Unified Language-driven Zero-shot Domain Adaptation
2404.07155
0
0
Abstract
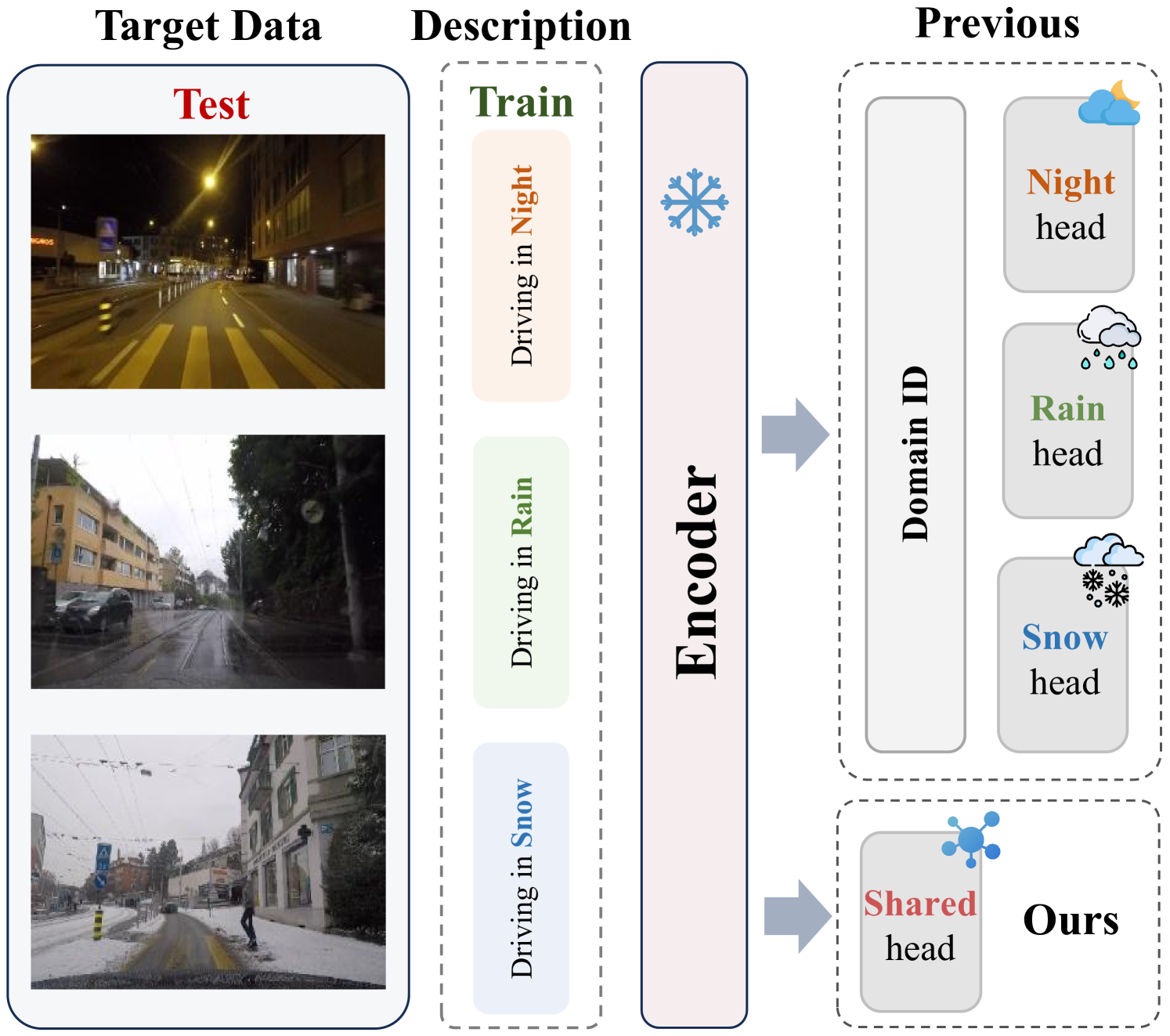
This paper introduces Unified Language-driven Zero-shot Domain Adaptation (ULDA), a novel task setting that enables a single model to adapt to diverse target domains without explicit domain-ID knowledge. We identify the constraints in the existing language-driven zero-shot domain adaptation task, particularly the requirement for domain IDs and domain-specific models, which may restrict flexibility and scalability. To overcome these issues, we propose a new framework for ULDA, consisting of Hierarchical Context Alignment (HCA), Domain Consistent Representation Learning (DCRL), and Text-Driven Rectifier (TDR). These components work synergistically to align simulated features with target text across multiple visual levels, retain semantic correlations between different regional representations, and rectify biases between simulated and real target visual features, respectively. Our extensive empirical evaluations demonstrate that this framework achieves competitive performance in both settings, surpassing even the model that requires domain-ID, showcasing its superiority and generalization ability. The proposed method is not only effective but also maintains practicality and efficiency, as it does not introduce additional computational costs during inference. Our project page is https://senqiaoyang.com/project/ULDA .
Create account to get full access
Overview
- This paper introduces a new method called Unified Language-driven Zero-shot Domain Adaptation (ULDA) that can adapt machine learning models to new domains without any labeled data in the target domain.
- ULDA leverages natural language descriptions of the target domain to guide the adaptation process, allowing it to work in a "zero-shot" setting where no labeled data is available for the target domain.
- The authors demonstrate the effectiveness of ULDA on several benchmark datasets, showing that it outperforms other state-of-the-art unsupervised domain adaptation methods.
Plain English Explanation
Machine learning models are often trained on one type of data (the "source" domain) but then need to be used on a different type of data (the "target" domain). Unsupervised domain adaptation techniques try to adapt the model to the target domain without needing any labeled data from that domain.
The key insight behind the ULDA method is that we can use natural language descriptions of the target domain to guide the adaptation process, even if we don't have any labeled examples from that domain. The authors show that by embedding these language descriptions and using them to constrain the model's adaptation, they can effectively adapt it to new domains in a "zero-shot" setting.
This is a powerful capability, as it means the model can be deployed in new real-world scenarios without the need for expensive data collection and labeling. The authors demonstrate ULDA's effectiveness on several standard benchmarks, showing it outperforms other state-of-the-art unsupervised domain adaptation techniques.
Technical Explanation
The ULDA method works by learning a shared representation space between the source and target domains, using the language descriptions of the target domain to guide this process. Specifically, the authors propose two key components:
-
Language Embedding Projection: The natural language descriptions of the target domain are encoded into a vector representation using a pre-trained language model. This embedding is then projected into the shared representation space.
-
Language-Constrained Adaptation: The model is trained to adapt to the target domain in a way that aligns the learned representations with the projected language embeddings. This encourages the model to learn features that are relevant to the target domain, even without any labeled examples.
The authors evaluate ULDA on several image classification and semantic segmentation tasks, comparing it to other unsupervised domain adaptation methods like SADA, FPL, and CODA. The results show that ULDA consistently outperforms these baselines, demonstrating the benefits of leveraging language descriptions for zero-shot domain adaptation.
Critical Analysis
The authors acknowledge several limitations of the ULDA approach. First, the method relies on high-quality natural language descriptions of the target domain, which may not always be available. Additionally, the performance of ULDA is still dependent on the quality of the pre-trained language model used to encode the descriptions.
Another potential issue is that the language-constrained adaptation process may not capture all the relevant features of the target domain, as the language descriptions may not fully capture the visual characteristics. It would be interesting to see if combining ULDA with other unsupervised domain adaptation techniques, such as language-guided instance-aware adaptation, could further improve the results.
Overall, the ULDA method represents an interesting and promising approach to zero-shot domain adaptation, with the potential to significantly reduce the burden of data collection and labeling for real-world machine learning deployments. Further research is needed to address the identified limitations and explore potential synergies with other domain adaptation techniques.
Conclusion
The Unified Language-driven Zero-shot Domain Adaptation (ULDA) method introduced in this paper offers a novel way to adapt machine learning models to new domains without any labeled data. By leveraging natural language descriptions of the target domain, ULDA can perform effective zero-shot adaptation, outperforming other state-of-the-art unsupervised domain adaptation techniques.
This work highlights the potential of incorporating language-based information to guide the adaptation process, reducing the need for costly data collection and labeling efforts. As machine learning models become more widely deployed in real-world scenarios, methods like ULDA could play a crucial role in enabling seamless adaptation to new environments and use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
0
0
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
4/26/2024
🤷
Multi-Target Unsupervised Domain Adaptation for Semantic Segmentation without External Data
Yonghao Xu, Pedram Ghamisi, Yannis Avrithis
0
0
Multi-target unsupervised domain adaptation (UDA) aims to learn a unified model to address the domain shift between multiple target domains. Due to the difficulty of obtaining annotations for dense predictions, it has recently been introduced into cross-domain semantic segmentation. However, most existing solutions require labeled data from the source domain and unlabeled data from multiple target domains concurrently during training. Collectively, we refer to this data as external. When faced with new unlabeled data from an unseen target domain, these solutions either do not generalize well or require retraining from scratch on all data. To address these challenges, we introduce a new strategy called multi-target UDA without external data for semantic segmentation. Specifically, the segmentation model is initially trained on the external data. Then, it is adapted to a new unseen target domain without accessing any external data. This approach is thus more scalable than existing solutions and remains applicable when external data is inaccessible. We demonstrate this strategy using a simple method that incorporates self-distillation and adversarial learning, where knowledge acquired from the external data is preserved during adaptation through one-way adversarial learning. Extensive experiments in several synthetic-to-real and real-to-real adaptation settings on four benchmark urban driving datasets show that our method significantly outperforms current state-of-the-art solutions, even in the absence of external data. Our source code is available online (https://github.com/YonghaoXu/UT-KD).
5/13/2024

Enhancing Domain Adaptation through Prompt Gradient Alignment
Hoang Phan, Lam Tran, Quyen Tran, Trung Le
0
0
Prior Unsupervised Domain Adaptation (UDA) methods often aim to train a domain-invariant feature extractor, which may hinder the model from learning sufficiently discriminative features. To tackle this, a line of works based on prompt learning leverages the power of large-scale pre-trained vision-language models to learn both domain-invariant and specific features through a set of domain-agnostic and domain-specific learnable prompts. Those studies typically enforce invariant constraints on representation, output, or prompt space to learn such prompts. Differently, we cast UDA as a multiple-objective optimization problem in which each objective is represented by a domain loss. Under this new framework, we propose aligning per-objective gradients to foster consensus between them. Additionally, to prevent potential overfitting when fine-tuning this deep learning architecture, we penalize the norm of these gradients. To achieve these goals, we devise a practical gradient update procedure that can work under both single-source and multi-source UDA. Empirically, our method consistently surpasses other prompt-based baselines by a large margin on different UDA benchmarks
6/14/2024
👀
Source-Free Domain Adaptation Guided by Vision and Vision-Language Pre-Training
Wenyu Zhang, Li Shen, Chuan-Sheng Foo
0
0
Source-free domain adaptation (SFDA) aims to adapt a source model trained on a fully-labeled source domain to a related but unlabeled target domain. While the source model is a key avenue for acquiring target pseudolabels, the generated pseudolabels may exhibit source bias. In the conventional SFDA pipeline, a large data (e.g. ImageNet) pre-trained feature extractor is used to initialize the source model at the start of source training, and subsequently discarded. Despite having diverse features important for generalization, the pre-trained feature extractor can overfit to the source data distribution during source training and forget relevant target domain knowledge. Rather than discarding this valuable knowledge, we introduce an integrated framework to incorporate pre-trained networks into the target adaptation process. The proposed framework is flexible and allows us to plug modern pre-trained networks into the adaptation process to leverage their stronger representation learning capabilities. For adaptation, we propose the Co-learn algorithm to improve target pseudolabel quality collaboratively through the source model and a pre-trained feature extractor. Building on the recent success of the vision-language model CLIP in zero-shot image recognition, we present an extension Co-learn++ to further incorporate CLIP's zero-shot classification decisions. We evaluate on 3 benchmark datasets and include more challenging scenarios such as open-set, partial-set and open-partial SFDA. Experimental results demonstrate that our proposed strategy improves adaptation performance and can be successfully integrated with existing SFDA methods.
5/7/2024