Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning
2404.06970
0
0
Abstract
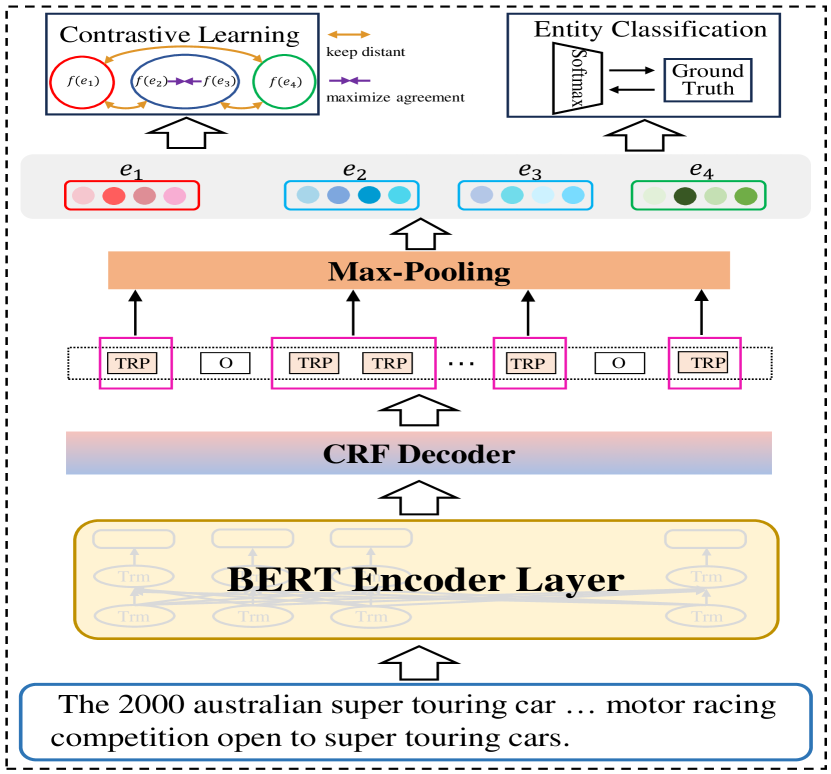
Few-shot named entity recognition can identify new types of named entities based on a few labeled examples. Previous methods employing token-level or span-level metric learning suffer from the computational burden and a large number of negative sample spans. In this paper, we propose the Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning (MsFNER), which splits the general NER into two stages: entity-span detection and entity classification. There are 3 processes for introducing MsFNER: training, finetuning, and inference. In the training process, we train and get the best entity-span detection model and the entity classification model separately on the source domain using meta-learning, where we create a contrastive learning module to enhance entity representations for entity classification. During finetuning, we finetune the both models on the support dataset of target domain. In the inference process, for the unlabeled data, we first detect the entity-spans, then the entity-spans are jointly determined by the entity classification model and the KNN. We conduct experiments on the open FewNERD dataset and the results demonstrate the advance of MsFNER.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces a hybrid multi-stage decoding approach for few-shot named entity recognition (NER) tasks, leveraging entity-aware contrastive learning.
- Aims to address the challenge of limited training data in few-shot NER scenarios by effectively utilizing both labeled and unlabeled data.
- Proposes a novel entity-aware contrastive learning objective to capture entity-level knowledge, along with a multi-stage decoding strategy to progressively refine the predictions.
Plain English Explanation
Named entity recognition (NER) is the task of identifying and classifying named entities, such as people, organizations, and locations, within text. Few-shot NER refers to the scenario where only a small amount of labeled training data is available, which can make it challenging to build accurate NER models.
The researchers in this paper introduce a new approach to address this challenge. Their method, called "Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning," aims to effectively utilize both the limited labeled data and the abundant unlabeled data to improve the performance of few-shot NER models.
The key ideas are:
- Entity-aware Contrastive Learning: The model learns to better understand and represent entities by training on a contrastive objective that encourages it to distinguish between different entities, even when they appear in different contexts.
- Multi-stage Decoding: The model goes through multiple stages of refinement, using the entity-level knowledge gained from the contrastive learning to progressively improve its predictions.
By combining these two techniques, the researchers were able to develop a more accurate and robust NER model, even when only a small amount of labeled data is available. This can be particularly useful in real-world scenarios where annotating large datasets can be time-consuming and expensive.
Technical Explanation
The researchers propose a Hybrid Multi-stage Decoding approach for few-shot NER, which consists of two main components:
-
Entity-aware Contrastive Learning: The model is trained using a contrastive learning objective that encourages it to learn entity-level representations. This is achieved by introducing an "entity-aware" contrastive loss, which aims to pull representations of the same entity closer together and push representations of different entities further apart, even when they appear in different contexts.
-
Multi-stage Decoding: The model goes through multiple stages of decoding, with each stage refining the predictions from the previous stage. This allows the model to progressively improve its understanding of the entities and the overall task, leveraging the entity-level knowledge gained from the contrastive learning.
The training process involves three main steps:
- Initial Decoding: The model first performs an initial decoding of the input text, generating preliminary entity predictions.
- Entity-aware Contrastive Learning: The model then learns entity-level representations using the contrastive learning objective, which compares the representations of entities across different instances.
- Iterative Refinement: Finally, the model goes through multiple rounds of iterative refinement, using the entity-level knowledge gained from the contrastive learning to progressively improve its predictions.
The researchers evaluated their approach on several few-shot NER benchmarks and demonstrated that it outperforms other state-of-the-art methods, particularly when the amount of labeled data is limited.
Critical Analysis
The researchers acknowledge several limitations and areas for further research:
- Scalability to Larger Datasets: While the proposed approach shows promising results on the few-shot NER benchmarks, it remains to be seen how it would scale to larger, real-world datasets with more diverse entity types and a wider range of context.
- Reliance on Pretrained Models: The method relies on a pretrained language model, which may limit its applicability in low-resource settings or domains where such models are not readily available.
- Interpretability of Entity Representations: The paper does not provide a detailed analysis of the learned entity representations, which could be useful for understanding the model's decision-making process and identifying potential biases or shortcomings.
Additionally, one could consider the following potential areas for further investigation:
- Exploring Alternative Contrastive Objectives: The current contrastive learning approach focuses on entity-level representations, but there may be other ways to leverage contrastive learning to capture relevant information for few-shot NER.
- Investigating Domain-Specific Adaptations: The performance of the model may be further improved by adapting the approach to specific domains or tasks, such as biomedical named entity recognition.
- Integrating External Knowledge Sources: Incorporating additional knowledge, such as from knowledge bases or ontologies, could potentially enhance the model's understanding of entities and improve its few-shot NER capabilities.
Conclusion
The "Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning" approach presents a promising solution to the challenge of few-shot named entity recognition. By leveraging entity-aware contrastive learning and a multi-stage decoding strategy, the model is able to effectively utilize both labeled and unlabeled data to improve its performance, even when only a small amount of annotated data is available.
This research highlights the potential of combining advanced learning techniques, such as contrastive learning and iterative refinement, to tackle challenging NLP tasks with limited training data. As the demand for accurate and efficient NER models continues to grow, especially in specialized domains, this work can serve as a valuable stepping stone towards more robust and adaptable few-shot learning solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
A Unified Label-Aware Contrastive Learning Framework for Few-Shot Named Entity Recognition
Haojie Zhang, Yimeng Zhuang
0
0
Few-shot Named Entity Recognition (NER) aims to extract named entities using only a limited number of labeled examples. Existing contrastive learning methods often suffer from insufficient distinguishability in context vector representation because they either solely rely on label semantics or completely disregard them. To tackle this issue, we propose a unified label-aware token-level contrastive learning framework. Our approach enriches the context by utilizing label semantics as suffix prompts. Additionally, it simultaneously optimizes context-context and context-label contrastive learning objectives to enhance generalized discriminative contextual representations.Extensive experiments on various traditional test domains (OntoNotes, CoNLL'03, WNUT'17, GUM, I2B2) and the large-scale few-shot NER dataset (FEWNERD) demonstrate the effectiveness of our approach. It outperforms prior state-of-the-art models by a significant margin, achieving an average absolute gain of 7% in micro F1 scores across most scenarios. Further analysis reveals that our model benefits from its powerful transfer capability and improved contextual representations.
5/9/2024
💬
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Dongsheng Wang, Xiaoqin Feng, Zeming Liu, Chuan Wang
0
0
Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
4/29/2024
SCANNER: Knowledge-Enhanced Approach for Robust Multi-modal Named Entity Recognition of Unseen Entities
Hyunjong Ok, Taeho Kil, Sukmin Seo, Jaeho Lee
0
0
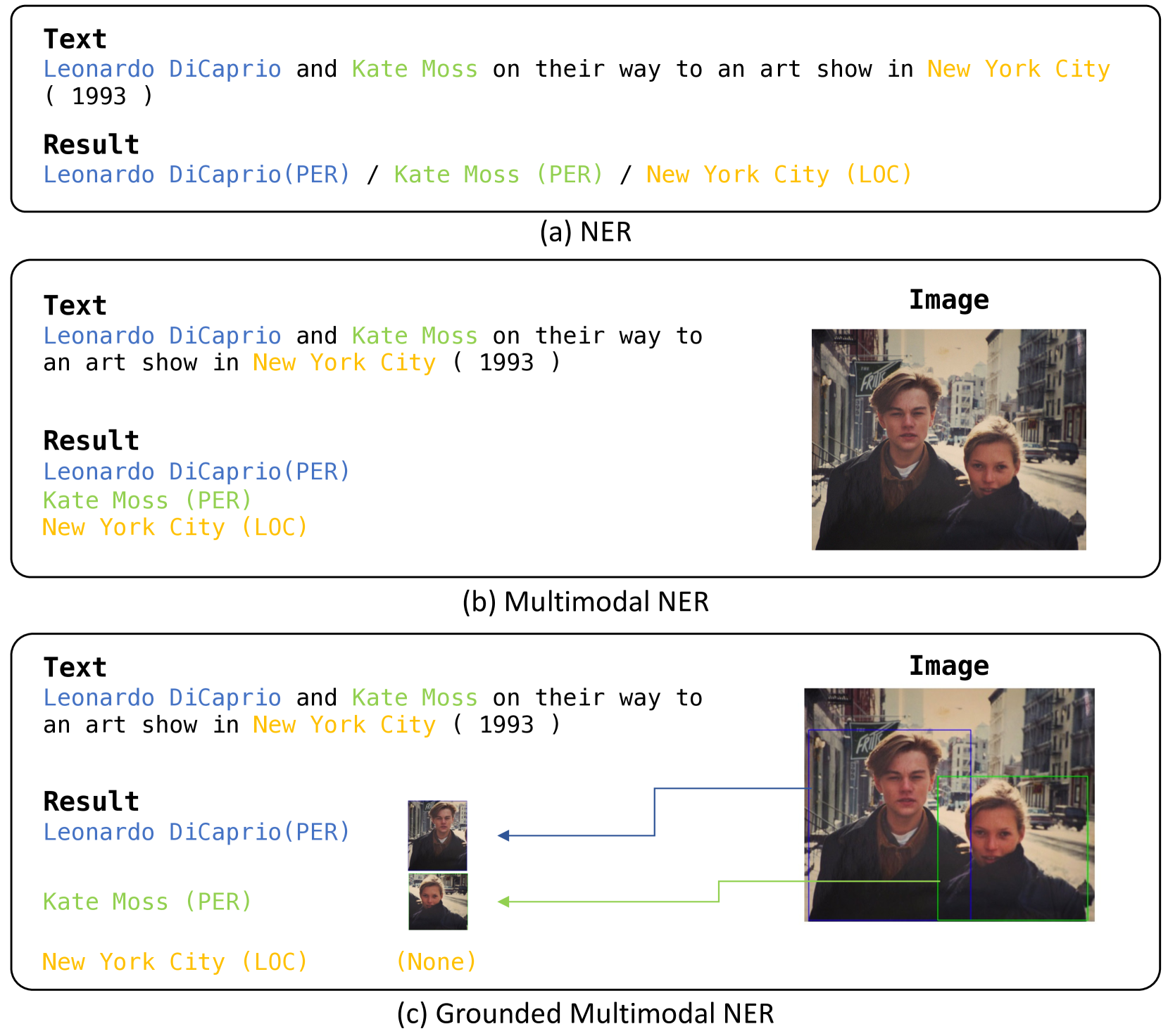
Recent advances in named entity recognition (NER) have pushed the boundary of the task to incorporate visual signals, leading to many variants, including multi-modal NER (MNER) or grounded MNER (GMNER). A key challenge to these tasks is that the model should be able to generalize to the entities unseen during the training, and should be able to handle the training samples with noisy annotations. To address this obstacle, we propose SCANNER (Span CANdidate detection and recognition for NER), a model capable of effectively handling all three NER variants. SCANNER is a two-stage structure; we extract entity candidates in the first stage and use it as a query to get knowledge, effectively pulling knowledge from various sources. We can boost our performance by utilizing this entity-centric extracted knowledge to address unseen entities. Furthermore, to tackle the challenges arising from noisy annotations in NER datasets, we introduce a novel self-distillation method, enhancing the robustness and accuracy of our model in processing training data with inherent uncertainties. Our approach demonstrates competitive performance on the NER benchmark and surpasses existing methods on both MNER and GMNER benchmarks. Further analysis shows that the proposed distillation and knowledge utilization methods improve the performance of our model on various benchmarks.
4/3/2024
Few-shot Name Entity Recognition on StackOverflow
Xinwei Chen, Kun Li, Tianyou Song, Jiangjian Guo
0
0
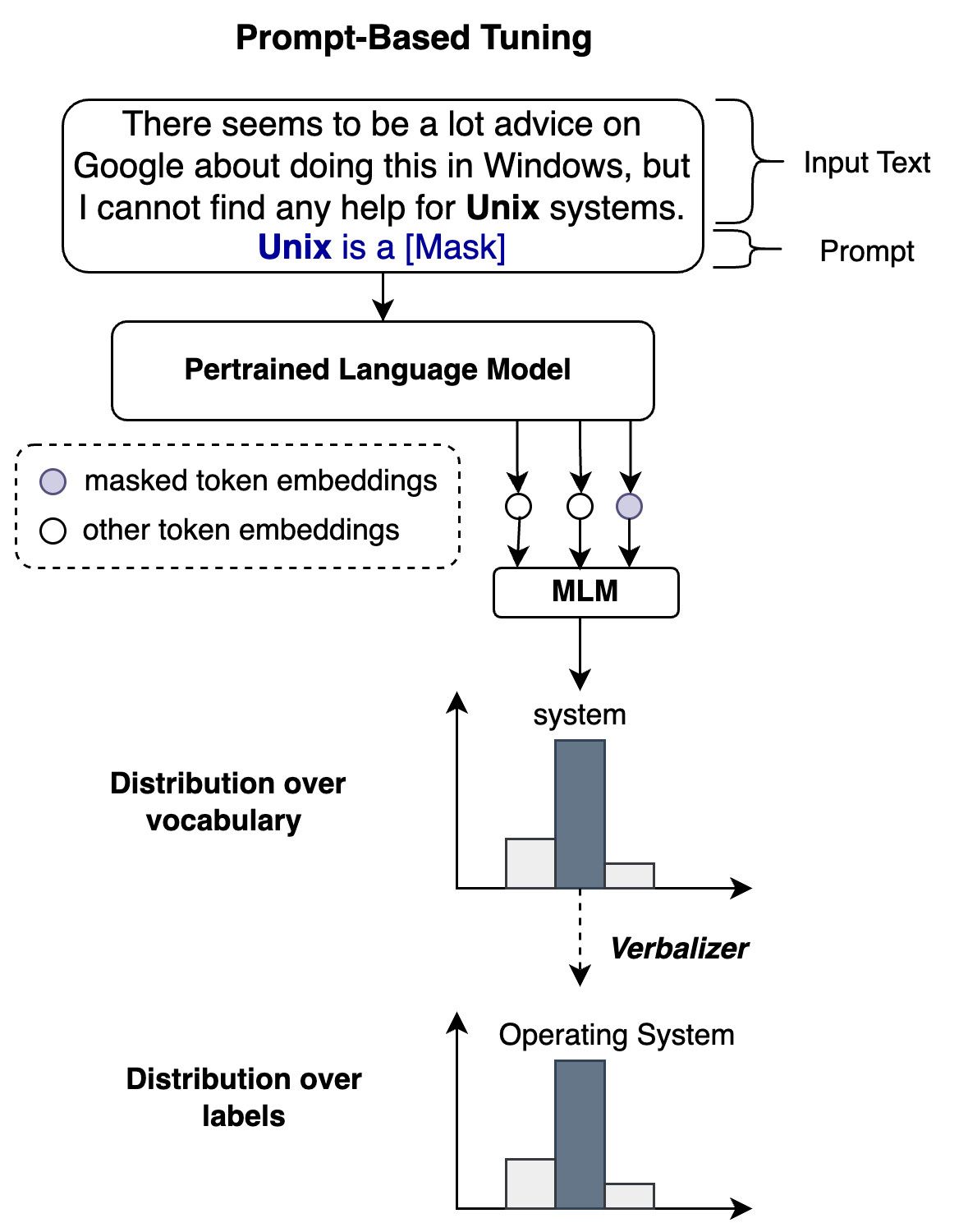
StackOverflow, with its vast question repository and limited labeled examples, raise an annotation challenge for us. We address this gap by proposing RoBERTa+MAML, a few-shot named entity recognition (NER) method leveraging meta-learning. Our approach, evaluated on the StackOverflow NER corpus (27 entity types), achieves a 5% F1 score improvement over the baseline. We improved the results further domain-specific phrase processing enhance results.
4/30/2024