UniLearn: Enhancing Dynamic Facial Expression Recognition through Unified Pre-Training and Fine-Tuning on Images and Videos

0

Sign in to get full access
Overview
- This paper presents a novel deep learning framework called UniLearn for enhancing dynamic facial expression recognition (DFER) by unifying pre-training and fine-tuning on both image and video data.
- The key idea is to leverage the complementary information from static images and dynamic videos to improve the performance of DFER models.
- UniLearn aims to achieve robust and generalized DFER through a unified training strategy across different data modalities.
Plain English Explanation
The paper introduces a new deep learning system called UniLearn that is designed to improve the recognition of dynamic facial expressions. Facial expressions can convey a lot of information about a person's emotions and state of mind, but recognizing them from video data (dynamic expressions) is a challenging task.
The core innovation of UniLearn is that it [learns from both image and video data] to build a more robust and accurate facial expression recognition model. By [combining the complementary information] found in static images and dynamic videos, UniLearn is able to outperform models that only use one data type.
The key idea is to [pre-train the model on a large dataset of facial images], which helps it learn general features about faces and expressions. Then, the model is [fine-tuned on video data] to specialize in recognizing how expressions change over time. This two-stage training process allows UniLearn to [leverage the benefits of both data types] and achieve better performance than previous approaches.
In summary, UniLearn is a novel deep learning framework that aims to enhance the recognition of dynamic facial expressions by [unifying the training on image and video data]. This approach produces more robust and accurate models compared to relying on just one data modality.
Technical Explanation
The paper proposes a novel deep learning framework called [UniLearn] that is designed to enhance [dynamic facial expression recognition (DFER)] by [unifying the pre-training and fine-tuning process] on both [image and video data].
The key innovation is [leveraging the complementary information] provided by static images and dynamic videos to build more robust and generalized DFER models. The [two-stage training strategy] involves:
- [Pre-training the model on a large dataset of facial images] to learn general feature representations about faces and expressions.
- [Fine-tuning the pre-trained model on video data] to specialize in recognizing how facial expressions change over time.
This unified training approach allows UniLearn to [capture both the static and dynamic cues] present in facial expressions, leading to improved performance compared to models trained on a single data modality.
The [UniLearn architecture] consists of a [shared backbone network] that is pre-trained on images, followed by [separate branches] for processing image and video inputs. The [outputs from these branches] are then [combined] to produce the final facial expression prediction.
Extensive experiments on [benchmark DFER datasets] demonstrate that UniLearn [outperforms state-of-the-art methods] for facial expression recognition, showcasing the benefits of the proposed unified training strategy.
Critical Analysis
The paper presents a well-designed and thorough study on enhancing dynamic facial expression recognition through the UniLearn framework. The key strengths of the research include:
- [Innovative Unified Training Approach]: The idea of leveraging [complementary information from images and videos] to improve DFER models is a promising direction that has not been extensively explored before.
- [Rigorous Experimental Evaluation]: The authors provide a comprehensive set of experiments on [multiple benchmark datasets], thoroughly validating the effectiveness of UniLearn.
- [Potential for Real-World Applications]: Accurate DFER has many practical applications, such as [human-computer interaction, mental health monitoring, and emotion-aware systems], making this research highly relevant.
However, the paper also has some limitations that could be addressed in future work:
- [Dataset Biases]: The datasets used for evaluation may not fully capture the [diversity of facial expressions] encountered in real-world scenarios, potentially limiting the generalization of the UniLearn model.
- [Computational Complexity]: The [two-stage training process] and the [separate branches] for image and video processing may increase the computational requirements of UniLearn, which could be a concern for deployment in resource-constrained environments.
- [Interpretability]: The paper does not provide much insight into [how the unified training process impacts the learned representations] and the specific mechanisms by which UniLearn achieves its performance gains.
Overall, the UniLearn framework represents a promising step forward in enhancing dynamic facial expression recognition, and the authors' findings contribute valuable insights to the field. Future research could explore ways to [address the noted limitations] and further [investigate the interpretability and generalization capabilities] of the proposed approach.
Conclusion
This paper introduces UniLearn, a novel deep learning framework that aims to enhance dynamic facial expression recognition (DFER) by [unifying the pre-training and fine-tuning process on both image and video data]. The key innovation is [leveraging the complementary information] provided by static images and dynamic videos to build more robust and generalized DFER models.
The [two-stage training strategy] of UniLearn, which involves [pre-training on facial images followed by fine-tuning on video data], allows the model to [capture both static and dynamic cues] present in facial expressions. Extensive experiments demonstrate that UniLearn [outperforms state-of-the-art methods] for DFER, highlighting the benefits of the proposed unified training approach.
The potential real-world applications of accurate DFER, such as [human-computer interaction, mental health monitoring, and emotion-aware systems], make this research highly relevant and impactful. While the paper presents some limitations, the UniLearn framework represents a promising step forward in enhancing dynamic facial expression recognition, and the insights gained from this study can inspire further advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UniLearn: Enhancing Dynamic Facial Expression Recognition through Unified Pre-Training and Fine-Tuning on Images and Videos
Yin Chen, Jia Li, Yu Zhang, Zhenzhen Hu, Shiguang Shan, Meng Wang, Richang Hong
Dynamic facial expression recognition (DFER) is essential for understanding human emotions and behavior. However, conventional DFER methods, which primarily use dynamic facial data, often underutilize static expression images and their labels, limiting their performance and robustness. To overcome this, we introduce UniLearn, a novel unified learning paradigm that integrates static facial expression recognition (SFER) data to enhance DFER task. UniLearn employs a dual-modal self-supervised pre-training method, leveraging both facial expression images and videos to enhance a ViT model's spatiotemporal representation capability. Then, the pre-trained model is fine-tuned on both static and dynamic expression datasets using a joint fine-tuning strategy. To prevent negative transfer during joint fine-tuning, we introduce an innovative Mixture of Adapter Experts (MoAE) module that enables task-specific knowledge acquisition and effectively integrates information from both static and dynamic expression data. Extensive experiments demonstrate UniLearn's effectiveness in leveraging complementary information from static and dynamic facial data, leading to more accurate and robust DFER. UniLearn consistently achieves state-of-the-art performance on FERV39K, MAFW, and DFEW benchmarks, with weighted average recall (WAR) of 53.65%, 58.44%, and 76.68%, respectively. The source code and model weights will be publicly available at url{https://github.com/MSA-LMC/UniLearn}.
Read more9/11/2024
0
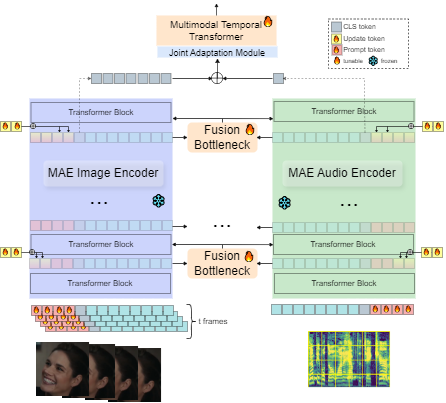
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Kateryna Chumachenko, Alexandros Iosifidis, Moncef Gabbouj
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
Read more4/16/2024

0
A Survey on Facial Expression Recognition of Static and Dynamic Emotions
Yan Wang, Shaoqi Yan, Yang Liu, Wei Song, Jing Liu, Yang Chang, Xinji Mai, Xiping Hu, Wenqiang Zhang, Zhongxue Gan
Facial expression recognition (FER) aims to analyze emotional states from static images and dynamic sequences, which is pivotal in enhancing anthropomorphic communication among humans, robots, and digital avatars by leveraging AI technologies. As the FER field evolves from controlled laboratory environments to more complex in-the-wild scenarios, advanced methods have been rapidly developed and new challenges and apporaches are encounted, which are not well addressed in existing reviews of FER. This paper offers a comprehensive survey of both image-based static FER (SFER) and video-based dynamic FER (DFER) methods, analyzing from model-oriented development to challenge-focused categorization. We begin with a critical comparison of recent reviews, an introduction to common datasets and evaluation criteria, and an in-depth workflow on FER to establish a robust research foundation. We then systematically review representative approaches addressing eight main challenges in SFER (such as expression disturbance, uncertainties, compound emotions, and cross-domain inconsistency) as well as seven main challenges in DFER (such as key frame sampling, expression intensity variations, and cross-modal alignment). Additionally, we analyze recent advancements, benchmark performances, major applications, and ethical considerations. Finally, we propose five promising future directions and development trends to guide ongoing research. The project page for this paper can be found at https://github.com/wangyanckxx/SurveyFER.
Read more8/29/2024
0
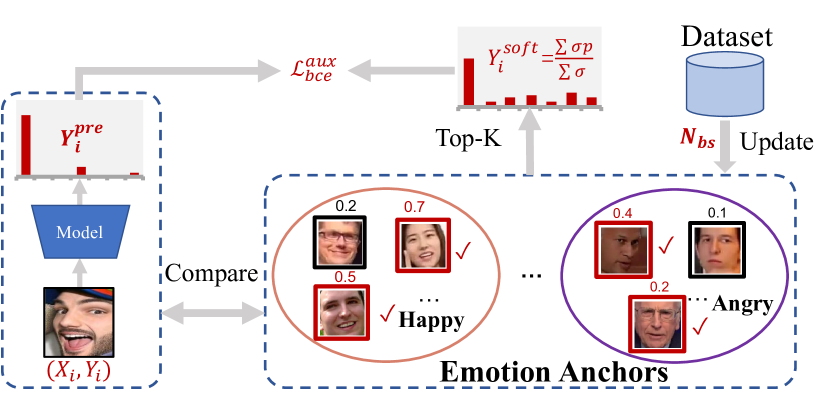
From Static to Dynamic: Adapting Landmark-Aware Image Models for Facial Expression Recognition in Videos
Yin Chen, Jia Li, Shiguang Shan, Meng Wang, Richang Hong
Dynamic facial expression recognition (DFER) in the wild is still hindered by data limitations, e.g., insufficient quantity and diversity of pose, occlusion and illumination, as well as the inherent ambiguity of facial expressions. In contrast, static facial expression recognition (SFER) currently shows much higher performance and can benefit from more abundant high-quality training data. Moreover, the appearance features and dynamic dependencies of DFER remain largely unexplored. To tackle these challenges, we introduce a novel Static-to-Dynamic model (S2D) that leverages existing SFER knowledge and dynamic information implicitly encoded in extracted facial landmark-aware features, thereby significantly improving DFER performance. Firstly, we build and train an image model for SFER, which incorporates a standard Vision Transformer (ViT) and Multi-View Complementary Prompters (MCPs) only. Then, we obtain our video model (i.e., S2D), for DFER, by inserting Temporal-Modeling Adapters (TMAs) into the image model. MCPs enhance facial expression features with landmark-aware features inferred by an off-the-shelf facial landmark detector. And the TMAs capture and model the relationships of dynamic changes in facial expressions, effectively extending the pre-trained image model for videos. Notably, MCPs and TMAs only increase a fraction of trainable parameters (less than +10%) to the original image model. Moreover, we present a novel Emotion-Anchors (i.e., reference samples for each emotion category) based Self-Distillation Loss to reduce the detrimental influence of ambiguous emotion labels, further enhancing our S2D. Experiments conducted on popular SFER and DFER datasets show that we achieve the state of the art.
Read more9/10/2024