Unified Uncertainties: Combining Input, Data and Model Uncertainty into a Single Formulation
2406.18787
0
0

Abstract
Modelling uncertainty in Machine Learning models is essential for achieving safe and reliable predictions. Most research on uncertainty focuses on output uncertainty (predictions), but minimal attention is paid to uncertainty at inputs. We propose a method for propagating uncertainty in the inputs through a Neural Network that is simultaneously able to estimate input, data, and model uncertainty. Our results show that this propagation of input uncertainty results in a more stable decision boundary even under large amounts of input noise than comparatively simple Monte Carlo sampling. Additionally, we discuss and demonstrate that input uncertainty, when propagated through the model, results in model uncertainty at the outputs. The explicit incorporation of input uncertainty may be beneficial in situations where the amount of input uncertainty is known, though good datasets for this are still needed.
Create account to get full access
Overview
- This paper proposes a unified framework for quantifying uncertainty in machine learning models, including input, data, and model uncertainty.
- The authors argue that existing approaches often treat these different sources of uncertainty in isolation, leading to incomplete or inaccurate assessments.
- The proposed method aims to combine these various forms of uncertainty into a single formulation, providing a more comprehensive and accurate way to characterize model uncertainty.
Plain English Explanation
The paper focuses on the challenge of quantifying uncertainty in machine learning models. Uncertainty can arise from several sources, such as the input data, the inherent variability in the training data, and the limitations of the model itself.
Existing approaches often treat these different types of uncertainty in isolation, which can lead to an incomplete or inaccurate understanding of the overall uncertainty in the model's predictions. The authors propose a unified framework that combines input, data, and model uncertainty into a single formulation. This allows for a more comprehensive and accurate characterization of the uncertainty in the model's outputs, which can be important for applications where reliable uncertainty quantification is critical, such as medicine or autonomous systems.
Technical Explanation
The paper presents a unified framework for quantifying uncertainty in machine learning models, which combines input uncertainty, data uncertainty, and model uncertainty into a single formulation. The authors argue that existing approaches often treat these different sources of uncertainty in isolation, leading to incomplete or inaccurate assessments of the overall model uncertainty.
The proposed method builds upon the concept of input uncertainty, where the input features are modeled as random variables with associated probability distributions. This input uncertainty is then propagated through the model to quantify the resulting uncertainty in the output predictions. The authors further incorporate data uncertainty, which captures the inherent variability and noise in the training data, and model uncertainty, which accounts for the limitations and imperfections of the model itself.
By unifying these different sources of uncertainty, the authors' approach provides a more comprehensive and accurate characterization of the overall uncertainty in the model's outputs. This is achieved by leveraging Bayesian inference techniques and stochastic optimization methods to jointly estimate the input, data, and model uncertainties.
The paper presents theoretical analysis and experimental results on various benchmark datasets, demonstrating the advantages of the unified uncertainty framework compared to traditional approaches that treat these uncertainties in isolation.
Critical Analysis
The proposed unified uncertainty framework represents a significant contribution to the field of uncertainty quantification in machine learning. The authors' key insight of combining different sources of uncertainty into a single formulation is a valuable step towards more accurate and reliable uncertainty assessment.
One potential limitation of the approach is the increased computational complexity compared to simpler uncertainty quantification methods. The authors acknowledge this challenge and suggest potential strategies for improving the efficiency of their approach, such as the use of approximate inference techniques.
Additionally, the paper does not provide a comprehensive discussion of the potential limitations or caveats of the unified uncertainty framework. For example, the authors could have addressed the sensitivity of the method to the choice of prior distributions or the potential impact of model misspecification on the accuracy of the uncertainty estimates.
Further research in this area could explore the practical implications of the unified uncertainty framework, particularly in high-stakes applications where reliable uncertainty quantification is critical, such as medical diagnosis or autonomous decision-making. Empirical studies in these domains could provide valuable insights into the real-world performance and limitations of the proposed approach.
Conclusion
This paper presents a unified framework for quantifying uncertainty in machine learning models, which combines input, data, and model uncertainty into a single formulation. The authors argue that this approach provides a more comprehensive and accurate characterization of the overall uncertainty in model predictions, which can be crucial for applications where reliable uncertainty quantification is essential.
The technical details of the proposed method, along with the theoretical analysis and experimental results, demonstrate the potential benefits of this unified uncertainty framework. While the approach may face computational challenges, the authors' work represents a significant step forward in the field of uncertainty quantification in machine learning. Further research and practical applications of this framework could lead to important advancements in the development of more trustworthy and robust AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Uncertainty Quantification for Deep Learning
Peter Jan van Leeuwen, J. Christine Chiu, C. Kevin Yang
0
0
A complete and statistically consistent uncertainty quantification for deep learning is provided, including the sources of uncertainty arising from (1) the new input data, (2) the training and testing data (3) the weight vectors of the neural network, and (4) the neural network because it is not a perfect predictor. Using Bayes Theorem and conditional probability densities, we demonstrate how each uncertainty source can be systematically quantified. We also introduce a fast and practical way to incorporate and combine all sources of errors for the first time. For illustration, the new method is applied to quantify errors in cloud autoconversion rates, predicted from an artificial neural network that was trained by aircraft cloud probe measurements in the Azores and the stochastic collection equation formulated as a two-moment bin model. For this specific example, the output uncertainty arising from uncertainty in the training and testing data is dominant, followed by uncertainty in the input data, in the trained neural network, and uncertainty in the weights. We discuss the usefulness of the methodology for machine learning practice, and how, through inclusion of uncertainty in the training data, the new methodology is less sensitive to input data that falls outside of the training data set.
6/3/2024
💬
Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling
Bairu Hou, Yujian Liu, Kaizhi Qian, Jacob Andreas, Shiyu Chang, Yang Zhang
0
0
Uncertainty decomposition refers to the task of decomposing the total uncertainty of a predictive model into aleatoric (data) uncertainty, resulting from inherent randomness in the data-generating process, and epistemic (model) uncertainty, resulting from missing information in the model's training data. In large language models (LLMs) specifically, identifying sources of uncertainty is an important step toward improving reliability, trustworthiness, and interpretability, but remains an important open research question. In this paper, we introduce an uncertainty decomposition framework for LLMs, called input clarification ensembling, which can be applied to any pre-trained LLM. Our approach generates a set of clarifications for the input, feeds them into an LLM, and ensembles the corresponding predictions. We show that, when aleatoric uncertainty arises from ambiguity or under-specification in LLM inputs, this approach makes it possible to factor an (unclarified) LLM's predictions into separate aleatoric and epistemic terms, using a decomposition similar to the one employed by Bayesian neural networks. Empirical evaluations demonstrate that input clarification ensembling provides accurate and reliable uncertainty quantification on several language processing tasks. Code and data are available at https://github.com/UCSB-NLP-Chang/llm_uncertainty.
6/12/2024
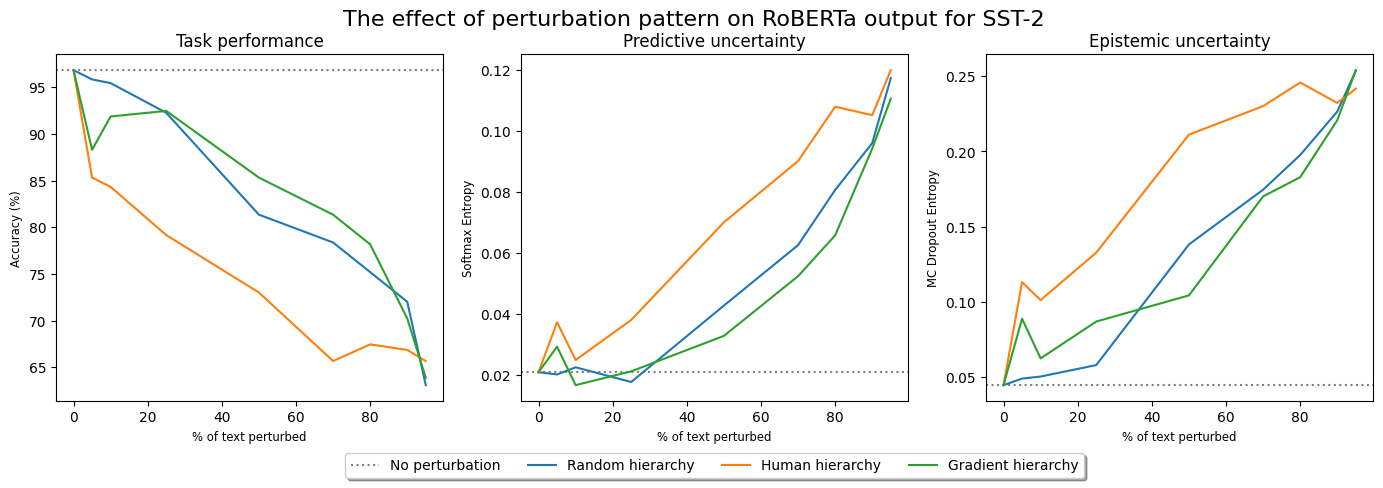
Investigating the Impact of Model Instability on Explanations and Uncertainty
Sara Vera Marjanovi'c, Isabelle Augenstein, Christina Lioma
0
0
Explainable AI methods facilitate the understanding of model behaviour, yet, small, imperceptible perturbations to inputs can vastly distort explanations. As these explanations are typically evaluated holistically, before model deployment, it is difficult to assess when a particular explanation is trustworthy. Some studies have tried to create confidence estimators for explanations, but none have investigated an existing link between uncertainty and explanation quality. We artificially simulate epistemic uncertainty in text input by introducing noise at inference time. In this large-scale empirical study, we insert different levels of noise perturbations and measure the effect on the output of pre-trained language models and different uncertainty metrics. Realistic perturbations have minimal effect on performance and explanations, yet masking has a drastic effect. We find that high uncertainty doesn't necessarily imply low explanation plausibility; the correlation between the two metrics can be moderately positive when noise is exposed during the training process. This suggests that noise-augmented models may be better at identifying salient tokens when uncertain. Furthermore, when predictive and epistemic uncertainty measures are over-confident, the robustness of a saliency map to perturbation can indicate model stability issues. Integrated Gradients shows the overall greatest robustness to perturbation, while still showing model-specific patterns in performance; however, this phenomenon is limited to smaller Transformer-based language models.
6/5/2024

Analytical results for uncertainty propagation through trained machine learning regression models
Andrew Thompson
0
0
Machine learning (ML) models are increasingly being used in metrology applications. However, for ML models to be credible in a metrology context they should be accompanied by principled uncertainty quantification. This paper addresses the challenge of uncertainty propagation through trained/fixed machine learning (ML) regression models. Analytical expressions for the mean and variance of the model output are obtained/presented for certain input data distributions and for a variety of ML models. Our results cover several popular ML models including linear regression, penalised linear regression, kernel ridge regression, Gaussian Processes (GPs), support vector machines (SVMs) and relevance vector machines (RVMs). We present numerical experiments in which we validate our methods and compare them with a Monte Carlo approach from a computational efficiency point of view. We also illustrate our methods in the context of a metrology application, namely modelling the state-of-health of lithium-ion cells based upon Electrical Impedance Spectroscopy (EIS) data
5/9/2024