UniMem: Towards a Unified View of Long-Context Large Language Models

0
💬
Sign in to get full access
Overview
- This paper addresses the challenge of long-context processing in large language models (LLMs).
- It introduces UniMem, a unified framework for analyzing and developing methods to enhance long-context processing in LLMs.
- The paper re-formulates 16 existing long-context processing methods using the UniMem framework and analyzes four representative methods in detail.
- Based on these analyses, the paper proposes UniMix, an innovative approach that integrates the strengths of the analyzed algorithms.
- Experimental results show that UniMix achieves superior performance in handling long contexts compared to baseline methods.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and perform various language-related tasks. However, one of the key limitations of LLMs is their ability to process and understand long contexts, which is critical for many real-world applications.
UniMem: A Unified Framework for Long-Context Processing in Large Language Models introduces a new approach to address this challenge. The paper proposes a framework called UniMem, which provides a systematic way to analyze and develop methods for enhancing the long-context processing capabilities of LLMs.
The core idea behind UniMem is to view the long-context processing problem through the lens of "memory augmentation" – how can we effectively extend the memory and reasoning capabilities of LLMs to handle longer contexts? UniMem defines four key dimensions of this problem: Memory Management, Memory Writing, Memory Reading, and Memory Injection.
The researchers then take 16 existing long-context processing methods and re-formulate them using the UniMem framework. They analyze four of these methods in depth – Transformer-XL, Memorizing Transformer, RMT, and Longformer – to understand their design principles and strengths.
Based on these insights, the paper introduces UniMix, a new approach that integrates the strengths of the analyzed algorithms. The key innovation of UniMix is its ability to effectively combine and balance different memory management and access strategies to achieve superior long-context processing performance.
The experimental results presented in the paper show that UniMix outperforms various baseline methods in terms of perplexity (a measure of language modeling performance) on long-context tasks, demonstrating the potential of this unified approach to advance the state-of-the-art in long-context processing for LLMs.
Technical Explanation
The paper introduces UniMem, a Unified framework for reformulating and analyzing existing methods for enhancing the long-context processing ability of large language models (LLMs). The UniMem framework consists of four core dimensions:
- Memory Management: Strategies for managing the memory used by the LLM, such as resetting, updating, or preserving memory across context windows.
- Memory Writing: Techniques for encoding the current input into the model's memory.
- Memory Reading: Mechanisms for selectively retrieving relevant information from the model's memory.
- Memory Injection: Methods for integrating the retrieved memory information with the current input to produce the final output.
The researchers re-formulate 16 existing long-context processing methods using the UniMem framework and analyze four representative methods in depth:
- Transformer-XL: A method that uses a recurrent segment-level recurrence mechanism to maintain a longer context.
- Memorizing Transformer: A model that learns to selectively store and retrieve relevant information from its memory.
- RMT (Rethinking Long-Range Modeling): An approach that uses a sparse attention mechanism to efficiently capture long-range dependencies.
- Longformer: A model that employs a local and global attention mechanism to handle long contexts.
By analyzing these methods through the lens of the UniMem framework, the paper reveals the design principles and strengths of each approach, which informs the development of UniMix – an innovative method that integrates the strengths of these algorithms.
The experimental results demonstrate that UniMix achieves superior performance in handling long contexts, with significantly lower perplexity than baseline methods on various long-context language modeling tasks.
Critical Analysis
The paper presents a comprehensive and well-structured analysis of the long-context processing problem in large language models, and the UniMem framework provides a valuable tool for researchers to systematically explore and develop new methods in this domain.
One potential limitation of the paper is that the analysis of the four representative methods is relatively high-level, and the paper does not delve into the specific technical details of how each method is implemented within the UniMem framework. While the paper does provide some insights into the design principles of these methods, a more in-depth technical discussion could have further strengthened the analysis.
Additionally, the paper does not address the potential computational and memory overhead associated with the proposed UniMix approach, which is an important practical consideration for real-world deployment of these models. The authors could have discussed strategies for mitigating these issues or provided a more comprehensive analysis of the trade-offs involved.
Overall, the paper presents a valuable contribution to the field of long-context processing in large language models, and the UniMem framework and UniMix approach show promising potential for advancing the state-of-the-art in this area. Further research and development in this direction could lead to significant improvements in the ability of LLMs to handle complex, long-form language tasks.
Conclusion
This paper introduces UniMem, a unified framework for analyzing and developing methods to enhance the long-context processing capabilities of large language models (LLMs). The framework provides a systematic way to reformulate and understand existing long-context processing techniques, and the paper's in-depth analysis of four representative methods reveals important design principles and strengths.
Based on these insights, the paper proposes UniMix, an innovative approach that integrates the strengths of the analyzed algorithms. Experimental results demonstrate that UniMix outperforms baseline methods in handling long contexts, suggesting that this unified approach has the potential to significantly advance the state-of-the-art in long-context processing for LLMs.
The UniMem framework and the UniMix method introduced in this paper represent an important step forward in addressing a critical limitation of large language models. By enabling more effective long-context processing, these advancements could unlock new possibilities for LLMs to tackle complex, real-world language tasks and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
UniMem: Towards a Unified View of Long-Context Large Language Models
Junjie Fang, Likai Tang, Hongzhe Bi, Yujia Qin, Si Sun, Zhenyu Li, Haolun Li, Yongjian Li, Xin Cong, Yankai Lin, Yukun Yan, Xiaodong Shi, Sen Song, Zhiyuan Liu, Maosong Sun
Long-context processing is a critical ability that constrains the applicability of large language models (LLMs). Although there exist various methods devoted to enhancing the long-context processing ability of LLMs, they are developed in an isolated manner and lack systematic analysis and integration of their strengths, hindering further developments. In this paper, we introduce UniMem, a Unified framework that reformulates existing long-context methods from the view of Memory augmentation of LLMs. Distinguished by its four core dimensions-Memory Management, Memory Writing, Memory Reading, and Memory Injection, UniMem empowers researchers to conduct systematic exploration of long-context methods. We re-formulate 16 existing methods based on UniMem and analyze four representative methods: Transformer-XL, Memorizing Transformer, RMT, and Longformer into equivalent UniMem forms to reveal their design principles and strengths. Based on these analyses, we propose UniMix, an innovative approach that integrates the strengths of these algorithms. Experimental results show that UniMix achieves superior performance in handling long contexts with significantly lower perplexity than baselines.
Read more8/20/2024

0
MemLong: Memory-Augmented Retrieval for Long Text Modeling
Weijie Liu, Zecheng Tang, Juntao Li, Kehai Chen, Min Zhang
Recent advancements in Large Language Models (LLMs) have yielded remarkable success across diverse fields. However, handling long contexts remains a significant challenge for LLMs due to the quadratic time and space complexity of attention mechanisms and the growing memory consumption of the key-value cache during generation. This work introduces MemLong: Memory-Augmented Retrieval for Long Text Generation, a method designed to enhance the capabilities of long-context language modeling by utilizing an external retriever for historical information retrieval. MemLong combines a non-differentiable ``ret-mem'' module with a partially trainable decoder-only language model and introduces a fine-grained, controllable retrieval attention mechanism that leverages semantic-level relevant chunks. Comprehensive evaluations on multiple long-context language modeling benchmarks demonstrate that MemLong consistently outperforms other state-of-the-art LLMs. More importantly, MemLong can extend the context length on a single 3090 GPU from 4k up to 80k. Our code is available at https://github.com/Bui1dMySea/MemLong
Read more9/2/2024

0
A Multi-Perspective Analysis of Memorization in Large Language Models
Bowen Chen, Namgi Han, Yusuke Miyao
Large Language Models (LLMs), trained on massive corpora with billions of parameters, show unprecedented performance in various fields. Though surprised by their excellent performances, researchers also noticed some special behaviors of those LLMs. One of those behaviors is memorization, in which LLMs can generate the same content used to train them. Though previous research has discussed memorization, the memorization of LLMs still lacks explanation, especially the cause of memorization and the dynamics of generating them. In this research, we comprehensively discussed memorization from various perspectives and extended the discussion scope to not only just the memorized content but also less and unmemorized content. Through various studies, we found that: (1) Through experiments, we revealed the relation of memorization between model size, continuation size, and context size. Further, we showed how unmemorized sentences transition to memorized sentences. (2) Through embedding analysis, we showed the distribution and decoding dynamics across model size in embedding space for sentences with different memorization scores. The n-gram statistics analysis presents d (3) An analysis over n-gram and entropy decoding dynamics discovered a boundary effect when the model starts to generate memorized sentences or unmemorized sentences. (4)We trained a Transformer model to predict the memorization of different models, showing that it is possible to predict memorizations by context.
Read more6/5/2024
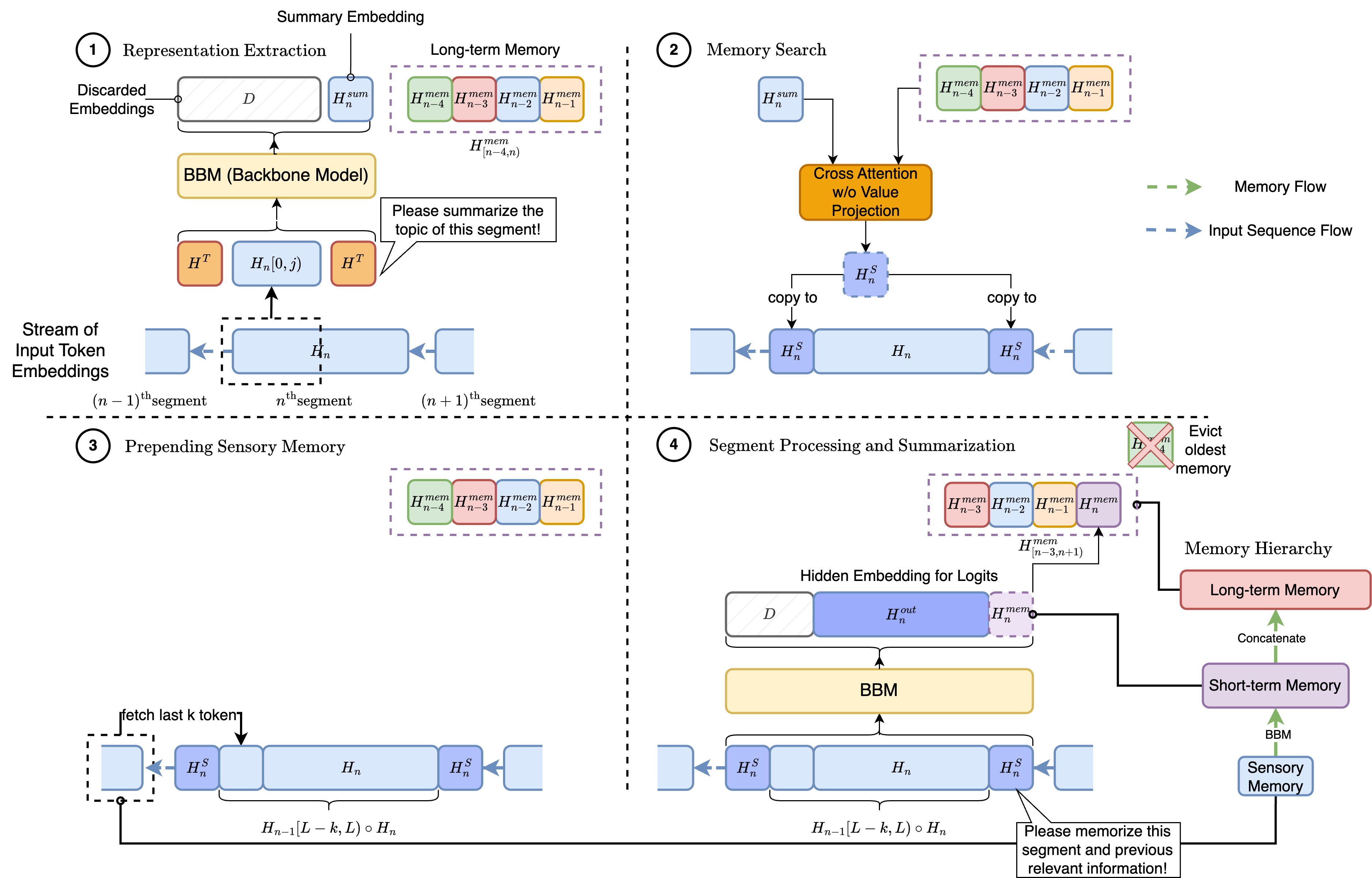
60
HMT: Hierarchical Memory Transformer for Long Context Language Processing
Zifan He, Zongyue Qin, Neha Prakriya, Yizhou Sun, Jason Cong
Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every token in the inputs. Previous works in recurrent models can memorize past tokens to enable unlimited context and maintain effectiveness. However, they have flat memory architectures, which have limitations in selecting and filtering information. Since humans are good at learning and self-adjustment, we speculate that imitating brain memory hierarchy is beneficial for model memorization. We propose the Hierarchical Memory Transformer (HMT), a novel framework that enables and improves models' long-context processing ability by imitating human memorization behavior. Leveraging memory-augmented segment-level recurrence, we organize the memory hierarchy by preserving tokens from early input token segments, passing memory embeddings along the sequence, and recalling relevant information from history. Evaluating general language modeling (Wikitext-103, PG-19) and question-answering tasks (PubMedQA), we show that HMT steadily improves the long-context processing ability of context-constrained and long-context models. With an additional 0.5% - 2% of parameters, HMT can easily plug in and augment future LLMs to handle long context effectively. Our code is open-sourced on Github: https://github.com/OswaldHe/HMT-pytorch.
Read more5/15/2024