Investigating the Impact of Model Instability on Explanations and Uncertainty

0
Sign in to get full access
Overview
- This paper investigates how model instability can impact the trustworthiness and reliability of model explanations and uncertainty estimates.
- The researchers explore the relationship between model instability, explanation quality, and uncertainty quantification using several benchmark machine learning models and datasets.
- The findings suggest that model instability can significantly degrade the meaningfulness and consistency of explanations, as well as the accuracy of uncertainty estimates.
Plain English Explanation
Machine learning models are increasingly being used to make important decisions, from medical diagnoses to financial predictions. As a result, it's crucial that these models are not only accurate, but also trustworthy and transparent. One way to improve trust in these models is through the use of explanations and uncertainty estimates.
Explanations help users understand how a model arrived at a particular prediction, while uncertainty estimates quantify the model's confidence in its output. However, this paper shows that model instability - the tendency for a model's predictions to fluctuate even with small changes to the input - can undermine the reliability and meaningfulness of these explanations and uncertainty estimates.
For example, if a model's explanation for a prediction changes dramatically when a single pixel in the input image is altered, it's hard to trust that the explanation is truly capturing the model's decision-making process. Similarly, if a model's uncertainty estimate varies widely depending on how the input is slightly perturbed, it's difficult to know how much confidence to place in the model's output.
The researchers demonstrate these issues using a variety of machine learning models and datasets, highlighting the need for more robust and stable model architectures and training procedures to ensure the trustworthiness and reliability of AI systems.
Technical Explanation
The paper begins by reviewing the existing literature on the importance of assessing the trustworthiness of model explanations and uncertainty estimates. The researchers then introduce their experimental setup, which involves training several standard machine learning models (including logistic regression, random forest, and deep neural networks) on benchmark datasets and evaluating the impact of model instability on the quality and consistency of the explanations and uncertainty estimates produced by these models.
To measure model instability, the researchers use a technique called Local Intrinsic Dimensionality (LID), which quantifies how sensitive a model's predictions are to small changes in the input. They then analyze the relationship between LID and the stability and reliability of the model's explanations and uncertainty estimates.
The results show that as model instability increases, the explanations produced by the models become less consistent and meaningful, and the uncertainty estimates become less accurate. For example, the researchers find that when a model exhibits high instability, its explanations can change dramatically even with minor perturbations to the input, making it difficult to trust the explanations. Similarly, the model's uncertainty estimates are more sensitive to input changes, reducing their reliability.
The paper also discusses potential mitigation strategies, such as designing more robust model architectures and training procedures, as well as developing new techniques for explaining uncertainty-aware models.
Critical Analysis
The paper makes a compelling case for the importance of considering model instability when evaluating the trustworthiness and reliability of machine learning models, particularly in high-stakes applications. The experimental results are thorough and well-designed, providing a comprehensive analysis of the impact of instability on explanations and uncertainty estimates across a range of model types and datasets.
One potential limitation of the research is that it focuses primarily on the stability of individual model predictions, rather than the overall consistency of a model's behavior across a larger set of inputs. In real-world applications, users may be more interested in the model's global behavior and decision-making patterns, which could be less affected by local instabilities.
Additionally, while the paper discusses potential mitigation strategies, it does not provide a detailed roadmap for how to develop more stable and trustworthy models. Further research may be needed to identify the specific architectural and training techniques that can best address the issues of model instability and its impact on explanations and uncertainty.
Overall, this paper makes an important contribution to the growing body of work on the trustworthiness and interpretability of machine learning models. By highlighting the critical role of model instability, it underscores the need for more rigorous and comprehensive approaches to model evaluation and validation.
Conclusion
This paper demonstrates that model instability can significantly undermine the reliability and meaningfulness of model explanations and uncertainty estimates, which are crucial for building trust in AI systems. The findings suggest that more robust and stable model architectures and training procedures are needed to ensure the trustworthiness and transparency of machine learning models, particularly in high-stakes applications. The researchers' insights highlight the importance of considering the broader implications of model behavior, beyond just accuracy metrics, when developing and deploying AI-powered decision support systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Investigating the Impact of Model Instability on Explanations and Uncertainty
Sara Vera Marjanovi'c, Isabelle Augenstein, Christina Lioma
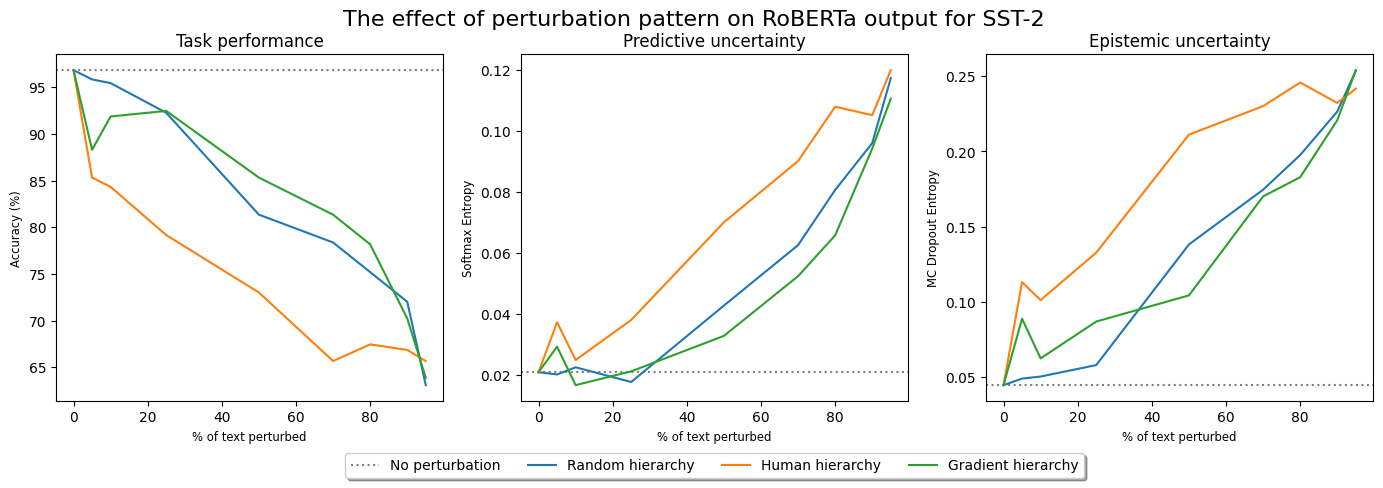
Explainable AI methods facilitate the understanding of model behaviour, yet, small, imperceptible perturbations to inputs can vastly distort explanations. As these explanations are typically evaluated holistically, before model deployment, it is difficult to assess when a particular explanation is trustworthy. Some studies have tried to create confidence estimators for explanations, but none have investigated an existing link between uncertainty and explanation quality. We artificially simulate epistemic uncertainty in text input by introducing noise at inference time. In this large-scale empirical study, we insert different levels of noise perturbations and measure the effect on the output of pre-trained language models and different uncertainty metrics. Realistic perturbations have minimal effect on performance and explanations, yet masking has a drastic effect. We find that high uncertainty doesn't necessarily imply low explanation plausibility; the correlation between the two metrics can be moderately positive when noise is exposed during the training process. This suggests that noise-augmented models may be better at identifying salient tokens when uncertain. Furthermore, when predictive and epistemic uncertainty measures are over-confident, the robustness of a saliency map to perturbation can indicate model stability issues. Integrated Gradients shows the overall greatest robustness to perturbation, while still showing model-specific patterns in performance; however, this phenomenon is limited to smaller Transformer-based language models.
Read more6/5/2024
0
Identifying Drivers of Predictive Aleatoric Uncertainty
Pascal Iversen, Simon Witzke, Katharina Baum, Bernhard Y. Renard
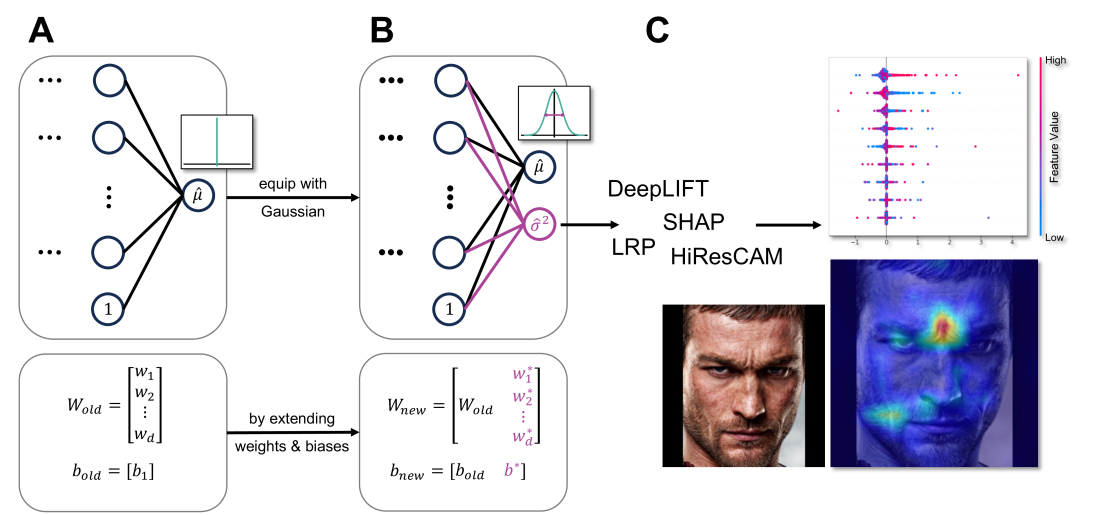
Explainability and uncertainty quantification are two pillars of trustable artificial intelligence. However, the reasoning behind uncertainty estimates is generally left unexplained. Identifying the drivers of uncertainty complements explanations of point predictions in recognizing model limitations and enhances trust in decisions and their communication. So far, explanations of uncertainties have been rarely studied. The few exceptions rely on Bayesian neural networks or technically intricate approaches, such as auxiliary generative models, thereby hindering their broad adoption. We present a simple approach to explain predictive aleatoric uncertainties. We estimate uncertainty as predictive variance by adapting a neural network with a Gaussian output distribution. Subsequently, we apply out-of-the-box explainers to the model's variance output. This approach can explain uncertainty influences more reliably than literature baselines, which we evaluate in a synthetic setting with a known data-generating process. We further adapt multiple metrics from conventional XAI research to uncertainty explanations. We quantify our findings with a nuanced benchmark analysis that includes real-world datasets. Finally, we apply our approach to an age regression model and discover reasonable sources of uncertainty. Overall, we explain uncertainty estimates with little modifications to the model architecture and demonstrate that our approach competes effectively with more intricate methods.
Read more5/31/2024

0
Unified Explanations in Machine Learning Models: A Perturbation Approach
Jacob Dineen, Don Kridel, Daniel Dolk, David Castillo
A high-velocity paradigm shift towards Explainable Artificial Intelligence (XAI) has emerged in recent years. Highly complex Machine Learning (ML) models have flourished in many tasks of intelligence, and the questions have started to shift away from traditional metrics of validity towards something deeper: What is this model telling me about my data, and how is it arriving at these conclusions? Inconsistencies between XAI and modeling techniques can have the undesirable effect of casting doubt upon the efficacy of these explainability approaches. To address these problems, we propose a systematic, perturbation-based analysis against a popular, model-agnostic method in XAI, SHapley Additive exPlanations (Shap). We devise algorithms to generate relative feature importance in settings of dynamic inference amongst a suite of popular machine learning and deep learning methods, and metrics that allow us to quantify how well explanations generated under the static case hold. We propose a taxonomy for feature importance methodology, measure alignment, and observe quantifiable similarity amongst explanation models across several datasets.
Read more5/31/2024
0
VOICE: Variance of Induced Contrastive Explanations to quantify Uncertainty in Neural Network Interpretability
Mohit Prabhushankar, Ghassan AlRegib
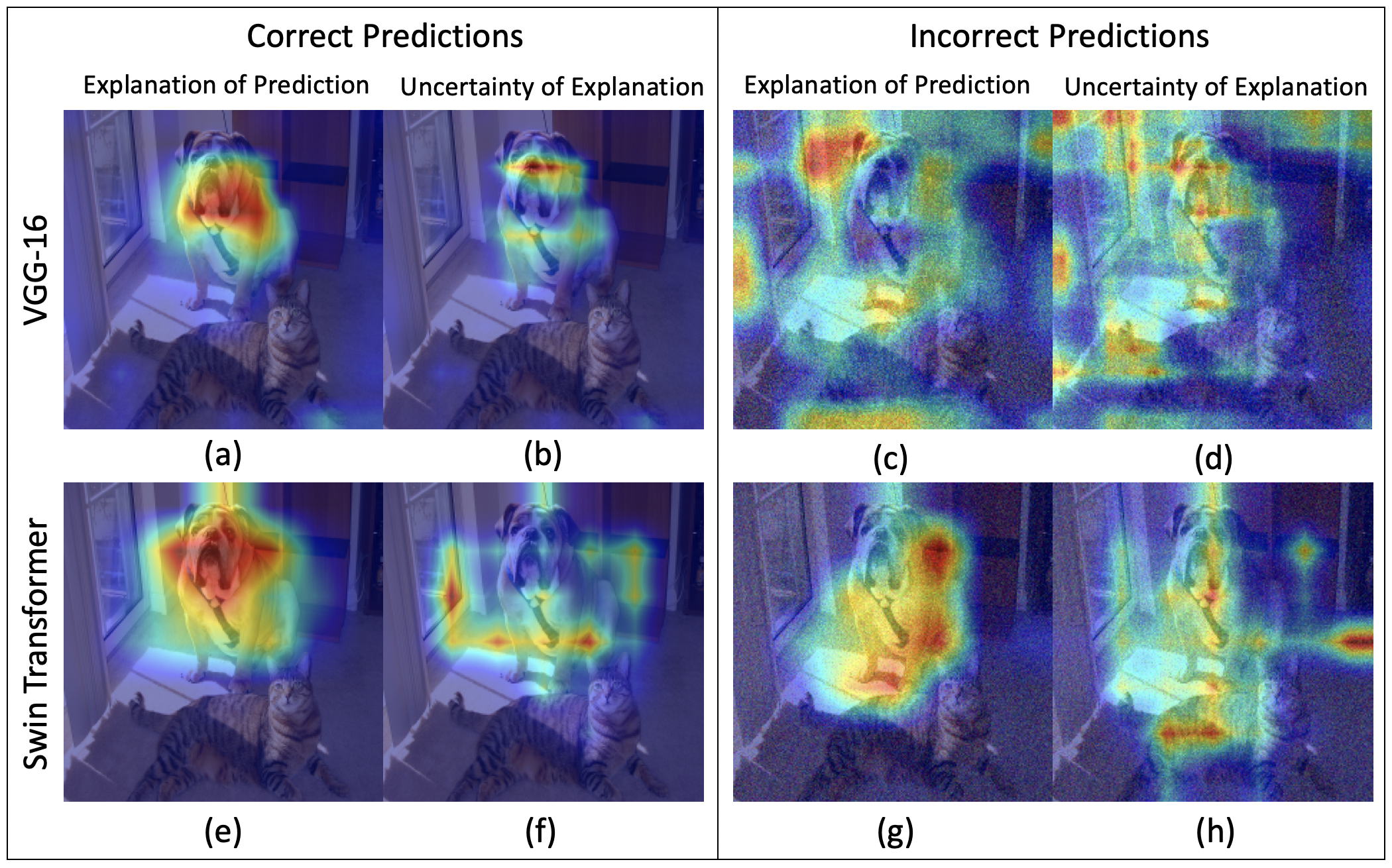
In this paper, we visualize and quantify the predictive uncertainty of gradient-based post hoc visual explanations for neural networks. Predictive uncertainty refers to the variability in the network predictions under perturbations to the input. Visual post hoc explainability techniques highlight features within an image to justify a network's prediction. We theoretically show that existing evaluation strategies of visual explanatory techniques partially reduce the predictive uncertainty of neural networks. This analysis allows us to construct a plug in approach to visualize and quantify the remaining predictive uncertainty of any gradient-based explanatory technique. We show that every image, network, prediction, and explanatory technique has a unique uncertainty. The proposed uncertainty visualization and quantification yields two key observations. Firstly, oftentimes under incorrect predictions, explanatory techniques are uncertain about the same features that they are attributing the predictions to, thereby reducing the trustworthiness of the explanation. Secondly, objective metrics of an explanation's uncertainty, empirically behave similarly to epistemic uncertainty. We support these observations on two datasets, four explanatory techniques, and six neural network architectures. The code is available at https://github.com/olivesgatech/VOICE-Uncertainty.
Read more6/4/2024