Multi-word Term Embeddings Improve Lexical Product Retrieval

0
Sign in to get full access
Overview
- This paper explores the use of multi-word term embeddings to improve lexical product retrieval, which is the process of finding relevant products based on search queries.
- The researchers propose a novel approach that combines multi-word term embeddings with traditional single-word embeddings to better capture the semantic relationships between product descriptions and user queries.
- The proposed method is evaluated on several benchmark datasets, demonstrating significant improvements in product retrieval performance compared to existing techniques.
Plain English Explanation
When people search for products online, they often use a combination of words to describe what they're looking for. For example, someone might search for "wireless noise-cancelling headphones" instead of just "headphones." Traditional product search systems typically treat each word in the search query independently, which can miss the nuanced meaning conveyed by the full phrase.
The researchers in this paper developed a new approach that takes into account the relationships between multiple words in a search query. By using "multi-word term embeddings," which capture the semantic meaning of entire phrases, the system can better understand the user's intent and find more relevant products. This is particularly useful for specialized or technical product searches, where a single-word query may not be sufficient to accurately describe the desired item.
The researchers tested their multi-word term embedding approach on several industry-standard datasets for product search and retrieval. They found that it consistently outperformed traditional single-word embedding methods, improving the system's ability to match user queries to the most appropriate products. This suggests that incorporating multi-word term understanding can significantly enhance the performance of online product search and recommendation systems.
Technical Explanation
The key innovation in this paper is the use of multi-word term embeddings to augment traditional single-word embeddings for product retrieval. The researchers first train a multi-word term embedding model using a large corpus of product descriptions and user search queries. This allows the model to capture the semantic relationships between common product-related phrases, such as "wireless noise-cancelling headphones" or "leather messenger bag."
During the retrieval process, the system combines the multi-word term embeddings with single-word embeddings derived from the query and product descriptions. This hybrid embedding approach enables the system to better understand the user's intent and match it to the most relevant products in the catalog.
The researchers evaluate their approach on several standard product retrieval benchmarks, including Semantic Domain Product Identification from Search Queries and Efficient, Interpretable Information Retrieval for Product Question Answering. They demonstrate significant improvements in retrieval performance metrics such as Recall@k and Normalized Discounted Cumulative Gain (NDCG), compared to state-of-the-art single-word embedding methods.
Critical Analysis
One potential limitation of the proposed approach is that it relies on the availability of a large corpus of product descriptions and user search queries to train the multi-word term embedding model. In domains with smaller or less diverse datasets, the performance gains may be more modest. The researchers acknowledge this and suggest that further research is needed to explore techniques for enhancing embedding performance through large language models in data-scarce scenarios.
Additionally, the paper does not extensively explore the interpretability or explainability of the multi-word term embeddings. While the improved retrieval performance is compelling, it would be valuable to understand how the system is using the multi-word term information to make decisions, and whether this can be effectively communicated to users or domain experts.
Overall, the research presents a promising approach for leveraging multiclass data fusion to enhance product search and recommendation systems. The strong empirical results suggest that multi-word term embeddings can be a valuable tool for improving retrieval models through LLM augmentation, particularly in domains where users employ complex, specialized language to describe their product needs.
Conclusion
This paper introduces a novel approach to product retrieval that combines multi-word term embeddings with traditional single-word embeddings. By capturing the semantic relationships between common product-related phrases, the proposed method demonstrates significant improvements in retrieval performance across several benchmark datasets.
The research highlights the importance of understanding the nuanced language used by consumers when searching for products online. By leveraging multi-word term embeddings, product search and recommendation systems can better match user queries to the most relevant items in the catalog, ultimately enhancing the user experience and driving increased sales.
The findings of this paper have broader implications for information retrieval and natural language processing in e-commerce and other domains where users employ specialized, multi-word terminology to describe their needs. As online shopping continues to grow, techniques like the one proposed in this research will become increasingly important for delivering accurate and relevant product recommendations to consumers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-word Term Embeddings Improve Lexical Product Retrieval
Viktor Shcherbakov, Fedor Krasnov
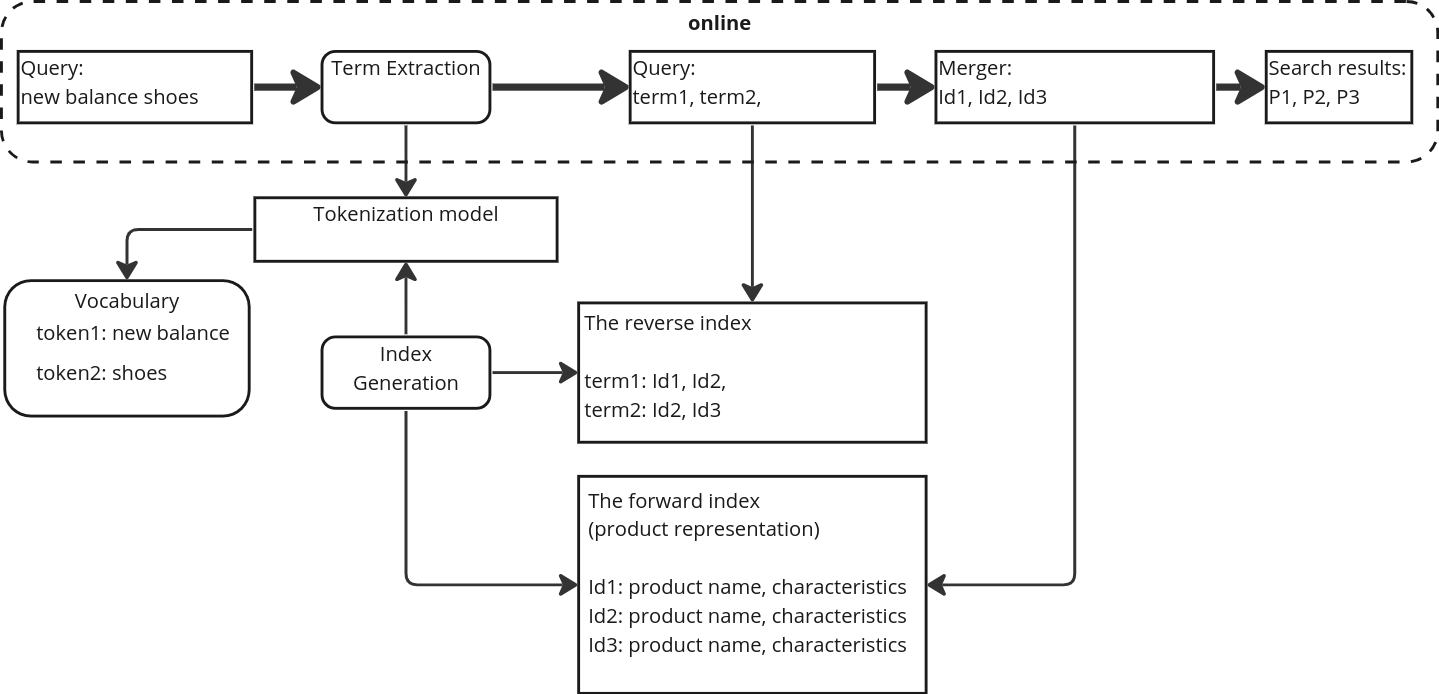
Product search is uniquely different from search for documents, Internet resources or vacancies, therefore it requires the development of specialized search systems. The present work describes the H1 embdedding model, designed for an offline term indexing of product descriptions at e-commerce platforms. The model is compared to other state-of-the-art (SoTA) embedding models within a framework of hybrid product search system that incorporates the advantages of lexical methods for product retrieval and semantic embedding-based methods. We propose an approach to building semantically rich term vocabularies for search indexes. Compared to other production semantic models, H1 paired with the proposed approach stands out due to its ability to process multi-word product terms as one token. As an example, for search queries new balance shoes, gloria jeans kids wear brand entity will be represented as one token - new balance, gloria jeans. This results in an increased precision of the system without affecting the recall. The hybrid search system with proposed model scores mAP@12 = 56.1% and R@1k = 86.6% on the WANDS public dataset, beating other SoTA analogues.
Read more6/4/2024
🔄
0
Unified Embedding Based Personalized Retrieval in Etsy Search
Rishikesh Jha, Siddharth Subramaniyam, Ethan Benjamin, Thrivikrama Taula
Embedding-based neural retrieval is a prevalent approach to address the semantic gap problem which often arises in product search on tail queries. In contrast, popular queries typically lack context and have a broad intent where additional context from users historical interaction can be helpful. In this paper, we share our novel approach to address both: the semantic gap problem followed by an end to end trained model for personalized semantic retrieval. We propose learning a unified embedding model incorporating graph, transformer and term-based embeddings end to end and share our design choices for optimal tradeoff between performance and efficiency. We share our learnings in feature engineering, hard negative sampling strategy, and application of transformer model, including a novel pre-training strategy and other tricks for improving search relevance and deploying such a model at industry scale. Our personalized retrieval model significantly improves the overall search experience, as measured by a 5.58% increase in search purchase rate and a 2.63% increase in site-wide conversion rate, aggregated across multiple A/B tests - on live traffic.
Read more9/26/2024
📊
0
Efficient and Interpretable Information Retrieval for Product Question Answering with Heterogeneous Data
Biplob Biswas, Rajiv Ramnath
Expansion-enhanced sparse lexical representation improves information retrieval (IR) by minimizing vocabulary mismatch problems during lexical matching. In this paper, we explore the potential of jointly learning dense semantic representation and combining it with the lexical one for ranking candidate information. We present a hybrid information retrieval mechanism that maximizes lexical and semantic matching while minimizing their shortcomings. Our architecture consists of dual hybrid encoders that independently encode queries and information elements. Each encoder jointly learns a dense semantic representation and a sparse lexical representation augmented by a learnable term expansion of the corresponding text through contrastive learning. We demonstrate the efficacy of our model in single-stage ranking of a benchmark product question-answering dataset containing the typical heterogeneous information available on online product pages. Our evaluation demonstrates that our hybrid approach outperforms independently trained retrievers by 10.95% (sparse) and 2.7% (dense) in MRR@5 score. Moreover, our model offers better interpretability and performs comparably to state-of-the-art cross encoders while reducing response time by 30% (latency) and cutting computational load by approximately 38% (FLOPs).
Read more5/24/2024

0
Semantic In-Domain Product Identification for Search Queries
Sanat Sharma, Jayant Kumar, Twisha Naik, Zhaoyu Lu, Arvind Srikantan, Tracy Holloway King
Accurate explicit and implicit product identification in search queries is critical for enhancing user experiences, especially at a company like Adobe which has over 50 products and covers queries across hundreds of tools. In this work, we present a novel approach to training a product classifier from user behavioral data. Our semantic model led to >25% relative improvement in CTR (click through rate) across the deployed surfaces; a >50% decrease in null rate; a 2x increase in the app cards surfaced, which helps drive product visibility.
Read more5/30/2024