Taking GPU Programming Models to Task for Performance Portability

0
Sign in to get full access
Overview
- This paper provides an evaluation and comparison of the performance portability of different GPU programming models.
- The authors assess how well various programming models can achieve high performance across different GPU hardware.
- The study focuses on stencil computations, a common type of algorithm used in scientific computing applications.
Plain English Explanation
The paper examines different ways of writing code to run on graphics processing units (GPUs), which are specialized hardware that can perform certain types of calculations much faster than regular computer processors. The goal is to understand how well these different "programming models" allow the code to achieve high performance when run on different GPU hardware.
The researchers focused on a common type of computation called a "stencil", which is used in many scientific computing applications like simulations. They wrote the same stencil computation using several different programming models, such as CUDA, OpenCL, and Kokkos. Then they ran this code on different GPU hardware and measured how fast it executed, to see which programming model provided the best "performance portability" - the ability to achieve high performance regardless of the specific GPU being used.
The key finding is that some programming models, like Kokkos, were better able to deliver consistent high performance across a range of GPUs, while others like CUDA were more tuned for a specific GPU architecture. This has important implications for developers who need to write code that will run efficiently on different hardware.
Technical Explanation
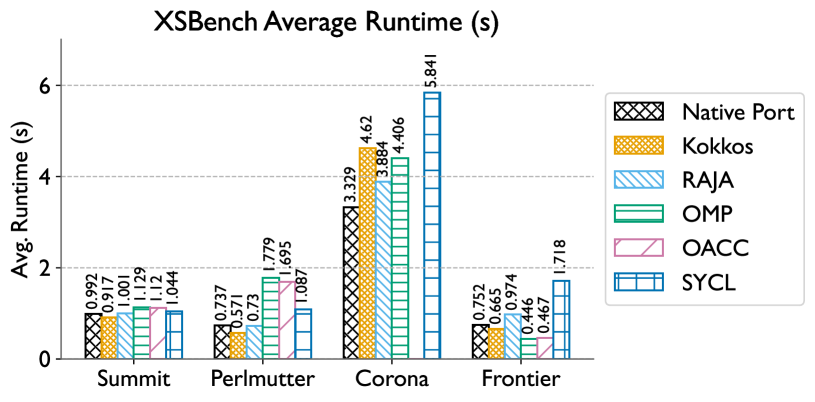
The paper evaluates the performance portability of several GPU programming models, including CUDA, OpenCL, Kokkos, and SYCL. The authors implement a common stencil computation kernel using these different programming models and evaluate their performance on a variety of GPU hardware, including NVIDIA Volta, AMD CDNA, and Intel Xe.
The results show that the Kokkos programming model is able to achieve the highest level of performance portability, with consistent high performance across the different GPU architectures tested. In contrast, CUDA exhibits the lowest performance portability, with its performance being heavily dependent on the specific GPU hardware. The authors attribute this to CUDA's deep integration with NVIDIA's GPU architecture, whereas Kokkos uses a more abstracted, hardware-agnostic approach.
The paper also includes a detailed analysis of the factors contributing to the performance differences, such as memory access patterns, kernel launch overhead, and compiler optimizations. The authors provide valuable insights into the tradeoffs and design considerations of these programming models in the context of stencil computations.
Critical Analysis
The paper provides a thorough and well-designed evaluation of performance portability across GPU programming models. The focus on stencil computations, a common and important class of algorithms, makes the findings particularly relevant for scientific computing applications.
One limitation of the study is that it only considers a single type of computation (stencil) and a limited set of GPU architectures. The performance portability of these programming models may differ for other types of algorithms or hardware. Additionally, the paper does not delve into the programming complexity or development productivity aspects of these models, which can also be important factors for developers.
Further research could explore the performance portability of these programming models on a wider range of applications and hardware, as well as investigate the trade-offs between performance, portability, and developer productivity. Comparisons with emerging programming models, such as SYCL and OpenMP 5.0, could also provide additional insights.
Despite these potential areas for further study, the paper makes a valuable contribution by providing a comprehensive and rigorous evaluation of performance portability across several prominent GPU programming models. The findings can help inform the selection of programming models for developers targeting heterogeneous computing systems.
Conclusion
This paper presents an in-depth evaluation of the performance portability of various GPU programming models, including CUDA, OpenCL, Kokkos, and SYCL. The authors focus on stencil computations, a common algorithm used in scientific computing, and assess the ability of these models to achieve consistent high performance across different GPU hardware, such as NVIDIA Volta, AMD CDNA, and Intel Xe.
The key finding is that the Kokkos programming model exhibits the highest level of performance portability, with stable and efficient execution on the tested GPU architectures. In contrast, CUDA, which is tightly coupled with NVIDIA's GPU design, shows the lowest performance portability, with its performance heavily dependent on the specific hardware.
These insights are valuable for developers working on heterogeneous computing systems, as they highlight the trade-offs between programming model abstraction and hardware-specific optimization. The paper provides a comprehensive technical analysis and critical discussion, which can help inform the selection of the most appropriate programming model for a given application and target hardware.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Taking GPU Programming Models to Task for Performance Portability
Joshua H. Davis, Pranav Sivaraman, Joy Kitson, Konstantinos Parasyris, Harshitha Menon, Isaac Minn, Giorgis Georgakoudis, Abhinav Bhatele
Portability is critical to ensuring high productivity in developing and maintaining scientific software as the diversity in on-node hardware architectures increases. While several programming models provide portability for diverse GPU platforms, they don't make any guarantees about performance portability. In this work, we explore several programming models -- CUDA, HIP, Kokkos, RAJA, OpenMP, OpenACC, and SYCL, to study if the performance of these models is consistently good across NVIDIA and AMD GPUs. We use five proxy applications from different scientific domains, create implementations where missing, and use them to present a comprehensive comparative evaluation of the programming models. We provide a Spack scripting-based methodology to ensure reproducibility of experiments conducted in this work. Finally, we attempt to answer the question -- to what extent does each programming model provide performance portability for heterogeneous systems in real-world usage?
Read more5/22/2024
0
Evaluation of Programming Models and Performance for Stencil Computation on Current GPU Architectures
Baodi Shan, Mauricio Araya-Polo
Accelerated computing is widely used in high-performance computing. Therefore, it is crucial to experiment and discover how to better utilize GPUGPUs latest generations on relevant applications. In this paper, we present results and share insights about highly tuned stencil-based kernels for NVIDIA Ampere (A100) and Hopper (GH200) architectures. Performance results yield useful insights into the behavior of this type of algorithms for these new accelerators. This knowledge can be leveraged by many scientific applications which involve stencils computations. Further, evaluation of three different programming models: CUDA, OpenACC, and OpenMP target offloading is conducted on aforementioned accelerators. We extensively study the performance and portability of various kernels under each programming model and provide corresponding optimization recommendations. Furthermore, we compare the performance of different programming models on the mentioned architectures. Up to 58% performance improvement was achieved against the previous GPGPU's architecture generation for an highly optimized kernel of the same class, and up to 42% for all classes. In terms of programming models, and keeping portability in mind, optimized OpenACC implementation outperforms OpenMP implementation by 33%. If portability is not a factor, our best tuned CUDA implementation outperforms the optimized OpenACC one by 2.1x.
Read more8/13/2024
🎲
0
Challenging Portability Paradigms: FPGA Acceleration Using SYCL and OpenCL
Manuel de Castro, Francisco J. and'ujar, Roberto R. Osorio, Roc'io Carratal'a-S'aez, Diego R. Llanos
As the interest in FPGA-based accelerators for HPC applications increases, new challenges also arise, especially concerning different programming and portability issues. This paper aims to provide a snapshot of the current state of the FPGA tooling and its problems. To do so, we evaluate the performance portability of two frameworks for developing FPGA solutions for HPC (SYCL and OpenCL) when using them to port a highly-parallel application to FPGAs, using both ND-range and single-task type of kernels. The developer's general recommendation when using FPGAs is to develop single-task kernels for them, as they are commonly regarded as more suited for such hardware. However, we discovered that, when using high-level approaches such as OpenCL and SYCL to program a highly-parallel application with no FPGA-tailored optimizations, ND-range kernels significantly outperform single-task codes. Specifically, while SYCL struggles to produce efficient FPGA implementations of applications described as single-task codes, its performance excels with ND-range kernels, a result that was unexpectedly favorable.
Read more9/6/2024
🚀
0
A Comparison of the Performance of the Molecular Dynamics Simulation Package GROMACS Implemented in the SYCL and CUDA Programming Models
L. Apanasevich, Yogesh Kale, Himanshu Sharma, Ana Marija Sokovic
For many years, systems running Nvidia-based GPU architectures have dominated the heterogeneous supercomputer landscape. However, recently GPU chipsets manufactured by Intel and AMD have cut into this market and can now be found in some of the worlds fastest supercomputers. The June 2023 edition of the TOP500 list of supercomputers ranks the Frontier supercomputer at the Oak Ridge National Laboratory in Tennessee as the top system in the world. This system features AMD Instinct 250 X GPUs and is currently the only true exascale computer in the world.The first framework that enabled support for heterogeneous platforms across multiple hardware vendors was OpenCL, in 2009. Since then a number of frameworks have been developed to support vendor agnostic heterogeneous environments including OpenMP, OpenCL, Kokkos, and SYCL. SYCL, which combines the concepts of OpenCL with the flexibility of single-source C++, is one of the more promising programming models for heterogeneous computing devices. One key advantage of this framework is that it provides a higher-level programming interface that abstracts away many of the hardware details than the other frameworks. This makes SYCL easier to learn and to maintain across multiple architectures and vendors. In n recent years, there has been growing interest in using heterogeneous computing architectures to accelerate molecular dynamics simulations. Some of the more popular molecular dynamics simulations include Amber, NAMD, and Gromacs. However, to the best of our knowledge, only Gromacs has been successfully ported to SYCL to date. In this paper, we compare the performance of GROMACS compiled using the SYCL and CUDA frameworks for a variety of standard GROMACS benchmarks. In addition, we compare its performance across three different Nvidia GPU chipsets, P100, V100, and A100.
Read more6/18/2024