Beyond One-Size-Fits-All: Adapting Counterfactual Explanations to User Objectives
2404.08721
0
0
🤖
Abstract
Explainable Artificial Intelligence (XAI) has emerged as a critical area of research aimed at enhancing the transparency and interpretability of AI systems. Counterfactual Explanations (CFEs) offer valuable insights into the decision-making processes of machine learning algorithms by exploring alternative scenarios where certain factors differ. Despite the growing popularity of CFEs in the XAI community, existing literature often overlooks the diverse needs and objectives of users across different applications and domains, leading to a lack of tailored explanations that adequately address the different use cases. In this paper, we advocate for a nuanced understanding of CFEs, recognizing the variability in desired properties based on user objectives and target applications. We identify three primary user objectives and explore the desired characteristics of CFEs in each case. By addressing these differences, we aim to design more effective and tailored explanations that meet the specific needs of users, thereby enhancing collaboration with AI systems.
Create account to get full access
Overview
- This paper explores adapting counterfactual explanations, which provide insights into why an AI model made a particular prediction, to the specific goals and preferences of individual users.
- The authors propose a framework that generates personalized counterfactual explanations by incorporating user objectives, such as minimizing changes to certain features or prioritizing particular outcomes.
- The goal is to provide explanations that are more meaningful and actionable for users, going beyond a one-size-fits-all approach.
Plain English Explanation
Artificial intelligence (AI) models are increasingly being used to make important decisions, such as loan approvals or medical diagnoses. However, these models can be complex and opaque, making it difficult for people to understand how they arrived at a particular conclusion.
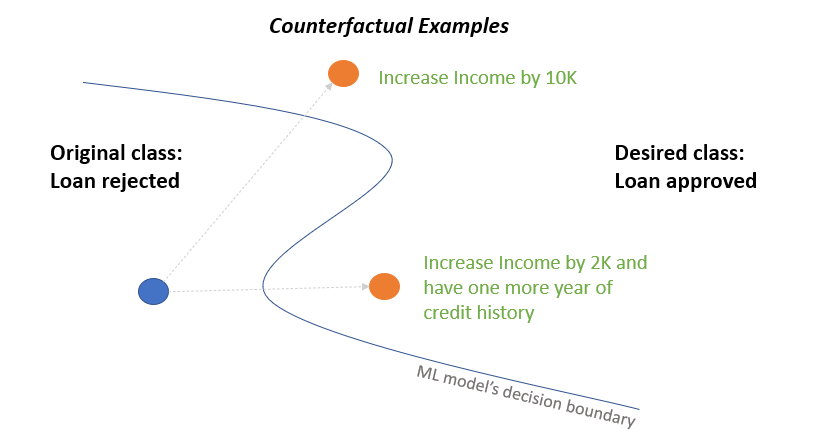
Counterfactual explanations are a way to shed light on the inner workings of an AI model. They identify the minimal changes to the input that would have resulted in a different output, effectively explaining the model's reasoning.
But the authors of this paper argue that a one-size-fits-all approach to counterfactual explanations may not be enough. Different users may have different goals and priorities when it comes to understanding an AI model's decision. For example, a loan applicant may want to know how they could have been approved, while a bank manager may be more interested in identifying the most cost-effective changes.
To address this, the researchers present a framework that can generate personalized counterfactual explanations tailored to the specific objectives of individual users. By incorporating these user goals, the explanations become more meaningful and actionable, helping people better understand and trust the AI systems they interact with.
Technical Explanation
The paper introduces a framework called User-Centric Counterfactual Explanations (UCCE), which aims to generate counterfactual explanations that are customized to the objectives and preferences of individual users.
The key components of the UCCE framework are:
- User Objectives: The framework allows users to specify their goals, such as minimizing changes to certain features or prioritizing particular outcomes.
- Counterfactual Generation: The framework uses an optimization-based approach to generate counterfactual examples that satisfy the user's objectives.
- Explanation Presentation: The framework presents the counterfactual explanations in a way that highlights the user's priorities and makes the insights more actionable.
The authors demonstrate the effectiveness of the UCCE framework through experiments on several real-world datasets, including credit scoring and medical diagnosis tasks. They show that the personalized counterfactual explanations generated by their approach are more useful and meaningful to users compared to standard one-size-fits-all counterfactual explanations.
Critical Analysis
The paper makes a compelling case for the importance of adapting counterfactual explanations to individual user objectives. By incorporating user goals, the framework can generate more personalized and actionable insights, which is crucial for building trust and understanding in AI systems.
However, the paper does not address the potential challenges of eliciting user objectives, particularly in complex or high-stakes decision-making scenarios. Gathering accurate and comprehensive user preferences may be difficult, and the framework's performance could be sensitive to the quality of this input.
Additionally, the paper focuses on a single user at a time, but in many real-world applications, multiple stakeholders with conflicting objectives may need to be considered. Extending the framework to handle such multi-user scenarios could be an important area for future research.
Another potential limitation is the computational complexity of the optimization-based approach used for counterfactual generation. As the number of features and user objectives increases, the optimization problem may become increasingly challenging to solve efficiently, which could limit the framework's scalability.
Conclusion
This paper presents a promising approach to adapting counterfactual explanations to the specific goals and preferences of individual users. By incorporating user objectives, the framework can generate more personalized and actionable insights, which is crucial for building trust and understanding in AI systems.
The research highlights the importance of moving beyond a one-size-fits-all approach to explainable AI and tailoring explanations to the needs and priorities of the people interacting with these systems. As AI becomes more pervasive in high-stakes decision-making, this type of user-centric approach to explanation generation will likely become increasingly important.
Overall, the paper makes a valuable contribution to the field of explainable AI and sets the stage for further research on personalizing AI explanations to better serve the diverse needs and preferences of users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unifying Perspectives: Plausible Counterfactual Explanations on Global, Group-wise, and Local Levels
Patryk Wielopolski, Oleksii Furman, Jerzy Stefanowski, Maciej Zik{e}ba
0
0
Growing regulatory and societal pressures demand increased transparency in AI, particularly in understanding the decisions made by complex machine learning models. Counterfactual Explanations (CFs) have emerged as a promising technique within Explainable AI (xAI), offering insights into individual model predictions. However, to understand the systemic biases and disparate impacts of AI models, it is crucial to move beyond local CFs and embrace global explanations, which offer a~holistic view across diverse scenarios and populations. Unfortunately, generating Global Counterfactual Explanations (GCEs) faces challenges in computational complexity, defining the scope of global, and ensuring the explanations are both globally representative and locally plausible. We introduce a novel unified approach for generating Local, Group-wise, and Global Counterfactual Explanations for differentiable classification models via gradient-based optimization to address these challenges. This framework aims to bridge the gap between individual and systemic insights, enabling a deeper understanding of model decisions and their potential impact on diverse populations. Our approach further innovates by incorporating a probabilistic plausibility criterion, enhancing actionability and trustworthiness. By offering a cohesive solution to the optimization and plausibility challenges in GCEs, our work significantly advances the interpretability and accountability of AI models, marking a step forward in the pursuit of transparent AI.
5/29/2024
Watermarking Counterfactual Explanations
Hangzhi Guo, Amulya Yadav
0
0
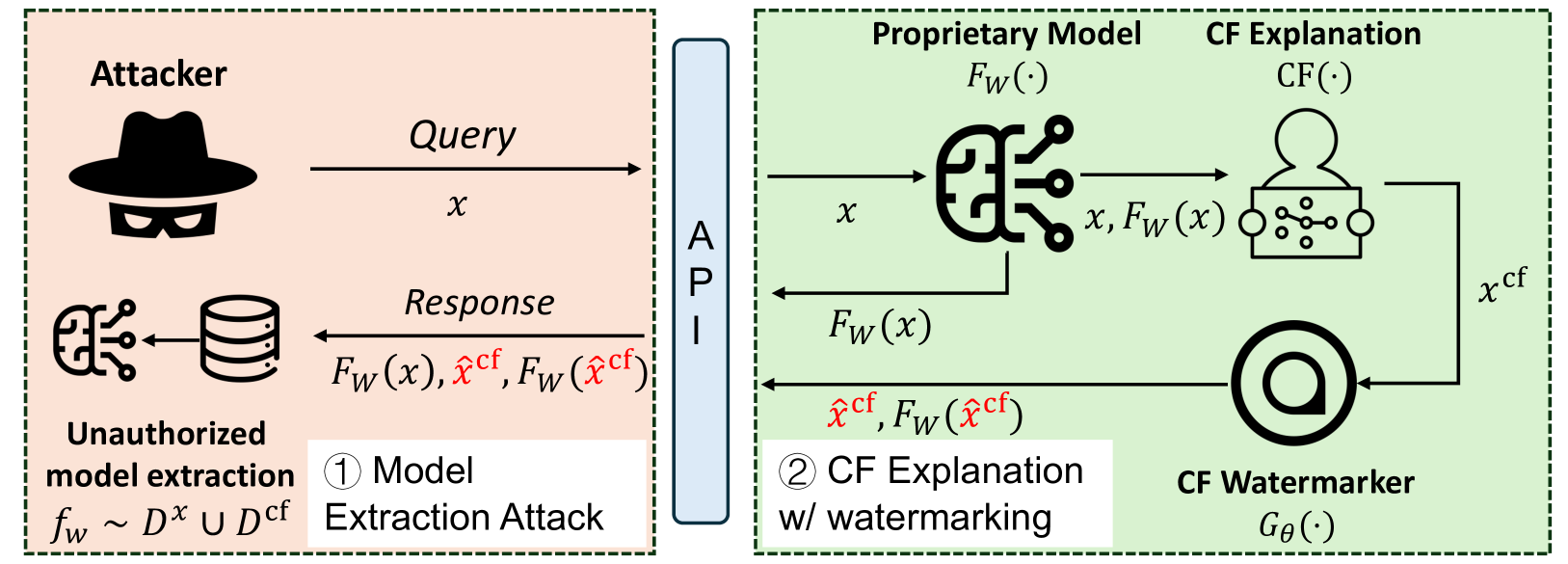
The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
5/30/2024
🎯
Benchmarking Instance-Centric Counterfactual Algorithms for XAI: From White Box to Black Bo
Catarina Moreira, Yu-Liang Chou, Chihcheng Hsieh, Chun Ouyang, Joaquim Jorge, Jo~ao Madeiras Pereira
0
0
This study investigates the impact of machine learning models on the generation of counterfactual explanations by conducting a benchmark evaluation over three different types of models: a decision tree (fully transparent, interpretable, white-box model), a random forest (semi-interpretable, grey-box model), and a neural network (fully opaque, black-box model). We tested the counterfactual generation process using four algorithms (DiCE, WatcherCF, prototype, and GrowingSpheresCF) in the literature in 25 different datasets. Our findings indicate that: (1) Different machine learning models have little impact on the generation of counterfactual explanations; (2) Counterfactual algorithms based uniquely on proximity loss functions are not actionable and will not provide meaningful explanations; (3) One cannot have meaningful evaluation results without guaranteeing plausibility in the counterfactual generation. Algorithms that do not consider plausibility in their internal mechanisms will lead to biased and unreliable conclusions if evaluated with the current state-of-the-art metrics; (4) A counterfactual inspection analysis is strongly recommended to ensure a robust examination of counterfactual explanations and the potential identification of biases.
6/12/2024
A Framework for Feasible Counterfactual Exploration incorporating Causality, Sparsity and Density
Kleopatra Markou, Dimitrios Tomaras, Vana Kalogeraki, Dimitrios Gunopulos
0
0
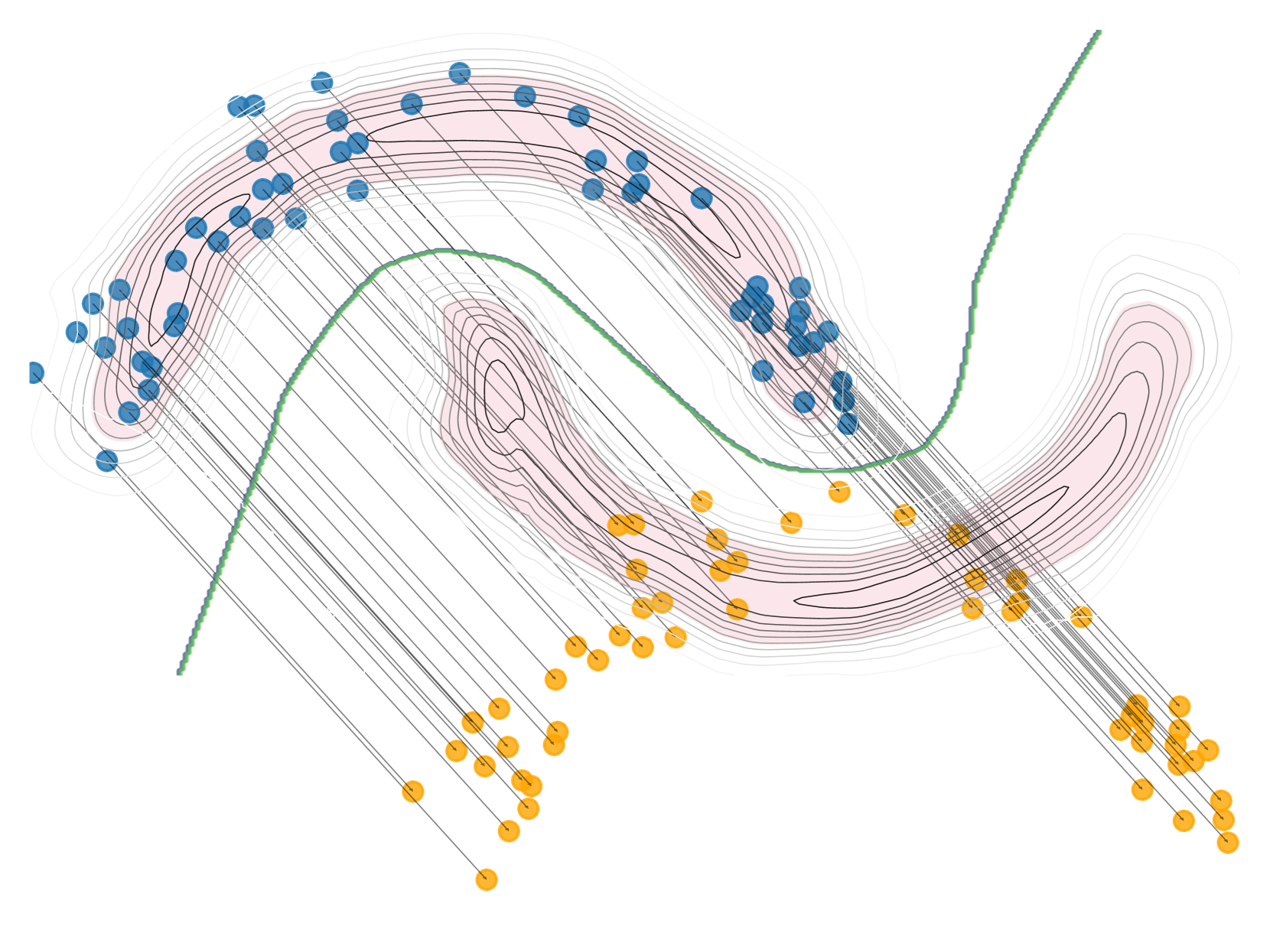
The imminent need to interpret the output of a Machine Learning model with counterfactual (CF) explanations - via small perturbations to the input - has been notable in the research community. Although the variety of CF examples is important, the aspect of them being feasible at the same time, does not necessarily apply in their entirety. This work uses different benchmark datasets to examine through the preservation of the logical causal relations of their attributes, whether CF examples can be generated after a small amount of changes to the original input, be feasible and actually useful to the end-user in a real-world case. To achieve this, we used a black box model as a classifier, to distinguish the desired from the input class and a Variational Autoencoder (VAE) to generate feasible CF examples. As an extension, we also extracted two-dimensional manifolds (one for each dataset) that located the majority of the feasible examples, a representation that adequately distinguished them from infeasible ones. For our experimentation we used three commonly used datasets and we managed to generate feasible and at the same time sparse, CF examples that satisfy all possible predefined causal constraints, by confirming their importance with the attributes in a dataset.
4/23/2024