A Unified Programming Model for Heterogeneous Computing with CPU and Accelerator Technologies
2204.06864
0
0
📈
Abstract
This paper consists of three parts. The first part provides a unified programming model for heterogeneous computing with CPU and accelerator (like GPU, FPGA, Google TPU, Atos QPU, and more) technologies. To some extent, this new programming model makes programming across CPUs and accelerators turn into usual programming tasks with common programming languages, and relieves complexity of programming across CPUs and accelerators. It can be achieved by extending file managements in common programming languages, such as C/C++, Fortran, Python, MPI, etc., to cover accelerators as I/O devices. In the second part, we show that all types of computer systems can be reduced to the simplest type of computer system, a single-core CPU computer system with I/O devices, by the unified programming model. Thereby, the unified programming model can truly build the programming of various computer systems on one API (i.e. file managements of common programming languages), and can make programming for various computer systems easier. In third part, we present a new approach to coupled applications computing (like multidisciplinary simulations) by the unified programming model. The unified programming model makes coupled applications computing more natural and easier since it only relies on its own power to couple multiple applications through MPI.
Create account to get full access
Overview
- This paper presents a unified programming model to simplify the task of programming across different types of computer hardware, including CPUs and accelerators like GPUs, FPGAs, and specialized chips.
- The model aims to make programming for diverse hardware systems as easy as programming for a single-core CPU computer with input/output (I/O) devices.
- The paper also demonstrates how this unified programming model can be used to streamline the development of coupled applications, such as multidisciplinary simulations.
Plain English Explanation
The paper introduces a new way to program computer systems that have a mix of different hardware components, like regular CPUs and specialized accelerators like GPUs, FPGAs, or Google TPUs.
Normally, programming for these mixed hardware systems can be quite complex, as each type of hardware has its own unique programming requirements. The researchers' approach aims to simplify this by treating the accelerators as if they were just another type of input/output (I/O) device that can be managed using common programming languages like C/C++, Fortran, or Python.
This means that programmers can use the same file management tools they're already familiar with to interact with the accelerators, just like they would with a hard drive or other peripheral. The paper shows how this can make programming for diverse hardware systems as easy as programming for a basic single-core CPU computer.
The researchers also demonstrate how this unified programming model can be used to more easily connect different software applications together, like in multidisciplinary simulations. By relying on standard file management techniques, the model makes it simpler to link these coupled applications without requiring extensive custom code.
Technical Explanation
The paper's first part introduces a unified programming model that treats accelerators like GPUs, FPGAs, and specialized chips as I/O devices that can be accessed through common programming languages and file management APIs. This allows programmers to interact with these hardware components using the same tools they're already familiar with, rather than having to learn custom programming models for each type of accelerator.
In the second part, the researchers show how this unified programming model can be used to abstract away the complexities of different hardware architectures. By reducing all computer systems to the simplest case of a single-core CPU with I/O devices, the model makes it easier to write code that can run on a wide variety of hardware configurations.
The third part of the paper demonstrates how the unified programming model can be applied to simplify the development of coupled applications, such as multidisciplinary simulations. By relying on standard file management techniques to connect different software components, the model eliminates the need for custom integration code, making these types of applications more accessible to programmers.
Critical Analysis
The paper presents a compelling approach to simplifying programming for heterogeneous computer systems, but there are a few potential limitations and areas for further research:
-
While the unified programming model aims to abstract away hardware complexities, it's unclear how well it would scale to extremely large or specialized systems, such as supercomputers or specialized AI hardware. Further testing and evaluation may be needed to assess its practical limitations.
-
The paper focuses on the programming model itself, but doesn't provide much detail on the actual implementation or performance implications. It would be helpful to see more empirical data on the real-world impacts of this approach, both in terms of programmer productivity and system performance.
-
The authors do not address potential security or privacy concerns that may arise from treating accelerators as generic I/O devices. Depending on the specific use case, there could be risks associated with this level of hardware abstraction that would need to be carefully considered.
Overall, the unified programming model presented in this paper represents an interesting and potentially impactful step towards making heterogeneous computing systems more accessible to a wider range of programmers. With further research and development, this approach could help democratize access to advanced hardware capabilities across a variety of applications and industries.
Conclusion
This paper introduces a novel unified programming model that aims to simplify the task of programming across diverse computer hardware, including CPUs and various types of accelerators. By treating these accelerators as generic I/O devices that can be accessed through common programming languages and file management APIs, the model seeks to make it easier for developers to leverage the capabilities of heterogeneous computing systems.
The researchers demonstrate how this approach can abstract away the complexities of different hardware architectures, reducing all computer systems to the basic case of a single-core CPU with I/O devices. They also show how the unified programming model can be applied to streamline the development of coupled applications, such as multidisciplinary simulations.
While the paper presents a promising concept, there are still some open questions and areas for further research, such as scalability, performance impacts, and potential security considerations. Nevertheless, this work represents an interesting step forward in making advanced hardware capabilities more accessible to a wider range of programmers and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fork is All You Needed in Heterogeneous Systems
Zixuan Wang, Jishen Zhao
0
0
We present a unified programming model for heterogeneous computing systems. Such systems integrate multiple computing accelerators and memory units to deliver higher performance than CPU-centric systems. Although heterogeneous systems have been adopted by modern workloads such as machine learning, programming remains a critical limiting factor. Conventional heterogeneous programming techniques either impose heavy modifications to the code base or require rewriting the program in a different language. Such programming complexity stems from the lack of a unified abstraction layer for computing and data exchange, which forces each programming model to define its abstractions. However, with the emerging cache-coherent interconnections such as Compute Express Link, we see an opportunity to standardize such architecture heterogeneity and provide a unified programming model. We present CodeFlow, a language runtime system for heterogeneous computing. CodeFlow abstracts architecture computation in programming language runtime and utilizes CXL as a unified data exchange protocol. Workloads written in high-level languages such as C++ and Rust can be compiled to CodeFlow, which schedules different parts of the workload to suitable accelerators without requiring the developer to implement code or call APIs for specific accelerators. CodeFlow reduces programmers' effort in utilizing heterogeneous systems and improves workload performance.
4/9/2024
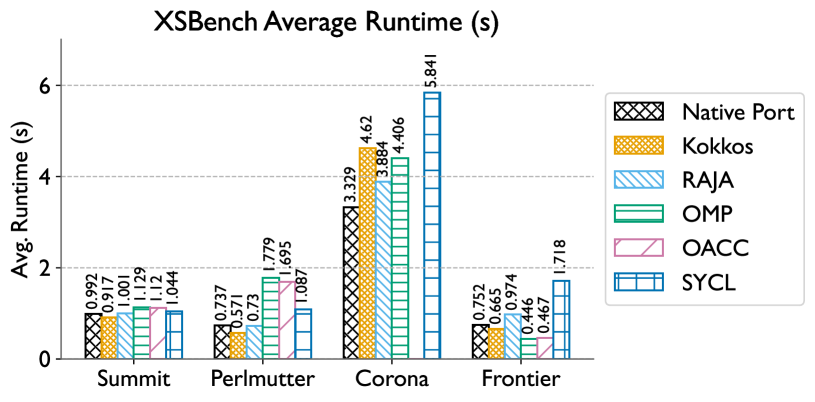
Taking GPU Programming Models to Task for Performance Portability
Joshua H. Davis, Pranav Sivaraman, Joy Kitson, Konstantinos Parasyris, Harshitha Menon, Isaac Minn, Giorgis Georgakoudis, Abhinav Bhatele
0
0
Portability is critical to ensuring high productivity in developing and maintaining scientific software as the diversity in on-node hardware architectures increases. While several programming models provide portability for diverse GPU platforms, they don't make any guarantees about performance portability. In this work, we explore several programming models -- CUDA, HIP, Kokkos, RAJA, OpenMP, OpenACC, and SYCL, to study if the performance of these models is consistently good across NVIDIA and AMD GPUs. We use five proxy applications from different scientific domains, create implementations where missing, and use them to present a comprehensive comparative evaluation of the programming models. We provide a Spack scripting-based methodology to ensure reproducibility of experiments conducted in this work. Finally, we attempt to answer the question -- to what extent does each programming model provide performance portability for heterogeneous systems in real-world usage?
5/22/2024

HetHub: A Heterogeneous distributed hybrid training system for large-scale models
Si Xu, Zixiao Huang, Yan Zeng, Shengen Yan, Xuefei Ning, Haolin Ye, Sipei Gu, Chunsheng Shui, Zhezheng Lin, Hao Zhang, Sheng Wang, Guohao Dai, Yu Wang
0
0
The development of large-scale models relies on a vast number of computing resources. For example, the GPT-4 model (1.8 trillion parameters) requires 25000 A100 GPUs for its training. It is a challenge to build a large-scale cluster with a type of GPU-accelerator. Using multiple types of GPU-accelerators to construct a cluster is an effective way to solve the problem of insufficient homogeneous GPU-accelerators. However, the existing distributed training systems for large-scale models only support homogeneous GPU-accelerators, not heterogeneous GPU-accelerators. To address the problem, this paper proposes a distributed training system with hybrid parallelism support on heterogeneous GPU-accelerators for large-scale models. It introduces a distributed unified communicator to realize the communication between heterogeneous GPU-accelerators, a distributed performance predictor, and an automatic hybrid parallel module to develop and train models efficiently with heterogeneous GPU-accelerators. Compared to the distributed training system with homogeneous GPU-accelerators, our system can support six different combinations of heterogeneous GPU-accelerators and the optimal performance of heterogeneous GPU-accelerators has achieved at least 90% of the theoretical upper bound performance of homogeneous GPU-accelerators.
5/28/2024

Supercomputers as a Continous Medium
Martin Karp, Niclas Jansson, Philipp Schlatter, Stefano Markidis
0
0
As supercomputers' complexity has grown, the traditional boundaries between processor, memory, network, and accelerators have blurred, making a homogeneous computer model, in which the overall computer system is modeled as a continuous medium with homogeneously distributed computational power, memory, and data movement transfer capabilities, an intriguing and powerful abstraction. By applying a homogeneous computer model to algorithms with a given I/O complexity, we recover from first principles, other discrete computer models, such as the roofline model, parallel computing laws, such as Amdahl's and Gustafson's laws, and phenomenological observations, such as super-linear speedup. One of the homogeneous computer model's distinctive advantages is the capability of directly linking the performance limits of an application to the physical properties of a classical computer system. Applying the homogeneous computer model to supercomputers, such as Frontier, Fugaku, and the Nvidia DGX GH200, shows that applications, such as Conjugate Gradient (CG) and Fast Fourier Transforms (FFT), are rapidly approaching the fundamental classical computational limits, where the performance of even denser systems in terms of compute and memory are fundamentally limited by the speed of light.
5/10/2024