UniFL: Improve Stable Diffusion via Unified Feedback Learning
2404.05595
0
0

Abstract
Diffusion models have revolutionized the field of image generation, leading to the proliferation of high-quality models and diverse downstream applications. However, despite these significant advancements, the current competitive solutions still suffer from several limitations, including inferior visual quality, a lack of aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present UniFL, a unified framework that leverages feedback learning to enhance diffusion models comprehensively. UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL. Notably, UniFL incorporates three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which optimizes inference speed. In-depth experiments and extensive user studies validate the superior performance of our proposed method in enhancing both the quality of generated models and their acceleration. For instance, UniFL surpasses ImageReward by 17% user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57% and 20% in 4-step inference. Moreover, we have verified the efficacy of our approach in downstream tasks, including Lora, ControlNet, and AnimateDiff.
Create account to get full access
Overview
- This paper introduces UniFL, a unified feedback learning framework that can improve the performance of text-to-image diffusion models like Stable Diffusion.
- UniFL leverages multiple forms of feedback, including perceptual, content, and style, to fine-tune diffusion models and generate higher-quality images.
- The authors demonstrate that UniFL can outperform existing fine-tuning methods for text-to-image generation while maintaining stable and consistent performance.
Plain English Explanation
The paper proposes a new technique called UniFL (Unified Feedback Learning) that can help improve the performance of text-to-image diffusion models like Stable Diffusion. Diffusion models are a type of machine learning model that can generate images from text descriptions.
UniFL works by providing the diffusion model with different types of feedback during the training process. This feedback can come from evaluating the perceptual quality of the generated images, their content accuracy, and their stylistic properties. By incorporating this multi-faceted feedback, the model can learn to generate images that better match the desired text description.
The authors show that using UniFL to fine-tune a pre-trained diffusion model results in higher-quality image generation compared to other fine-tuning methods. This means the images produced by the model are more faithful to the input text and have a more consistent, coherent style. The UniFL approach helps the model better understand the relationships between text, content, and style, leading to improved text-to-image generation capabilities.
Technical Explanation
The paper introduces a unified feedback learning framework called UniFL that can be used to fine-tune text-to-image diffusion models like Stable Diffusion. UniFL leverages multiple forms of feedback, including perceptual, content, and style feedback, to guide the fine-tuning process and improve the quality of generated images.
The perceptual feedback module evaluates the overall visual quality of the generated images using a pre-trained image classification model. The content feedback module assesses how well the generated images match the input text description using a text-image matching model. And the style feedback module measures the stylistic properties of the images, such as color, texture, and composition, to ensure consistency with the desired aesthetic.
By incorporating these diverse feedback signals, UniFL can fine-tune the diffusion model to generate images that are not only visually appealing but also semantically accurate and stylistically coherent. The authors demonstrate that this unified feedback approach outperforms existing fine-tuning methods for text-to-image generation, as measured by both human evaluation and automated metrics.
The UniFL framework is also extensible, allowing for the incorporation of additional feedback signals or the use of different feedback models depending on the specific application or dataset. This flexibility makes UniFL a powerful tool for improving the performance of text-to-image diffusion models in a wide range of scenarios.
Critical Analysis
The UniFL framework proposed in this paper represents a significant advancement in text-to-image generation using diffusion models. By leveraging multiple feedback signals, the authors have shown that it is possible to fine-tune these models to generate higher-quality images that better match the input text descriptions.
One potential limitation of the UniFL approach is its reliance on pre-trained models for the various feedback modules. The performance of these modules, and consequently the overall UniFL framework, may be sensitive to the quality and domain-specificity of the pre-trained models used. The authors acknowledge this and suggest that further research is needed to explore more robust and generalizable feedback mechanisms.
Additionally, the paper does not provide a comprehensive analysis of the computational and memory requirements of the UniFL framework, which could be an important consideration for real-world deployment, especially on resource-constrained devices. Further research into the efficiency and scalability of UniFL would be valuable.
Despite these potential limitations, the UniFL framework represents a significant step forward in the field of text-to-image generation. By leveraging multiple forms of feedback, the authors have shown that it is possible to fine-tune diffusion models to generate higher-quality, more semantically accurate, and more stylistically consistent images. This work has important implications for a wide range of applications, from creative content generation to interactive design tools.
Conclusion
The UniFL framework introduced in this paper offers a novel approach to improving the performance of text-to-image diffusion models like Stable Diffusion. By incorporating multiple forms of feedback, including perceptual, content, and style feedback, UniFL can fine-tune these models to generate images that are more visually appealing, semantically accurate, and stylistically coherent.
The authors have demonstrated that the UniFL approach outperforms existing fine-tuning methods, producing higher-quality images that better match the input text descriptions. This work has important implications for a wide range of applications, from creative content generation to interactive design tools, and represents a significant advancement in the field of text-to-image generation.
While the UniFL framework has some potential limitations, such as its reliance on pre-trained feedback models, the authors have laid the groundwork for further research and development in this area. As the field of diffusion models continues to evolve, techniques like UniFL will play an increasingly important role in pushing the boundaries of what is possible in text-to-image generation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
The Missing U for Efficient Diffusion Models
Sergio Calvo-Ordonez, Chun-Wun Cheng, Jiahao Huang, Lipei Zhang, Guang Yang, Carola-Bibiane Schonlieb, Angelica I Aviles-Rivero
0
0
Diffusion Probabilistic Models stand as a critical tool in generative modelling, enabling the generation of complex data distributions. This family of generative models yields record-breaking performance in tasks such as image synthesis, video generation, and molecule design. Despite their capabilities, their efficiency, especially in the reverse process, remains a challenge due to slow convergence rates and high computational costs. In this paper, we introduce an approach that leverages continuous dynamical systems to design a novel denoising network for diffusion models that is more parameter-efficient, exhibits faster convergence, and demonstrates increased noise robustness. Experimenting with Denoising Diffusion Probabilistic Models (DDPMs), our framework operates with approximately a quarter of the parameters, and $sim$ 30% of the Floating Point Operations (FLOPs) compared to standard U-Nets in DDPMs. Furthermore, our model is notably faster in inference than the baseline when measured in fair and equal conditions. We also provide a mathematical intuition as to why our proposed reverse process is faster as well as a mathematical discussion of the empirical tradeoffs in the denoising downstream task. Finally, we argue that our method is compatible with existing performance enhancement techniques, enabling further improvements in efficiency, quality, and speed.
4/8/2024
👀
Discffusion: Discriminative Diffusion Models as Few-shot Vision and Language Learners
Xuehai He, Weixi Feng, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Pradyumna Narayana, Sugato Basu, William Yang Wang, Xin Eric Wang
0
0
Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach mainly uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via efficient attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
4/26/2024
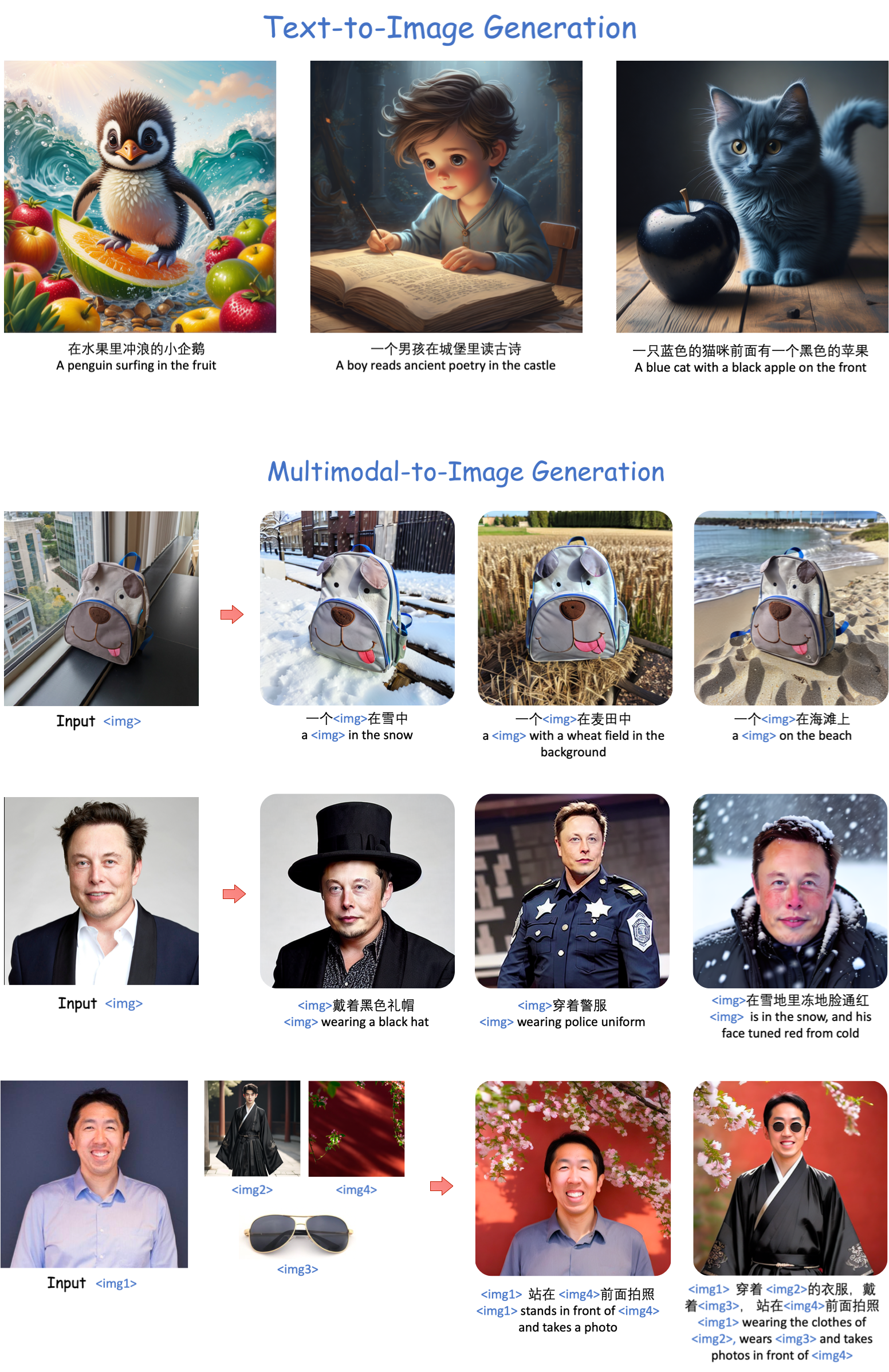
UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion
Wei Li, Xue Xu, Jiachen Liu, Xinyan Xiao
0
0
Existing text-to-image diffusion models primarily generate images from text prompts. However, the inherent conciseness of textual descriptions poses challenges in faithfully synthesizing images with intricate details, such as specific entities or scenes. This paper presents UNIMO-G, a simple multimodal conditional diffusion framework that operates on multimodal prompts with interleaved textual and visual inputs, which demonstrates a unified ability for both text-driven and subject-driven image generation. UNIMO-G comprises two core components: a Multimodal Large Language Model (MLLM) for encoding multimodal prompts, and a conditional denoising diffusion network for generating images based on the encoded multimodal input. We leverage a two-stage training strategy to effectively train the framework: firstly pre-training on large-scale text-image pairs to develop conditional image generation capabilities, and then instruction tuning with multimodal prompts to achieve unified image generation proficiency. A well-designed data processing pipeline involving language grounding and image segmentation is employed to construct multi-modal prompts. UNIMO-G excels in both text-to-image generation and zero-shot subject-driven synthesis, and is notably effective in generating high-fidelity images from complex multimodal prompts involving multiple image entities.
6/7/2024
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation
Xiang Wang, Shiwei Zhang, Changxin Gao, Jiayu Wang, Xiaoqiang Zhou, Yingya Zhang, Luxin Yan, Nong Sang
0
0
Recent diffusion-based human image animation techniques have demonstrated impressive success in synthesizing videos that faithfully follow a given reference identity and a sequence of desired movement poses. Despite this, there are still two limitations: i) an extra reference model is required to align the identity image with the main video branch, which significantly increases the optimization burden and model parameters; ii) the generated video is usually short in time (e.g., 24 frames), hampering practical applications. To address these shortcomings, we present a UniAnimate framework to enable efficient and long-term human video generation. First, to reduce the optimization difficulty and ensure temporal coherence, we map the reference image along with the posture guidance and noise video into a common feature space by incorporating a unified video diffusion model. Second, we propose a unified noise input that supports random noised input as well as first frame conditioned input, which enhances the ability to generate long-term video. Finally, to further efficiently handle long sequences, we explore an alternative temporal modeling architecture based on state space model to replace the original computation-consuming temporal Transformer. Extensive experimental results indicate that UniAnimate achieves superior synthesis results over existing state-of-the-art counterparts in both quantitative and qualitative evaluations. Notably, UniAnimate can even generate highly consistent one-minute videos by iteratively employing the first frame conditioning strategy. Code and models will be publicly available. Project page: https://unianimate.github.io/.
6/4/2024