Unified Negative Pair Generation toward Well-discriminative Feature Space for Face Recognition

0
🛸
Sign in to get full access
Overview
- The paper proposes a new approach called Unified Negative Pair Generation (UNPG) for face recognition tasks
- UNPG combines two existing pair generation strategies to overcome their individual limitations
- UNPG is shown to outperform state-of-the-art loss functions on public benchmark datasets
Plain English Explanation
The goal of face recognition is to create a well-discriminative feature space where the similarity between positive pairs (images of the same person) is maximized, while the similarity between negative pairs (images of different people) is minimized.
Existing deep learning approaches for this task, such as metric learning and classification loss, use different strategies to generate positive and negative training pairs. However, these strategies have limitations. Metric learning cannot generate negative pairs from all classes due to the small batch size, while classification loss struggles to generate extremely hard negative pairs as the class weights converge.
To address this, the paper proposes a new approach called UNPG that combines the benefits of both pair generation strategies. UNPG introduces useful information about negative pairs from the metric learning approach to overcome the limitations of the classification loss approach. It also includes a filtering step to remove noisy negative pairs and ensure reliable convergence.
Through extensive experiments, the authors show that UNPG achieves state-of-the-art performance on public face recognition benchmarks compared to recent loss functions.
Technical Explanation
The paper views the goal of face recognition as a pair similarity optimization problem. The objective is to maximize the similarity of positive pairs (images of the same person) while minimizing the similarity of negative pairs (images of different people). This is done by learning a well-discriminative feature space where the similarity of positive pairs is greater than the similarity of negative pairs.
Existing deep learning approaches for this task can be unified under different pair generation (PG) strategies. The metric learning (ML) loss is limited by the small batch size, which makes it infeasible to generate negative pairs from all classes. Conversely, the classification (CL) loss struggles to generate extremely hard negative pairs as the class weight vectors converge to their centers.
To address these limitations, the paper proposes a Unified Negative Pair Generation (UNPG) approach. UNPG combines the MLPG and CLPG strategies to leverage the benefits of both. It introduces useful information about negative pairs from MLPG to overcome the deficiencies of CLPG. Additionally, UNPG includes a filtering step to remove noisy negative pairs and ensure reliable convergence.
The authors conduct extensive experiments on public face recognition benchmarks and show that UNPG outperforms state-of-the-art loss functions. The code and pretrained models are publicly available.
Critical Analysis
The paper presents a novel and promising approach to addressing the limitations of existing pair generation strategies for face recognition tasks. By combining the strengths of metric learning and classification loss, UNPG appears to offer a more robust and effective solution.
However, the paper does not discuss the potential computational overhead or training time implications of the UNPG approach. Generating and filtering negative pairs from both MLPG and CLPG strategies may introduce additional complexity and processing requirements compared to the individual approaches.
Additionally, the paper does not explore the generalizability of UNPG beyond face recognition tasks. It would be interesting to see if the benefits of this unified approach could extend to other domains where pair similarity optimization is crucial, such as image retrieval or person re-identification.
Overall, the UNPG approach presented in this paper represents an important contribution to the field of face recognition. However, further research is needed to fully understand the practical implications and potential limitations of this technique.
Conclusion
This paper proposes a novel Unified Negative Pair Generation (UNPG) approach for face recognition tasks. UNPG combines the strengths of existing pair generation strategies, such as metric learning and classification loss, to overcome their individual limitations. The authors demonstrate that UNPG achieves state-of-the-art performance on public benchmarks, suggesting that this unified approach can lead to more robust and effective face recognition models. While the paper raises some questions about the computational complexity and generalizability of UNPG, it represents an important step forward in addressing the challenges of pair similarity optimization in deep learning-based face recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Unified Negative Pair Generation toward Well-discriminative Feature Space for Face Recognition
Junuk Jung, Seonhoon Lee, Heung-Seon Oh, Yongjun Park, Joochan Park, Sungbin Son
The goal of face recognition (FR) can be viewed as a pair similarity optimization problem, maximizing a similarity set $mathcal{S}^p$ over positive pairs, while minimizing similarity set $mathcal{S}^n$ over negative pairs. Ideally, it is expected that FR models form a well-discriminative feature space (WDFS) that satisfies $inf{mathcal{S}^p} > sup{mathcal{S}^n}$. With regard to WDFS, the existing deep feature learning paradigms (i.e., metric and classification losses) can be expressed as a unified perspective on different pair generation (PG) strategies. Unfortunately, in the metric loss (ML), it is infeasible to generate negative pairs taking all classes into account in each iteration because of the limited mini-batch size. In contrast, in classification loss (CL), it is difficult to generate extremely hard negative pairs owing to the convergence of the class weight vectors to their center. This leads to a mismatch between the two similarity distributions of the sampled pairs and all negative pairs. Thus, this paper proposes a unified negative pair generation (UNPG) by combining two PG strategies (i.e., MLPG and CLPG) from a unified perspective to alleviate the mismatch. UNPG introduces useful information about negative pairs using MLPG to overcome the CLPG deficiency. Moreover, it includes filtering the similarities of noisy negative pairs to guarantee reliable convergence and improved performance. Exhaustive experiments show the superiority of UNPG by achieving state-of-the-art performance across recent loss functions on public benchmark datasets. Our code and pretrained models are publicly available.
Read more4/22/2024

0
Adaptive Multi-head Contrastive Learning
Lei Wang, Piotr Koniusz, Tom Gedeon, Liang Zheng
In contrastive learning, two views of an original image, generated by different augmentations, are considered a positive pair, and their similarity is required to be high. Similarly, two views of distinct images form a negative pair, with encouraged low similarity. Typically, a single similarity measure, provided by a lone projection head, evaluates positive and negative sample pairs. However, due to diverse augmentation strategies and varying intra-sample similarity, views from the same image may not always be similar. Additionally, owing to inter-sample similarity, views from different images may be more akin than those from the same image. Consequently, enforcing high similarity for positive pairs and low similarity for negative pairs may be unattainable, and in some cases, such enforcement could detrimentally impact performance. To address this challenge, we propose using multiple projection heads, each producing a distinct set of features. Our pre-training loss function emerges from a solution to the maximum likelihood estimation over head-wise posterior distributions of positive samples given observations. This loss incorporates the similarity measure over positive and negative pairs, each re-weighted by an individual adaptive temperature, regulated to prevent ill solutions. Our approach, Adaptive Multi-Head Contrastive Learning (AMCL), can be applied to and experimentally enhances several popular contrastive learning methods such as SimCLR, MoCo, and Barlow Twins. The improvement remains consistent across various backbones and linear probing epochs, and becomes more significant when employing multiple augmentation methods.
Read more7/11/2024

0
Unsupervised Generative Feature Transformation via Graph Contrastive Pre-training and Multi-objective Fine-tuning
Wangyang Ying, Dongjie Wang, Xuanming Hu, Yuanchun Zhou, Charu C. Aggarwal, Yanjie Fu
Feature transformation is to derive a new feature set from original features to augment the AI power of data. In many science domains such as material performance screening, while feature transformation can model material formula interactions and compositions and discover performance drivers, supervised labels are collected from expensive and lengthy experiments. This issue motivates an Unsupervised Feature Transformation Learning (UFTL) problem. Prior literature, such as manual transformation, supervised feedback guided search, and PCA, either relies on domain knowledge or expensive supervised feedback, or suffers from large search space, or overlooks non-linear feature-feature interactions. UFTL imposes a major challenge on existing methods: how to design a new unsupervised paradigm that captures complex feature interactions and avoids large search space? To fill this gap, we connect graph, contrastive, and generative learning to develop a measurement-pretrain-finetune paradigm for UFTL. For unsupervised feature set utility measurement, we propose a feature value consistency preservation perspective and develop a mean discounted cumulative gain like unsupervised metric to evaluate feature set utility. For unsupervised feature set representation pretraining, we regard a feature set as a feature-feature interaction graph, and develop an unsupervised graph contrastive learning encoder to embed feature sets into vectors. For generative transformation finetuning, we regard a feature set as a feature cross sequence and feature transformation as sequential generation. We develop a deep generative feature transformation model that coordinates the pretrained feature set encoder and the gradient information extracted from a feature set utility evaluator to optimize a transformed feature generator.
Read more5/28/2024
0
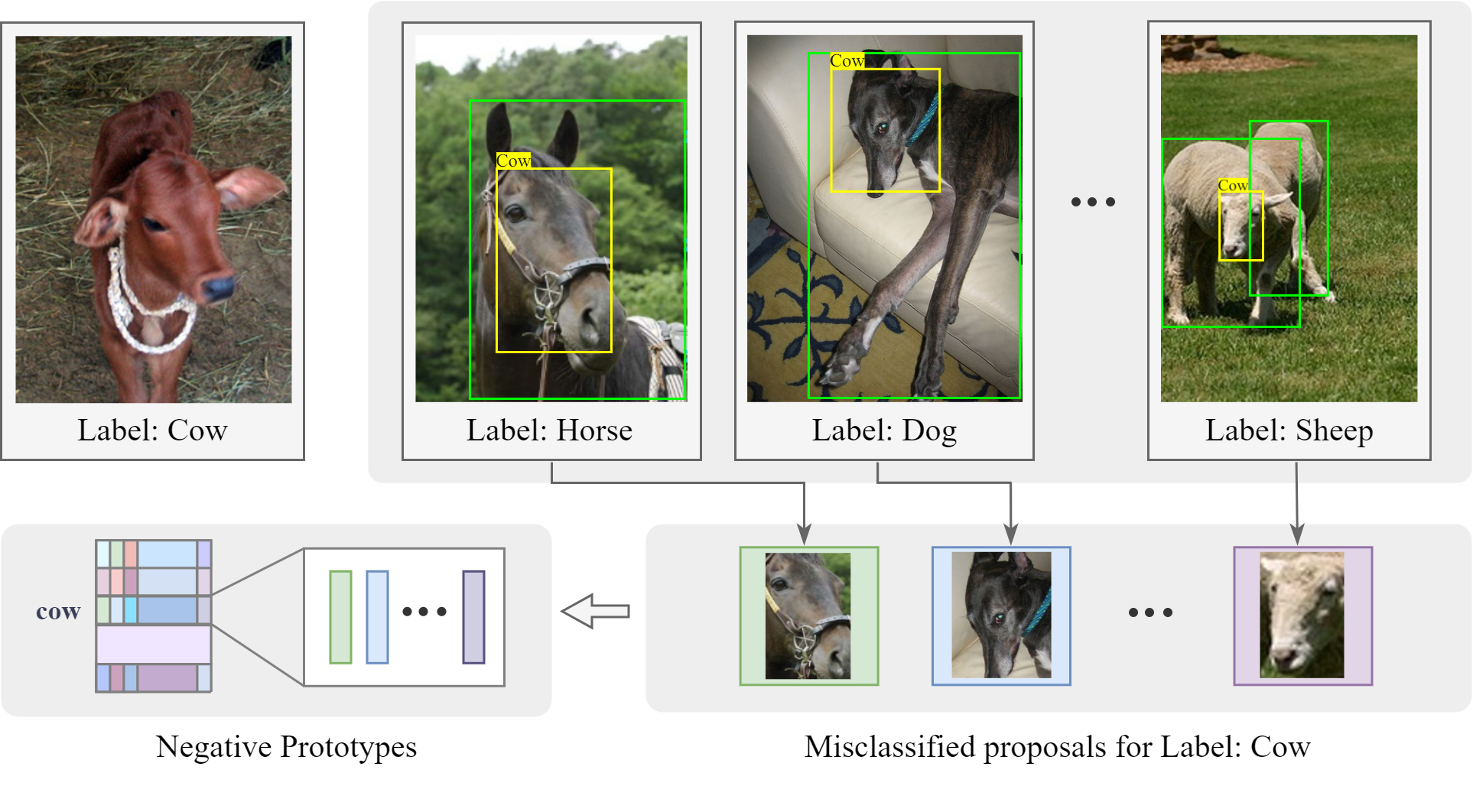
Negative Prototypes Guided Contrastive Learning for WSOD
Yu Zhang, Chuang Zhu, Guoqing Yang, Siqi Chen
Weakly Supervised Object Detection (WSOD) with only image-level annotation has recently attracted wide attention. Many existing methods ignore the inter-image relationship of instances which share similar characteristics while can certainly be determined not to belong to the same category. Therefore, in order to make full use of the weak label, we propose the Negative Prototypes Guided Contrastive learning (NPGC) architecture. Firstly, we define Negative Prototype as the proposal with the highest confidence score misclassified for the category that does not appear in the label. Unlike other methods that only utilize category positive feature, we construct an online updated global feature bank to store both positive prototypes and negative prototypes. Meanwhile, we propose a pseudo label sampling module to mine reliable instances and discard the easily misclassified instances based on the feature similarity with corresponding prototypes in global feature bank. Finally, we follow the contrastive learning paradigm to optimize the proposal's feature representation by attracting same class samples closer and pushing different class samples away in the embedding space. Extensive experiments have been conducted on VOC07, VOC12 datasets, which shows that our proposed method achieves the state-of-the-art performance.
Read more6/28/2024