GCC: Generative Calibration Clustering

0

Sign in to get full access
Overview
- This paper introduces a novel clustering approach called Generative Calibration Clustering (GCC) that aims to address the limitations of existing clustering methods.
- GCC combines generative modeling, calibration, and clustering to enable more effective discovery of new patterns and prototypes in complex, high-dimensional datasets.
- The proposed method outperforms state-of-the-art techniques on a range of clustering benchmarks, showcasing its ability to identify meaningful clusters and prototypes.
Plain English Explanation
Clustering is a common way to organize and make sense of large datasets by grouping similar data points together. However, traditional clustering methods can struggle when faced with complex, high-dimensional data that may have underlying structures or patterns that are not easily identifiable.
The GCC approach introduced in this paper tries to address these limitations by combining several key ideas. First, it uses a generative model to learn a flexible representation of the data, capturing the underlying structure and patterns. This generative model is then "calibrated" to ensure that the probabilities it assigns to data points are well-calibrated, meaning they accurately reflect the true likelihood of those points belonging to the identified clusters.
Finally, the calibrated generative model is used to perform the actual clustering, grouping together data points that are most likely to belong to the same cluster or prototype. This combination of generative modeling, calibration, and clustering allows GCC to discover meaningful clusters and prototypes in complex datasets that may have eluded traditional clustering methods.
The researchers demonstrate the effectiveness of GCC through a series of experiments on various benchmark datasets, showing that it outperforms state-of-the-art clustering techniques. This suggests that GCC could be a valuable tool for researchers and practitioners working with large, high-dimensional datasets in fields like link to related research or link to related research.
Technical Explanation
The core of the GCC approach is a generative model that learns a flexible representation of the input data. This generative model is then calibrated to ensure that the probabilities it assigns to data points accurately reflect their true likelihood of belonging to the identified clusters. Finally, the calibrated generative model is used to perform the actual clustering, grouping together data points that are most likely to belong to the same cluster or prototype.
The generative model used in GCC is based on a deep latent variable model, which learns a low-dimensional latent representation of the high-dimensional input data. This latent representation is then used to generate new data points that resemble the original inputs, effectively capturing the underlying structure of the dataset.
To calibrate the generative model, the researchers employ a technique called Temperature Scaling, which adjusts the model's output probabilities to better match the true likelihood of data points belonging to each cluster. This calibration step is crucial for ensuring that the clustering process accurately reflects the actual structure of the data.
The calibrated generative model is then used to perform the clustering itself. The researchers leverage a modified version of the K-Means algorithm, which assigns data points to the cluster with the highest probability according to the calibrated generative model. This allows GCC to identify not only well-separated clusters, but also more complex, overlapping structures and prototypes within the data.
The performance of GCC is evaluated on a range of clustering benchmarks, including link to related research, link to related research, and link to related research. The results demonstrate that GCC consistently outperforms state-of-the-art clustering methods, particularly on datasets with complex, high-dimensional structures.
Critical Analysis
One potential limitation of the GCC approach is its reliance on the accuracy of the generative model. If the generative model fails to capture the true underlying structure of the data, the subsequent calibration and clustering steps may be adversely affected. The researchers acknowledge this and suggest that further research is needed to explore more advanced generative modeling techniques that can better handle complex, high-dimensional data.
Additionally, the computational complexity of GCC may be a concern, as the combination of generative modeling, calibration, and clustering can be resource-intensive, especially for large-scale datasets. The researchers discuss potential ways to improve the efficiency of the approach, such as leveraging approximate inference techniques or parallelization, but these optimizations are not explored in depth in the current paper.
Another area for further investigation is the interpretability of the GCC-derived clusters and prototypes. While the method demonstrates strong performance on clustering benchmarks, it is not always clear how to interpret the meaning or significance of the identified clusters. Incorporating techniques for improving the interpretability of the clustering results could enhance the practical value of the GCC approach.
Despite these potential limitations, the GCC method represents a significant contribution to the field of clustering, addressing important challenges that have long plagued traditional clustering techniques. The researchers have demonstrated the potential of combining generative modeling, calibration, and clustering to uncover meaningful patterns and structures in complex, high-dimensional data, opening up new avenues for further research and development in this area.
Conclusion
The GCC method introduced in this paper offers a novel approach to clustering that combines generative modeling, calibration, and clustering to enable more effective discovery of new patterns and prototypes in complex, high-dimensional datasets. The researchers have shown that GCC outperforms state-of-the-art clustering techniques on a range of benchmarks, indicating its potential to be a valuable tool for researchers and practitioners working with large, complex datasets in fields like link to related research, link to related research, and link to related research.
While the method has some potential limitations, such as its reliance on the accuracy of the generative model and its computational complexity, the researchers have outlined promising directions for future research to address these challenges. Overall, the GCC approach represents a significant advancement in the field of clustering, demonstrating the power of combining generative modeling, calibration, and clustering to uncover meaningful insights in complex, high-dimensional data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GCC: Generative Calibration Clustering
Haifeng Xia, Hai Huang, Zhengming Ding
Deep clustering as an important branch of unsupervised representation learning focuses on embedding semantically similar samples into the identical feature space. This core demand inspires the exploration of contrastive learning and subspace clustering. However, these solutions always rely on the basic assumption that there are sufficient and category-balanced samples for generating valid high-level representation. This hypothesis actually is too strict to be satisfied for real-world applications. To overcome such a challenge, the natural strategy is utilizing generative models to augment considerable instances. How to use these novel samples to effectively fulfill clustering performance improvement is still difficult and under-explored. In this paper, we propose a novel Generative Calibration Clustering (GCC) method to delicately incorporate feature learning and augmentation into clustering procedure. First, we develop a discriminative feature alignment mechanism to discover intrinsic relationship across real and generated samples. Second, we design a self-supervised metric learning to generate more reliable cluster assignment to boost the conditional diffusion generation. Extensive experimental results on three benchmarks validate the effectiveness and advantage of our proposed method over the state-of-the-art methods.
Read more4/16/2024
0
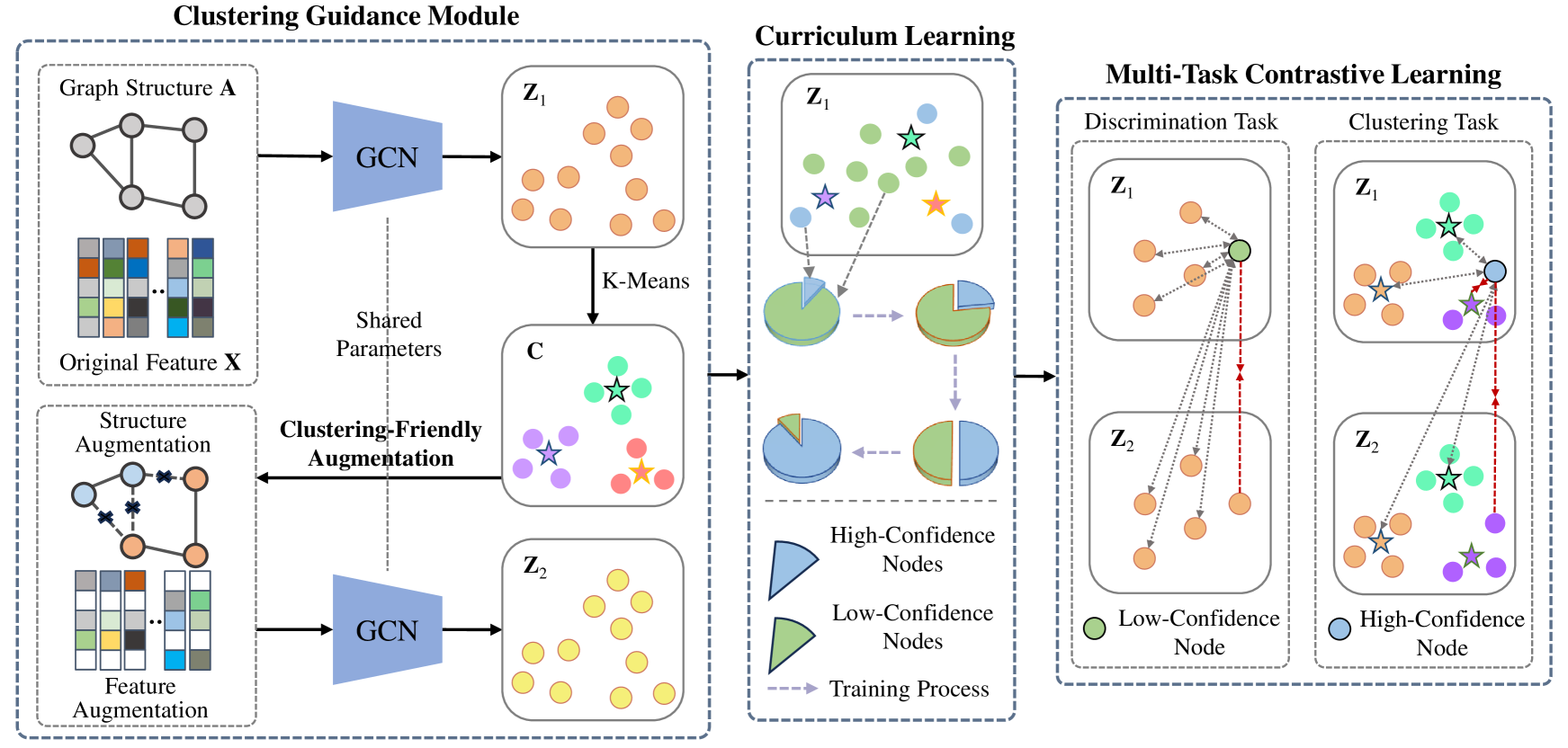
Multi-Task Curriculum Graph Contrastive Learning with Clustering Entropy Guidance
Chusheng Zeng, Bocheng Wang, Jinghui Yuan, Rong Wang, Mulin Chen
Recent advances in unsupervised deep graph clustering have been significantly promoted by contrastive learning. Despite the strides, most graph contrastive learning models face challenges: 1) graph augmentation is used to improve learning diversity, but commonly used random augmentation methods may destroy inherent semantics and cause noise; 2) the fixed positive and negative sample selection strategy is limited to deal with complex real data, thereby impeding the model's capability to capture fine-grained patterns and relationships. To reduce these problems, we propose the Clustering-guided Curriculum Graph contrastive Learning (CCGL) framework. CCGL uses clustering entropy as the guidance of the following graph augmentation and contrastive learning. Specifically, according to the clustering entropy, the intra-class edges and important features are emphasized in augmentation. Then, a multi-task curriculum learning scheme is proposed, which employs the clustering guidance to shift the focus from the discrimination task to the clustering task. In this way, the sample selection strategy of contrastive learning can be adjusted adaptively from early to late stage, which enhances the model's flexibility for complex data structure. Experimental results demonstrate that CCGL has achieved excellent performance compared to state-of-the-art competitors.
Read more8/23/2024
❗
0
Topology Reorganized Graph Contrastive Learning with Mitigating Semantic Drift
Jiaqiang Zhang, Songcan Chen
Graph contrastive learning (GCL) is an effective paradigm for node representation learning in graphs. The key components hidden behind GCL are data augmentation and positive-negative pair selection. Typical data augmentations in GCL, such as uniform deletion of edges, are generally blind and resort to local perturbation, which is prone to producing under-diversity views. Additionally, there is a risk of making the augmented data traverse to other classes. Moreover, most methods always treat all other samples as negatives. Such a negative pairing naturally results in sampling bias and likewise may make the learned representation suffer from semantic drift. Therefore, to increase the diversity of the contrastive view, we propose two simple and effective global topological augmentations to compensate current GCL. One is to mine the semantic correlation between nodes in the feature space. The other is to utilize the algebraic properties of the adjacency matrix to characterize the topology by eigen-decomposition. With the help of both, we can retain important edges to build a better view. To reduce the risk of semantic drift, a prototype-based negative pair selection is further designed which can filter false negative samples. Extensive experiments on various tasks demonstrate the advantages of the model compared to the state-of-the-art methods.
Read more7/25/2024

0
Clustering-friendly Representation Learning for Enhancing Salient Features
Toshiyuki Oshima, Kentaro Takagi, Kouta Nakata
Recently, representation learning with contrastive learning algorithms has been successfully applied to challenging unlabeled datasets. However, these methods are unable to distinguish important features from unimportant ones under simply unsupervised settings, and definitions of importance vary according to the type of downstream task or analysis goal, such as the identification of objects or backgrounds. In this paper, we focus on unsupervised image clustering as the downstream task and propose a representation learning method that enhances features critical to the clustering task. We extend a clustering-friendly contrastive learning method and incorporate a contrastive analysis approach, which utilizes a reference dataset to separate important features from unimportant ones, into the design of loss functions. Conducting an experimental evaluation of image clustering for three datasets with characteristic backgrounds, we show that for all datasets, our method achieves higher clustering scores compared with conventional contrastive analysis and deep clustering methods.
Read more8/12/2024