Unified Hallucination Detection for Multimodal Large Language Models
2402.03190
0
0
🔎
Abstract
Despite significant strides in multimodal tasks, Multimodal Large Language Models (MLLMs) are plagued by the critical issue of hallucination. The reliable detection of such hallucinations in MLLMs has, therefore, become a vital aspect of model evaluation and the safeguarding of practical application deployment. Prior research in this domain has been constrained by a narrow focus on singular tasks, an inadequate range of hallucination categories addressed, and a lack of detailed granularity. In response to these challenges, our work expands the investigative horizons of hallucination detection. We present a novel meta-evaluation benchmark, MHaluBench, meticulously crafted to facilitate the evaluation of advancements in hallucination detection methods. Additionally, we unveil a novel unified multimodal hallucination detection framework, UNIHD, which leverages a suite of auxiliary tools to validate the occurrence of hallucinations robustly. We demonstrate the effectiveness of UNIHD through meticulous evaluation and comprehensive analysis. We also provide strategic insights on the application of specific tools for addressing various categories of hallucinations.
Create account to get full access
Overview
- Multimodal Large Language Models (MLLMs) face a critical issue of hallucination, where they generate content that is not grounded in the input data.
- Reliable detection of hallucinations in MLLMs is crucial for evaluating model performance and deploying them safely in practical applications.
- Prior research in this area has been limited in scope, focusing on specific tasks and lacking a comprehensive range of hallucination categories.
Plain English Explanation
Multimodal Large Language Models (MLLMs) are powerful AI systems that can process and generate information from multiple sources, like text, images, and video. However, these models sometimes produce content that isn't actually based on the input data they're given. This phenomenon is called "hallucination," and it's a critical issue that needs to be addressed before these models can be safely used in real-world applications.
Researchers have been working on ways to detect hallucinations in MLLMs, but their efforts have been constrained by a narrow focus on particular tasks and an incomplete understanding of the different types of hallucinations that can occur. The provided paper aims to expand the horizons of hallucination detection research by introducing a new benchmark and a novel framework for more comprehensive and robust detection of hallucinations in MLLMs.
Technical Explanation
The paper presents a novel meta-evaluation benchmark called MHaluBench, which is designed to facilitate the evaluation of advancements in hallucination detection methods. MHaluBench provides a diverse set of tasks and scenarios to test the performance of hallucination detection techniques.
Additionally, the researchers introduce a unified multimodal hallucination detection framework called UNIHD. UNIHD leverages a suite of auxiliary tools to validate the occurrence of hallucinations in a robust manner. The paper demonstrates the effectiveness of UNIHD through extensive evaluation and comprehensive analysis.
The authors also provide strategic insights on the application of specific tools for addressing different categories of hallucinations, such as factual, perceptual, and coherence-based hallucinations.
Critical Analysis
The paper's focus on expanding the scope and depth of hallucination detection research is commendable. By introducing MHaluBench and UNIHD, the authors have made significant strides in addressing the limitations of prior work in this domain.
However, the paper does not delve into the potential limitations or challenges associated with the proposed benchmark and framework. For example, it would be valuable to understand the computational and resource requirements of UNIHD, as well as any potential biases or shortcomings of the auxiliary tools used.
Additionally, the paper does not provide a detailed discussion on the broader implications of hallucination detection research, such as its impact on the development and deployment of safe and reliable MLLMs, or the ethical considerations involved in ensuring the trustworthiness of these AI systems.
Conclusion
This paper presents a novel approach to the critical issue of hallucination in Multimodal Large Language Models (MLLMs). By introducing the MHaluBench benchmark and the UNIHD framework, the researchers have made significant contributions to the field of hallucination detection, paving the way for more comprehensive and robust evaluation of MLLM performance.
The insights provided in this work can inform the development of safer and more reliable MLLMs, ultimately enhancing their practical applications and societal impact. However, further research is needed to fully address the limitations and broader implications of hallucination detection in the context of large-scale multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024

Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Weihang Su, Changyue Wang, Qingyao Ai, Yiran HU, Zhijing Wu, Yujia Zhou, Yiqun Liu
0
0
Hallucinations in large language models (LLMs) refer to the phenomenon of LLMs producing responses that are coherent yet factually inaccurate. This issue undermines the effectiveness of LLMs in practical applications, necessitating research into detecting and mitigating hallucinations of LLMs. Previous studies have mainly concentrated on post-processing techniques for hallucination detection, which tend to be computationally intensive and limited in effectiveness due to their separation from the LLM's inference process. To overcome these limitations, we introduce MIND, an unsupervised training framework that leverages the internal states of LLMs for real-time hallucination detection without requiring manual annotations. Additionally, we present HELM, a new benchmark for evaluating hallucination detection across multiple LLMs, featuring diverse LLM outputs and the internal states of LLMs during their inference process. Our experiments demonstrate that MIND outperforms existing state-of-the-art methods in hallucination detection.
6/11/2024
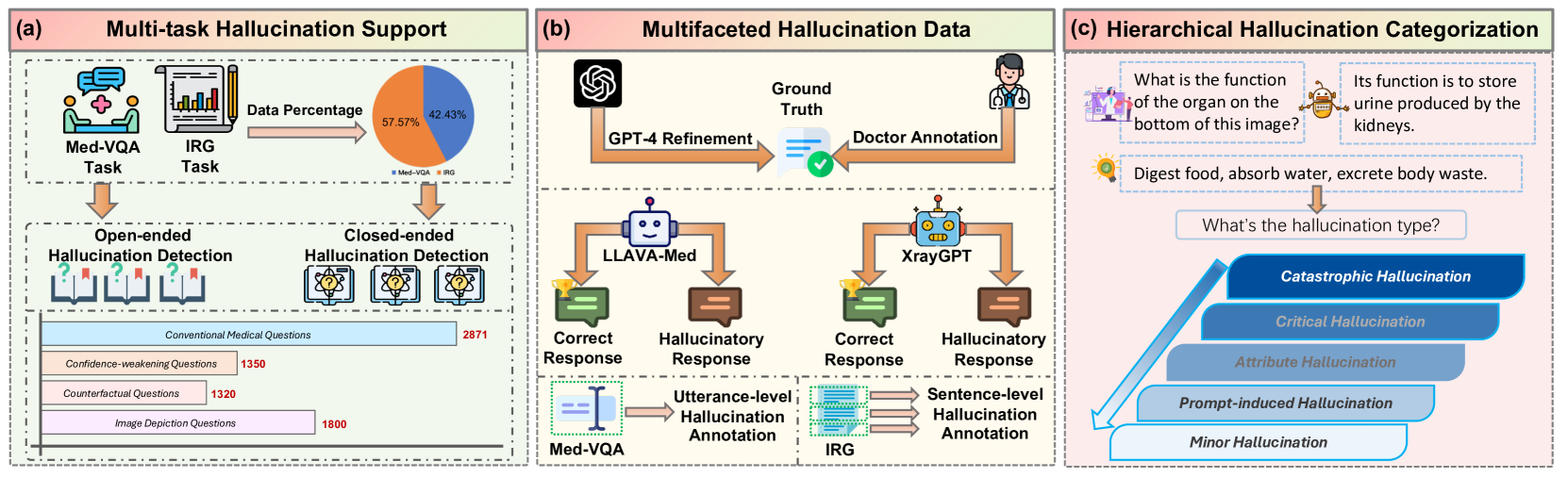
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, Shunli Wang, Dongling Xiao, Ke Li, Lihua Zhang
0
0
Large Vision Language Models (LVLMs) are increasingly integral to healthcare applications, including medical visual question answering and imaging report generation. While these models inherit the robust capabilities of foundational Large Language Models (LLMs), they also inherit susceptibility to hallucinations-a significant concern in high-stakes medical contexts where the margin for error is minimal. However, currently, there are no dedicated methods or benchmarks for hallucination detection and evaluation in the medical field. To bridge this gap, we introduce Med-HallMark, the first benchmark specifically designed for hallucination detection and evaluation within the medical multimodal domain. This benchmark provides multi-tasking hallucination support, multifaceted hallucination data, and hierarchical hallucination categorization. Furthermore, we propose the MediHall Score, a new medical evaluative metric designed to assess LVLMs' hallucinations through a hierarchical scoring system that considers the severity and type of hallucination, thereby enabling a granular assessment of potential clinical impacts. We also present MediHallDetector, a novel Medical LVLM engineered for precise hallucination detection, which employs multitask training for hallucination detection. Through extensive experimental evaluations, we establish baselines for popular LVLMs using our benchmark. The findings indicate that MediHall Score provides a more nuanced understanding of hallucination impacts compared to traditional metrics and demonstrate the enhanced performance of MediHallDetector. We hope this work can significantly improve the reliability of LVLMs in medical applications. All resources of this work will be released soon.
6/17/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024