Towards Understanding and Mitigating Dimensional Collapse in Heterogeneous Federated Learning
2210.00226
0
0
🤔
Abstract
Federated learning aims to train models collaboratively across different clients without the sharing of data for privacy considerations. However, one major challenge for this learning paradigm is the {em data heterogeneity} problem, which refers to the discrepancies between the local data distributions among various clients. To tackle this problem, we first study how data heterogeneity affects the representations of the globally aggregated models. Interestingly, we find that heterogeneous data results in the global model suffering from severe {em dimensional collapse}, in which representations tend to reside in a lower-dimensional space instead of the ambient space. Moreover, we observe a similar phenomenon on models locally trained on each client and deduce that the dimensional collapse on the global model is inherited from local models. In addition, we theoretically analyze the gradient flow dynamics to shed light on how data heterogeneity result in dimensional collapse for local models. To remedy this problem caused by the data heterogeneity, we propose {sc FedDecorr}, a novel method that can effectively mitigate dimensional collapse in federated learning. Specifically, {sc FedDecorr} applies a regularization term during local training that encourages different dimensions of representations to be uncorrelated. {sc FedDecorr}, which is implementation-friendly and computationally-efficient, yields consistent improvements over baselines on standard benchmark datasets. Code: https://github.com/bytedance/FedDecorr.
Create account to get full access
Overview
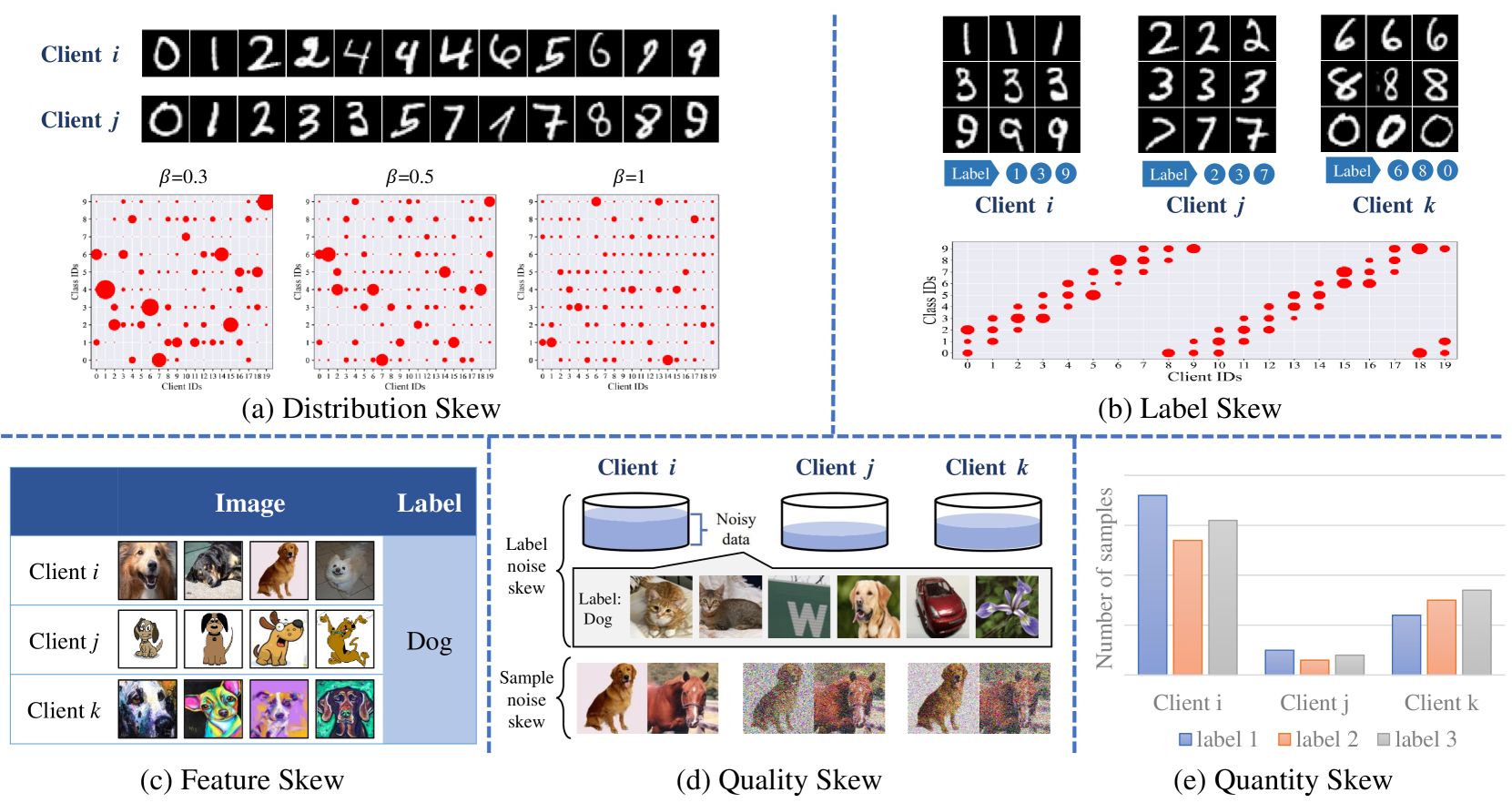
- Federated learning aims to train models collaboratively across different clients without sharing data, to protect privacy
- A key challenge is data heterogeneity, where the local data distributions differ across clients
- This paper studies how data heterogeneity affects model representations, finding it leads to "dimensional collapse" where representations reside in a lower-dimensional space
- To address this, the paper proposes a method called FedDecorr that adds a regularization term to encourage uncorrelated representations during local training
Plain English Explanation
Federated learning is a way to train machine learning models without sharing the actual data from different computers or devices. This is useful for protecting people's privacy. However, a big challenge is that the data on each device may be quite different from the data on other devices.
This paper looks at how these differences in local data affect the representations, or features, learned by the overall federated model. Interestingly, they find that the differences cause the model's representations to "collapse" into a lower-dimensional space, rather than using the full available space.
The researchers also show that this representation collapse happens in the individual models trained on each device, and then gets inherited by the overall federated model. They provide a theoretical analysis to explain how the data differences lead to this collapse.
To fix this problem, the paper introduces a new method called FedDecorr. FedDecorr adds a extra term to the training process that encourages the different dimensions of the representations to be uncorrelated. This helps prevent the dimensional collapse caused by the heterogeneous data.
Tests on standard datasets show that FedDecorr can consistently improve performance over other approaches, while being easy to implement and computationally efficient.
Technical Explanation
The paper first studies how data heterogeneity, where the local data distributions differ across clients, affects the representations learned by the globally aggregated federated model. They find that this heterogeneity leads to "dimensional collapse", where the model's representations tend to reside in a lower-dimensional subspace rather than the full ambient space.
Further analysis reveals that this dimensional collapse is inherited from the individual models trained on each client. The researchers provide a theoretical analysis of the gradient flow dynamics to explain how the data heterogeneity causes this dimensional collapse in the local models.
To address this issue, the paper proposes FedDecorr, a novel federated learning method that applies a regularization term during local training to encourage the different dimensions of the representations to be uncorrelated. This helps mitigate the dimensional collapse caused by the heterogeneous data.
Experiments on standard benchmark datasets show that FedDecorr consistently outperforms baseline federated learning methods. The method is also implementation-friendly and computationally efficient.
Critical Analysis
The paper provides a thorough analysis of the dimensional collapse issue in federated learning due to data heterogeneity, and proposes an effective solution in the form of the FedDecorr method. However, a few potential limitations or areas for further research are worth noting:
-
The theoretical analysis focuses on fully-connected neural networks, and it's unclear how the insights would extend to more complex model architectures like convolutional or recurrent networks commonly used in practice. Further research may be needed to understand dimensional collapse in those settings.
-
The experiments are limited to image classification tasks. It would be valuable to evaluate FedDecorr on a wider range of applications, such as federated multimodal learning for biomedical vision, to understand its broader applicability.
-
The paper does not discuss potential issues that may arise when applying FedDecorr in cross-silo federated learning scenarios where the data distributions across clients are even more diverse.
Overall, the paper makes an important contribution to the federated learning literature by identifying and addressing a key challenge posed by data heterogeneity. The FedDecorr method appears promising, but further research is needed to fully understand its limitations and broader implications.
Conclusion
This paper tackles the critical challenge of data heterogeneity in federated learning, where differences in local data distributions across clients can lead to suboptimal performance of the globally aggregated model.
The key finding is that data heterogeneity causes "dimensional collapse" in the model representations, where they reside in a lower-dimensional subspace rather than the full available space. The researchers provide both empirical and theoretical analyses to understand this phenomenon.
To address this issue, the paper introduces the FedDecorr method, which applies a regularization term during local training to encourage uncorrelated representations. Experiments show that FedDecorr can consistently improve performance over baseline federated learning approaches, while being computationally efficient and easy to implement.
The insights and techniques presented in this work represent an important step forward in developing federated learning systems that can effectively handle heterogeneous data across clients, a key requirement for widespread adoption of this privacy-preserving machine learning paradigm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Advances in Robust Federated Learning: Heterogeneity Considerations
Chuan Chen, Tianchi Liao, Xiaojun Deng, Zihou Wu, Sheng Huang, Zibin Zheng
0
0
In the field of heterogeneous federated learning (FL), the key challenge is to efficiently and collaboratively train models across multiple clients with different data distributions, model structures, task objectives, computational capabilities, and communication resources. This diversity leads to significant heterogeneity, which increases the complexity of model training. In this paper, we first outline the basic concepts of heterogeneous federated learning and summarize the research challenges in federated learning in terms of five aspects: data, model, task, device, and communication. In addition, we explore how existing state-of-the-art approaches cope with the heterogeneity of federated learning, and categorize and review these approaches at three different levels: data-level, model-level, and architecture-level. Subsequently, the paper extensively discusses privacy-preserving strategies in heterogeneous federated learning environments. Finally, the paper discusses current open issues and directions for future research, aiming to promote the further development of heterogeneous federated learning.
5/17/2024
Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping
Ziqing Fan, Jiangchao Yao, Ruipeng Zhang, Lingjuan Lyu, Ya Zhang, Yanfeng Wang
0
0
Statistical heterogeneity severely limits the performance of federated learning (FL), motivating several explorations e.g., FedProx, MOON and FedDyn, to alleviate this problem. Despite effectiveness, their considered scenario generally requires samples from almost all classes during the local training of each client, although some covariate shifts may exist among clients. In fact, the natural case of partially class-disjoint data (PCDD), where each client contributes a few classes (instead of all classes) of samples, is practical yet underexplored. Specifically, the unique collapse and invasion characteristics of PCDD can induce the biased optimization direction in local training, which prevents the efficiency of federated learning. To address this dilemma, we propose a manifold reshaping approach called FedMR to calibrate the feature space of local training. Our FedMR adds two interplaying losses to the vanilla federated learning: one is intra-class loss to decorrelate feature dimensions for anti-collapse; and the other one is inter-class loss to guarantee the proper margin among categories in the feature expansion. We conduct extensive experiments on a range of datasets to demonstrate that our FedMR achieves much higher accuracy and better communication efficiency. Source code is available at: https://github.com/MediaBrain-SJTU/FedMR.git.
6/4/2024

Personalized federated learning based on feature fusion
Wolong Xing, Zhenkui Shi, Hongyan Peng, Xiantao Hu, Xianxian Li
0
0
Federated learning enables distributed clients to collaborate on training while storing their data locally to protect client privacy. However, due to the heterogeneity of data, models, and devices, the final global model may need to perform better for tasks on each client. Communication bottlenecks, data heterogeneity, and model heterogeneity have been common challenges in federated learning. In this work, we considered a label distribution skew problem, a type of data heterogeneity easily overlooked. In the context of classification, we propose a personalized federated learning approach called pFedPM. In our process, we replace traditional gradient uploading with feature uploading, which helps reduce communication costs and allows for heterogeneous client models. These feature representations play a role in preserving privacy to some extent. We use a hyperparameter $a$ to mix local and global features, which enables us to control the degree of personalization. We also introduced a relation network as an additional decision layer, which provides a non-linear learnable classifier to predict labels. Experimental results show that, with an appropriate setting of $a$, our scheme outperforms several recent FL methods on MNIST, FEMNIST, and CRIFAR10 datasets and achieves fewer communications.
6/26/2024

Personalized Federated Learning via Sequential Layer Expansion in Representation Learning
Jaewon Jang, Bonjun Choi
0
0
Federated learning ensures the privacy of clients by conducting distributed training on individual client devices and sharing only the model weights with a central server. However, in real-world scenarios, the heterogeneity of data among clients necessitates appropriate personalization methods. In this paper, we aim to address this heterogeneity using a form of parameter decoupling known as representation learning. Representation learning divides deep learning models into 'base' and 'head' components. The base component, capturing common features across all clients, is shared with the server, while the head component, capturing unique features specific to individual clients, remains local. We propose a new representation learning-based approach that suggests decoupling the entire deep learning model into more densely divided parts with the application of suitable scheduling methods, which can benefit not only data heterogeneity but also class heterogeneity. In this paper, we compare and analyze two layer scheduling approaches, namely forward (textit{Vanilla}) and backward (textit{Anti}), in the context of data and class heterogeneity among clients. Our experimental results show that the proposed algorithm, when compared to existing personalized federated learning algorithms, achieves increased accuracy, especially under challenging conditions, while reducing computation costs.
4/30/2024