Unifying Low Dimensional Observations in Deep Learning Through the Deep Linear Unconstrained Feature Model
2404.06106
0
0
Abstract
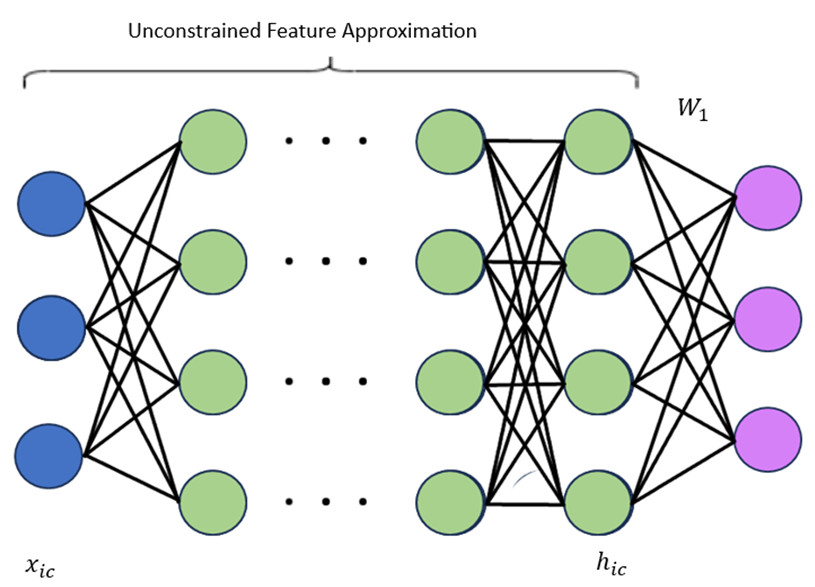
Modern deep neural networks have achieved high performance across various tasks. Recently, researchers have noted occurrences of low-dimensional structure in the weights, Hessian's, gradients, and feature vectors of these networks, spanning different datasets and architectures when trained to convergence. In this analysis, we theoretically demonstrate these observations arising, and show how they can be unified within a generalized unconstrained feature model that can be considered analytically. Specifically, we consider a previously described structure called Neural Collapse, and its multi-layer counterpart, Deep Neural Collapse, which emerges when the network approaches global optima. This phenomenon explains the other observed low-dimensional behaviours on a layer-wise level, such as the bulk and outlier structure seen in Hessian spectra, and the alignment of gradient descent with the outlier eigenspace of the Hessian. Empirical results in both the deep linear unconstrained feature model and its non-linear equivalent support these predicted observations.
Create account to get full access
Overview
- This paper proposes a new deep learning model called the Deep Linear Unconstrained Feature Model (DLUF) that can unify low-dimensional observations in complex deep learning tasks.
- The DLUF model aims to address issues of "dimensional collapse" and "heterogeneous features" that can arise in deep learning architectures.
- The authors demonstrate the DLUF model's effectiveness on several benchmark tasks and provide theoretical analysis to understand its behavior.
Plain English Explanation
The paper introduces a new deep learning model called the Deep Linear Unconstrained Feature Model (DLUF) that can help address some common challenges in deep learning. One challenge is "dimensional collapse," where the high-dimensional input data gets compressed into a low-dimensional representation, causing a loss of important information. Another challenge is "heterogeneous features," where the model has to deal with a mix of different types of input data, such as images, text, and numerical values.
The DLUF model is designed to overcome these issues by using a flexible, unconstrained architecture that can learn rich feature representations from low-dimensional observations. The authors show that the DLUF model performs well on several benchmark tasks compared to other deep learning approaches. They also provide a theoretical analysis to understand why the DLUF model is effective.
The key idea behind the DLUF model is to allow the deep learning architecture to learn the feature representations in an unconstrained way, without forcing the model to compress the data into a low-dimensional space. This helps preserve important information and allows the model to handle diverse types of input data more effectively.
Technical Explanation
The Deep Linear Unconstrained Feature (DLUF) model proposed in this paper aims to address the issues of "dimensional collapse" and "heterogeneous features" that can arise in deep learning architectures. Dimensional collapse occurs when high-dimensional input data gets compressed into a low-dimensional representation, leading to a loss of important information. "Heterogeneous features" refer to the challenge of dealing with a mix of different types of input data, such as images, text, and numerical values.
The DLUF model uses a flexible, unconstrained architecture that can learn rich feature representations from low-dimensional observations. The authors demonstrate the effectiveness of the DLUF model on several benchmark tasks and provide a theoretical analysis to understand its behavior.
The key aspects of the DLUF model include:
- Unconstrained Architecture: Unlike traditional deep learning models that often impose constraints on the feature representations, the DLUF model allows the architecture to learn the features in an unconstrained way, without forcing the data into a low-dimensional space.
- Handling Heterogeneous Features: The DLUF model can effectively handle a mix of different types of input data, such as images, text, and numerical values, by learning appropriate feature representations for each.
- Theoretical Analysis: The authors provide a theoretical analysis to understand the behavior of the DLUF model and its ability to learn rich feature representations from low-dimensional observations.
Critical Analysis
The paper presents a promising approach to addressing the challenges of dimensional collapse and heterogeneous features in deep learning. The authors provide a thorough theoretical analysis and demonstrate the DLUF model's effectiveness on several benchmark tasks.
However, the paper does not discuss potential limitations or areas for further research. For example, it would be interesting to understand how the DLUF model performs on more complex, real-world datasets with higher-dimensional inputs and a greater diversity of data types. Object dynamics modeling or understanding the underlying scaling laws of the DLUF model could also provide additional insights.
Additionally, the paper does not address potential issues related to the interpretability or robustness of the DLUF model, which are important considerations for real-world applications.
Overall, the DLUF model presents an intriguing approach to addressing some longstanding challenges in deep learning, but further research and evaluation are needed to fully assess its capabilities and limitations.
Conclusion
The Deep Linear Unconstrained Feature (DLUF) model proposed in this paper offers a promising solution to the problems of dimensional collapse and heterogeneous features in deep learning. By using a flexible, unconstrained architecture, the DLUF model can learn rich feature representations from low-dimensional observations, potentially overcoming the limitations of traditional deep learning approaches.
The authors' theoretical analysis and empirical results demonstrate the effectiveness of the DLUF model on several benchmark tasks. However, further research is needed to understand the model's performance on more complex, real-world datasets, as well as its interpretability and robustness.
If the DLUF model can be further developed and refined, it could have significant implications for a wide range of deep learning applications, from computer vision and natural language processing to healthcare and scientific research, where the ability to handle diverse data types and preserve important information is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Neural Collapse for Cross-entropy Class-Imbalanced Learning with Unconstrained ReLU Feature Model
Hien Dang, Tho Tran, Tan Nguyen, Nhat Ho
0
0
The current paradigm of training deep neural networks for classification tasks includes minimizing the empirical risk that pushes the training loss value towards zero, even after the training error has been vanished. In this terminal phase of training, it has been observed that the last-layer features collapse to their class-means and these class-means converge to the vertices of a simplex Equiangular Tight Frame (ETF). This phenomenon is termed as Neural Collapse (NC). To theoretically understand this phenomenon, recent works employ a simplified unconstrained feature model to prove that NC emerges at the global solutions of the training problem. However, when the training dataset is class-imbalanced, some NC properties will no longer be true. For example, the class-means geometry will skew away from the simplex ETF when the loss converges. In this paper, we generalize NC to imbalanced regime for cross-entropy loss under the unconstrained ReLU feature model. We prove that, while the within-class features collapse property still holds in this setting, the class-means will converge to a structure consisting of orthogonal vectors with different lengths. Furthermore, we find that the classifier weights are aligned to the scaled and centered class-means with scaling factors depend on the number of training samples of each class, which generalizes NC in the class-balanced setting. We empirically prove our results through experiments on practical architectures and dataset.
6/7/2024
🧠
Neural Collapse versus Low-rank Bias: Is Deep Neural Collapse Really Optimal?
Peter S'uken'ik, Marco Mondelli, Christoph Lampert
0
0
Deep neural networks (DNNs) exhibit a surprising structure in their final layer known as neural collapse (NC), and a growing body of works has currently investigated the propagation of neural collapse to earlier layers of DNNs -- a phenomenon called deep neural collapse (DNC). However, existing theoretical results are restricted to special cases: linear models, only two layers or binary classification. In contrast, we focus on non-linear models of arbitrary depth in multi-class classification and reveal a surprising qualitative shift. As soon as we go beyond two layers or two classes, DNC stops being optimal for the deep unconstrained features model (DUFM) -- the standard theoretical framework for the analysis of collapse. The main culprit is a low-rank bias of multi-layer regularization schemes: this bias leads to optimal solutions of even lower rank than the neural collapse. We support our theoretical findings with experiments on both DUFM and real data, which show the emergence of the low-rank structure in the solution found by gradient descent.
5/24/2024

Training Dynamics of Nonlinear Contrastive Learning Model in the High Dimensional Limit
Lineghuan Meng, Chuang Wang
0
0
This letter presents a high-dimensional analysis of the training dynamics for a single-layer nonlinear contrastive learning model. The empirical distribution of the model weights converges to a deterministic measure governed by a McKean-Vlasov nonlinear partial differential equation (PDE). Under L2 regularization, this PDE reduces to a closed set of low-dimensional ordinary differential equations (ODEs), reflecting the evolution of the model performance during the training process. We analyze the fixed point locations and their stability of the ODEs unveiling several interesting findings. First, only the hidden variable's second moment affects feature learnability at the state with uninformative initialization. Second, higher moments influence the probability of feature selection by controlling the attraction region, rather than affecting local stability. Finally, independent noises added in the data argumentation degrade performance but negatively correlated noise can reduces the variance of gradient estimation yielding better performance. Despite of the simplicity of the analyzed model, it exhibits a rich phenomena of training dynamics, paving a way to understand more complex mechanism behind practical large models.
6/12/2024

Measuring Feature Dependency of Neural Networks by Collapsing Feature Dimensions in the Data Manifold
Yinzhu Jin, Matthew B. Dwyer, P. Thomas Fletcher
0
0
This paper introduces a new technique to measure the feature dependency of neural network models. The motivation is to better understand a model by querying whether it is using information from human-understandable features, e.g., anatomical shape, volume, or image texture. Our method is based on the principle that if a model is dependent on a feature, then removal of that feature should significantly harm its performance. A targeted feature is removed by collapsing the dimension in the data distribution that corresponds to that feature. We perform this by moving data points along the feature dimension to a baseline feature value while staying on the data manifold, as estimated by a deep generative model. Then we observe how the model's performance changes on the modified test data set, with the target feature dimension removed. We test our method on deep neural network models trained on synthetic image data with known ground truth, an Alzheimer's disease prediction task using MRI and hippocampus segmentations from the OASIS-3 dataset, and a cell nuclei classification task using the Lizard dataset.
4/19/2024