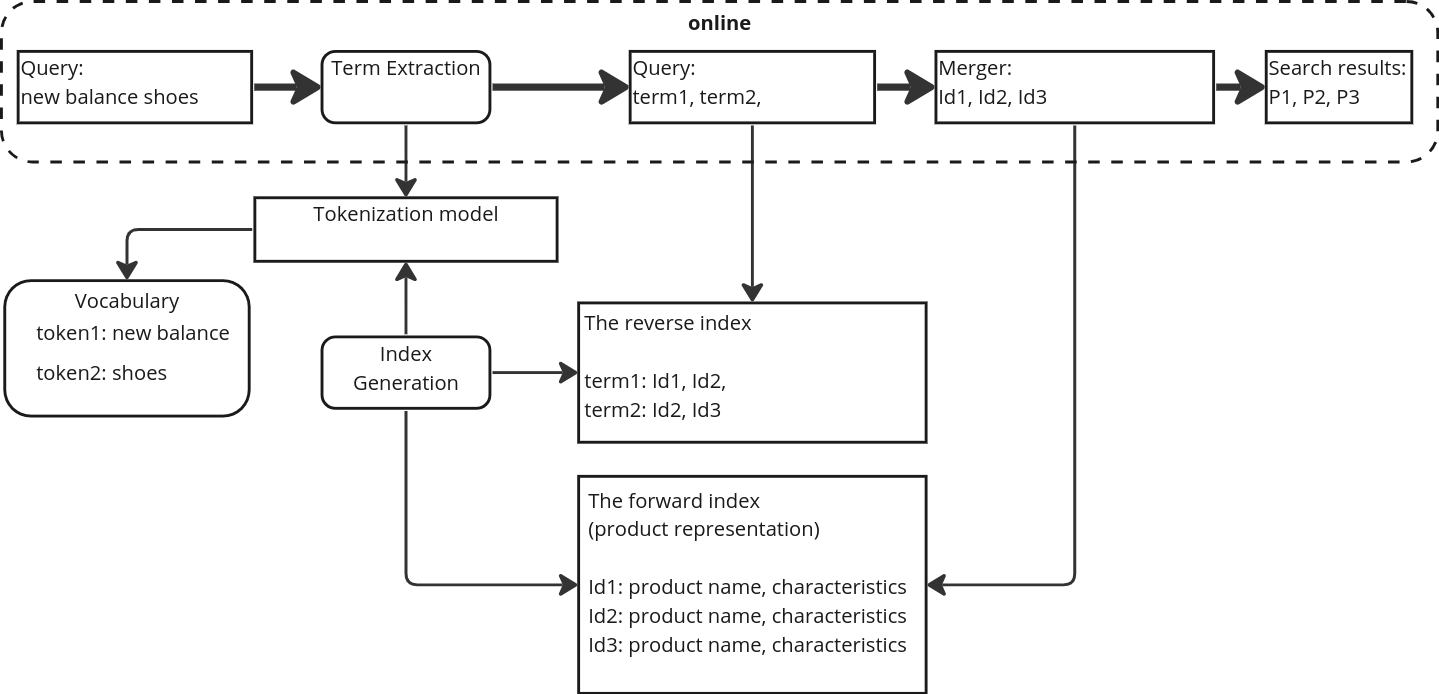
Multi-word Term Embeddings Improve Lexical Product Retrieval
Viktor Shcherbakov, Fedor Krasnov
Product search is uniquely different from search for documents, Internet resources or vacancies, therefore it requires the development of specialized search systems. The present work describes the H1 embdedding model, designed for an offline term indexing of product descriptions at e-commerce platforms. The model is compared to other state-of-the-art (SoTA) embedding models within a framework of hybrid product search system that incorporates the advantages of lexical methods for product retrieval and semantic embedding-based methods. We propose an approach to building semantically rich term vocabularies for search indexes. Compared to other production semantic models, H1 paired with the proposed approach stands out due to its ability to process multi-word product terms as one token. As an example, for search queries new balance shoes, gloria jeans kids wear brand entity will be represented as one token - new balance, gloria jeans. This results in an increased precision of the system without affecting the recall. The hybrid search system with proposed model scores mAP@12 = 56.1% and R@1k = 86.6% on the WANDS public dataset, beating other SoTA analogues.
Read more6/4/2024

0
Enhancing Relevance of Embedding-based Retrieval at Walmart
Juexin Lin, Sachin Yadav, Feng Liu, Nicholas Rossi, Praveen R. Suram, Satya Chembolu, Prijith Chandran, Hrushikesh Mohapatra, Tony Lee, Alessandro Magnani, Ciya Liao
Embedding-based neural retrieval (EBR) is an effective search retrieval method in product search for tackling the vocabulary gap between customer search queries and products. The initial launch of our EBR system at Walmart yielded significant gains in relevance and add-to-cart rates [1]. However, despite EBR generally retrieving more relevant products for reranking, we have observed numerous instances of relevance degradation. Enhancing retrieval performance is crucial, as it directly influences product reranking and affects the customer shopping experience. Factors contributing to these degradations include false positives/negatives in the training data and the inability to handle query misspellings. To address these issues, we present several approaches to further strengthen the capabilities of our EBR model in terms of retrieval relevance. We introduce a Relevance Reward Model (RRM) based on human relevance feedback. We utilize RRM to remove noise from the training data and distill it into our EBR model through a multi-objective loss. In addition, we present the techniques to increase the performance of our EBR model, such as typo-aware training, and semi-positive generation. The effectiveness of our EBR is demonstrated through offline relevance evaluation, online AB tests, and successful deployments to live production. [1] Alessandro Magnani, Feng Liu, Suthee Chaidaroon, Sachin Yadav, Praveen Reddy Suram, Ajit Puthenputhussery, Sijie Chen, Min Xie, Anirudh Kashi, Tony Lee, et al. 2022. Semantic retrieval at walmart. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3495-3503.
Read more8/16/2024

0
EnterpriseEM: Fine-tuned Embeddings for Enterprise Semantic Search
Kamalkumar Rathinasamy, Jayarama Nettar, Amit Kumar, Vishal Manchanda, Arun Vijayakumar, Ayush Kataria, Venkateshprasanna Manjunath, Chidambaram GS, Jaskirat Singh Sodhi, Shoeb Shaikh, Wasim Akhtar Khan, Prashant Singh, Tanishq Dattatray Ige, Vipin Tiwari, Rajab Ali Mondal, Harshini K, S Reka, Chetana Amancharla, Faiz ur Rahman, Harikrishnan P A, Indraneel Saha, Bhavya Tiwary, Navin Shankar Patel, Pradeep T S, Balaji A J, Priyapravas, Mohammed Rafee Tarafdar
Enterprises grapple with the significant challenge of managing proprietary unstructured data, hindering efficient information retrieval. This has led to the emergence of AI-driven information retrieval solutions, designed to adeptly extract relevant insights to address employee inquiries. These solutions often leverage pre-trained embedding models and generative models as foundational components. While pre-trained embeddings may exhibit proximity or disparity based on their original training objectives, they might not fully align with the unique characteristics of enterprise-specific data, leading to suboptimal alignment with the retrieval goals of enterprise environments. In this paper, we propose a comprehensive methodology for contextualizing pre-trained embedding models to enterprise environments, covering the entire process from data preparation to model fine-tuning and evaluation. By adapting the embeddings to better suit the retrieval tasks prevalent in enterprises, we aim to enhance the performance of information retrieval solutions. We discuss the process of fine-tuning, its effect on retrieval accuracy, and the potential benefits for enterprise information management. Our findings demonstrate the efficacy of fine-tuned embedding models in improving the precision and relevance of search results in enterprise settings.
Read more9/30/2024