UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion
2401.13388
0
0
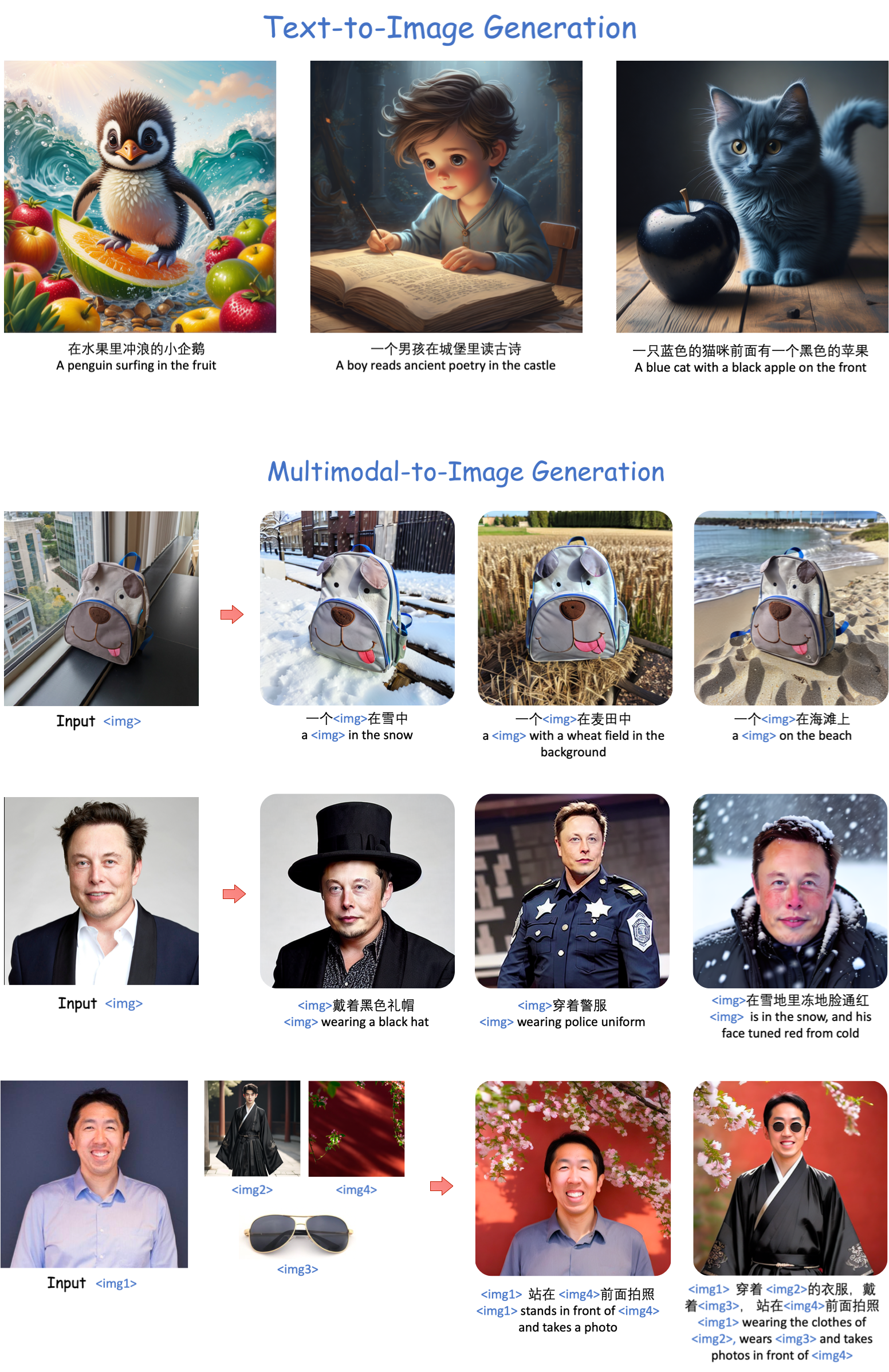
Abstract
Existing text-to-image diffusion models primarily generate images from text prompts. However, the inherent conciseness of textual descriptions poses challenges in faithfully synthesizing images with intricate details, such as specific entities or scenes. This paper presents UNIMO-G, a simple multimodal conditional diffusion framework that operates on multimodal prompts with interleaved textual and visual inputs, which demonstrates a unified ability for both text-driven and subject-driven image generation. UNIMO-G comprises two core components: a Multimodal Large Language Model (MLLM) for encoding multimodal prompts, and a conditional denoising diffusion network for generating images based on the encoded multimodal input. We leverage a two-stage training strategy to effectively train the framework: firstly pre-training on large-scale text-image pairs to develop conditional image generation capabilities, and then instruction tuning with multimodal prompts to achieve unified image generation proficiency. A well-designed data processing pipeline involving language grounding and image segmentation is employed to construct multi-modal prompts. UNIMO-G excels in both text-to-image generation and zero-shot subject-driven synthesis, and is notably effective in generating high-fidelity images from complex multimodal prompts involving multiple image entities.
Create account to get full access
Overview
- This paper introduces a new image generation model called UNIMO-G (Unified Image Generation through Multimodal Conditional Diffusion)
- UNIMO-G can generate images conditioned on text descriptions, similar to Contextualized Diffusion Models for Text-Guided Image Generation and Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Beyond
- The key innovation is that UNIMO-G can also generate images conditioned on other modalities like images, video, and language models
- This allows UNIMO-G to leverage information across multiple modalities to generate more coherent and realistic images
Plain English Explanation
UNIMO-G is a new type of AI model that can create images based on text descriptions, similar to other recent text-to-image models. But what makes UNIMO-G special is that it can also use other types of information, like images, videos, and language models, to help generate the images.
By combining these different sources of data, UNIMO-G can create images that are more realistic and make more sense in the context of the input. For example, if you give UNIMO-G a text description of a scene, it can also look at related images or videos to better understand the details and generate a more coherent final image.
This multimodal approach allows UNIMO-G to be more flexible and powerful than models that can only work with text. It opens up new possibilities for applications like generating personalized images, interactive storytelling, and more.
Technical Explanation
The core innovation of UNIMO-G is its ability to leverage multiple modalities, including text, images, video, and language models, to generate images. This is achieved through a text-to-image pre-training stage, where the model learns to generate images conditioned on text descriptions.
During this pre-training, the model also learns to use auxiliary modalities like images and videos to better understand the text and generate more realistic outputs. This allows UNIMO-G to capture cross-modal relationships and utilize complementary information across different data types.
After pre-training, UNIMO-G can be fine-tuned on specific tasks or datasets, allowing it to adapt to various image generation use cases that go beyond just text-to-image. The multimodal nature of the model enables it to generate images that are more coherent and aligned with the given input, whether that's a text description, an existing image, or a combination of modalities.
Critical Analysis
The authors acknowledge that UNIMO-G, like other diffusion-based image generation models, can struggle with issues like faithfulness to the input, visual quality, and efficiently generating high-resolution images. They suggest that further research is needed to address these limitations and improve the model's performance.
Additionally, the authors note that the multimodal nature of UNIMO-G adds complexity to the model, which could make it more computationally expensive and challenging to train and deploy. The tradeoffs between the model's increased capabilities and its increased complexity would need to be carefully evaluated for different applications.
It would also be important to further investigate the model's ability to generalize to diverse datasets and scenarios, as well as its robustness to distribution shift or adversarial attacks. Expanding the range of modalities UNIMO-G can work with, such as 3D data or audio, could also be an interesting area for future research.
Conclusion
The UNIMO-G model presents a promising approach to unified image generation by leveraging multiple modalities, including text, images, video, and language models. This multimodal approach allows the model to generate more coherent and realistic images by drawing upon complementary information across different data types.
While the model has some limitations that require further research, the ability to generate images conditioned on diverse inputs opens up new possibilities for applications in areas like personalized content creation, interactive storytelling, and assistive technologies. As the field of multimodal AI continues to evolve, models like UNIMO-G could play an important role in advancing the state of the art in image generation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!MUMU: Bootstrapping Multimodal Image Generation from Text-to-Image Data
William Berman, Alexander Peysakhovich
0
0
We train a model to generate images from multimodal prompts of interleaved text and images such as a man and his dog in an animated style. We bootstrap a multimodal dataset by extracting semantically meaningful image crops corresponding to words in the image captions of synthetically generated and publicly available text-image data. Our model, MUMU, is composed of a vision-language model encoder with a diffusion decoder and is trained on a single 8xH100 GPU node. Despite being only trained on crops from the same image, MUMU learns to compose inputs from different images into a coherent output. For example, an input of a realistic person and a cartoon will output the same person in the cartoon style, and an input of a standing subject and a scooter will output the subject riding the scooter. As a result, our model generalizes to tasks such as style transfer and character consistency. Our results show the promise of using multimodal models as general purpose controllers for image generation.
6/28/2024

Unified Text-to-Image Generation and Retrieval
Leigang Qu, Haochuan Li, Tan Wang, Wenjie Wang, Yongqi Li, Liqiang Nie, Tat-Seng Chua
0
0
How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity. By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs). Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query. Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.
6/11/2024

Contextualized Diffusion Models for Text-Guided Image and Video Generation
Ling Yang, Zhilong Zhang, Zhaochen Yu, Jingwei Liu, Minkai Xu, Stefano Ermon, Bin Cui
0
0
Conditional diffusion models have exhibited superior performance in high-fidelity text-guided visual generation and editing. Nevertheless, prevailing text-guided visual diffusion models primarily focus on incorporating text-visual relationships exclusively into the reverse process, often disregarding their relevance in the forward process. This inconsistency between forward and reverse processes may limit the precise conveyance of textual semantics in visual synthesis results. To address this issue, we propose a novel and general contextualized diffusion model (ContextDiff) by incorporating the cross-modal context encompassing interactions and alignments between text condition and visual sample into forward and reverse processes. We propagate this context to all timesteps in the two processes to adapt their trajectories, thereby facilitating cross-modal conditional modeling. We generalize our contextualized diffusion to both DDPMs and DDIMs with theoretical derivations, and demonstrate the effectiveness of our model in evaluations with two challenging tasks: text-to-image generation, and text-to-video editing. In each task, our ContextDiff achieves new state-of-the-art performance, significantly enhancing the semantic alignment between text condition and generated samples, as evidenced by quantitative and qualitative evaluations. Our code is available at https://github.com/YangLing0818/ContextDiff
6/5/2024

Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui
0
0
Diffusion models have exhibit exceptional performance in text-to-image generation and editing. However, existing methods often face challenges when handling complex text prompts that involve multiple objects with multiple attributes and relationships. In this paper, we propose a brand new training-free text-to-image generation/editing framework, namely Recaption, Plan and Generate (RPG), harnessing the powerful chain-of-thought reasoning ability of multimodal LLMs to enhance the compositionality of text-to-image diffusion models. Our approach employs the MLLM as a global planner to decompose the process of generating complex images into multiple simpler generation tasks within subregions. We propose complementary regional diffusion to enable region-wise compositional generation. Furthermore, we integrate text-guided image generation and editing within the proposed RPG in a closed-loop fashion, thereby enhancing generalization ability. Extensive experiments demonstrate our RPG outperforms state-of-the-art text-to-image diffusion models, including DALL-E 3 and SDXL, particularly in multi-category object composition and text-image semantic alignment. Notably, our RPG framework exhibits wide compatibility with various MLLM architectures (e.g., MiniGPT-4) and diffusion backbones (e.g., ControlNet). Our code is available at: https://github.com/YangLing0818/RPG-DiffusionMaster
6/5/2024