UNIT: Unsupervised Online Instance Segmentation through Time

0
Sign in to get full access
Overview
- Introduces a new unsupervised online instance segmentation technique called UNIT
- Allows for real-time segmentation of objects in video without any prior information
- Learns object representations and tracks them over time in an unsupervised way
Plain English Explanation
UNIT is a new AI system that can automatically segment and track individual objects in videos, without any prior training or information about the objects. It works by learning representations of the different objects as the video plays, and then keeping track of those objects over time, all in an unsupervised way.
This means the system doesn't need to be shown examples of the objects beforehand, or have any pre-defined knowledge about what the objects are. It can just watch the video and figure out on its own what the different objects are and where they are located. This allows it to work in real-time, segmenting the objects as the video is playing.
The key innovation of UNIT is that it can learn these object representations and track them over time in an unsupervised way, without any human supervision or labeling of the objects. This makes it much more flexible and scalable than previous approaches that required that kind of manual input.
Overall, UNIT represents an important step forward in making object segmentation and tracking systems that can work in dynamic, real-world environments without needing extensive prior training or human annotations. This could have applications in areas like autonomous vehicles, robotics, and video analysis.
Technical Explanation
The UNIT system works by learning a set of latent object representations in an unsupervised way as it observes the video frames. It does this by using a deep neural network encoder to map each video frame into a set of latent vectors, where each vector corresponds to a distinct segmented object.
To track these objects over time, UNIT uses a memory module that stores the historical latent representations of each object. When a new frame is processed, UNIT compares the current latent vectors to the stored memories to associate the new detections with previously tracked objects.
This allows UNIT to maintain unique IDs for each detected object and follow their trajectories through the video, all in an online, unsupervised manner. The system is trained end-to-end using a combination of reconstruction, segmentation, and tracking losses, which encourage it to learn effective latent representations for this task.
Experiments on benchmark video segmentation datasets show that UNIT achieves strong performance, outperforming previous unsupervised and weakly-supervised methods. Its ability to segment and track objects in real-time without any prior information is a notable capability that could enable new applications in dynamic scene understanding.
Critical Analysis
The UNIT paper presents a compelling approach to unsupervised online instance segmentation that addresses some key limitations of prior work. By learning object representations in an unsupervised way and tracking them over time, UNIT avoids the need for manual object annotations or pre-defined object models.
However, the paper does acknowledge some potential limitations and areas for future work. For example, the system may struggle with partial occlusions or highly complex scenes with many interacting objects. The authors suggest incorporating additional cues like motion or appearance to improve robustness in these scenarios.
Additionally, while UNIT demonstrates strong performance on benchmark datasets, its real-world generalization capabilities are not fully explored. Deploying such a system in unconstrained environments would likely require further advances in areas like out-of-distribution robustness and few-shot adaptation.
Overall, UNIT represents an exciting step forward, but there remains room for improvement and further research to enhance the capabilities of unsupervised online instance segmentation systems. Continued advancements in this direction could unlock new applications in areas like robotics, autonomous vehicles, and video analysis.
Conclusion
The UNIT paper introduces a novel unsupervised approach to online instance segmentation that can learn object representations and track them over time without any prior information or manual annotations. This is an important capability that could enable more flexible and scalable object understanding in dynamic real-world environments.
While UNIT shows promising results, the paper also identifies some limitations and areas for future work. Addressing challenges like occlusions, complex scenes, and real-world robustness will be crucial for unlocking the full potential of this technology. Nonetheless, the core ideas behind UNIT represent a significant advancement in the field of unsupervised scene understanding.
As research in this area continues to progress, we may see UNIT-like techniques enabling new applications in robotics, autonomous vehicles, video analysis, and beyond. The ability to perceive and track objects in an unsupervised way could be transformative for building systems that can flexibly and intelligently navigate dynamic real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UNIT: Unsupervised Online Instance Segmentation through Time
Corentin Sautier, Gilles Puy, Alexandre Boulch, Renaud Marlet, Vincent Lepetit
Online object segmentation and tracking in Lidar point clouds enables autonomous agents to understand their surroundings and make safe decisions. Unfortunately, manual annotations for these tasks are prohibitively costly. We tackle this problem with the task of class-agnostic unsupervised online instance segmentation and tracking. To that end, we leverage an instance segmentation backbone and propose a new training recipe that enables the online tracking of objects. Our network is trained on pseudo-labels, eliminating the need for manual annotations. We conduct an evaluation using metrics adapted for temporal instance segmentation. Computing these metrics requires temporally-consistent instance labels. When unavailable, we construct these labels using the available 3D bounding boxes and semantic labels in the dataset. We compare our method against strong baselines and demonstrate its superiority across two different outdoor Lidar datasets.
Read more9/14/2024
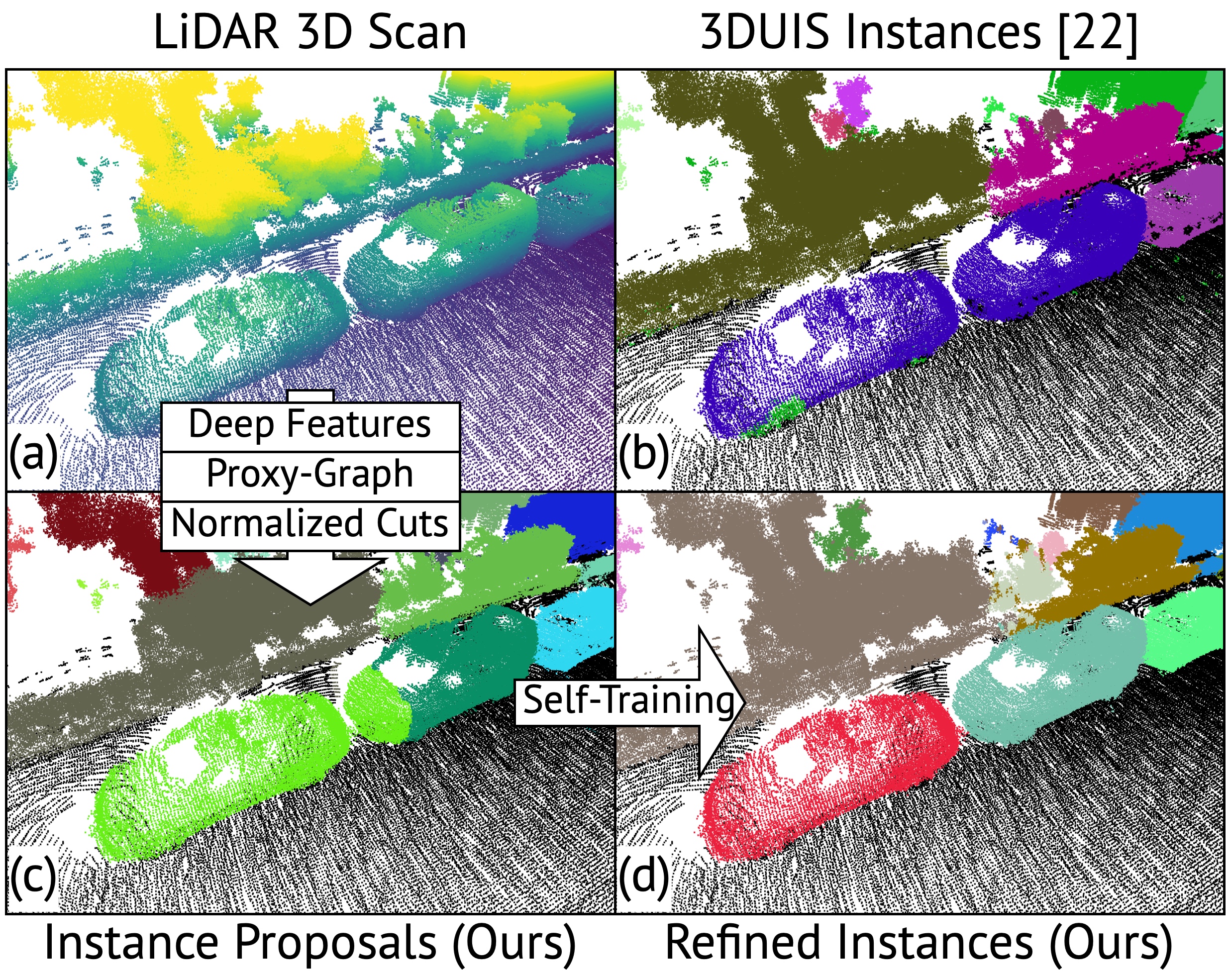
0
AutoInst: Automatic Instance-Based Segmentation of LiDAR 3D Scans
Cedric Perauer, Laurenz Adrian Heidrich, Haifan Zhang, Matthias Nie{ss}ner, Anastasiia Kornilova, Alexey Artemov
Recently, progress in acquisition equipment such as LiDAR sensors has enabled sensing increasingly spacious outdoor 3D environments. Making sense of such 3D acquisitions requires fine-grained scene understanding, such as constructing instance-based 3D scene segmentations. Commonly, a neural network is trained for this task; however, this requires access to a large, densely annotated dataset, which is widely known to be challenging to obtain. To address this issue, in this work we propose to predict instance segmentations for 3D scenes in an unsupervised way, without relying on ground-truth annotations. To this end, we construct a learning framework consisting of two components: (1) a pseudo-annotation scheme for generating initial unsupervised pseudo-labels; and (2) a self-training algorithm for instance segmentation to fit robust, accurate instances from initial noisy proposals. To enable generating 3D instance mask proposals, we construct a weighted proxy-graph by connecting 3D points with edges integrating multi-modal image- and point-based self-supervised features, and perform graph-cuts to isolate individual pseudo-instances. We then build on a state-of-the-art point-based architecture and train a 3D instance segmentation model, resulting in significant refinement of initial proposals. To scale to arbitrary complexity 3D scenes, we design our algorithm to operate on local 3D point chunks and construct a merging step to generate scene-level instance segmentations. Experiments on the challenging SemanticKITTI benchmark demonstrate the potential of our approach, where it attains 13.3% higher Average Precision and 9.1% higher F1 score compared to the best-performing baseline. The code will be made publicly available at https://github.com/artonson/autoinst.
Read more8/30/2024
🤷
0
UnScene3D: Unsupervised 3D Instance Segmentation for Indoor Scenes
David Rozenberszki, Or Litany, Angela Dai
3D instance segmentation is fundamental to geometric understanding of the world around us. Existing methods for instance segmentation of 3D scenes rely on supervision from expensive, manual 3D annotations. We propose UnScene3D, the first fully unsupervised 3D learning approach for class-agnostic 3D instance segmentation of indoor scans. UnScene3D first generates pseudo masks by leveraging self-supervised color and geometry features to find potential object regions. We operate on a basis of geometric oversegmentation, enabling efficient representation and learning on high-resolution 3D data. The coarse proposals are then refined through self-training our model on its predictions. Our approach improves over state-of-the-art unsupervised 3D instance segmentation methods by more than 300% Average Precision score, demonstrating effective instance segmentation even in challenging, cluttered 3D scenes.
Read more5/1/2024
🤷
0
FreePoint: Unsupervised Point Cloud Instance Segmentation
Zhikai Zhang, Jian Ding, Li Jiang, Dengxin Dai, Gui-Song Xia
Instance segmentation of point clouds is a crucial task in 3D field with numerous applications that involve localizing and segmenting objects in a scene. However, achieving satisfactory results requires a large number of manual annotations, which is a time-consuming and expensive process. To alleviate dependency on annotations, we propose a novel framework, FreePoint, for underexplored unsupervised class-agnostic instance segmentation on point clouds. In detail, we represent the point features by combining coordinates, colors, and self-supervised deep features. Based on the point features, we perform a bottom-up multicut algorithm to segment point clouds into coarse instance masks as pseudo labels, which are used to train a point cloud instance segmentation model. We propose an id-as-feature strategy at this stage to alleviate the randomness of the multicut algorithm and improve the pseudo labels' quality. During training, we propose a weakly-supervised two-step training strategy and corresponding losses to overcome the inaccuracy of coarse masks. FreePoint has achieved breakthroughs in unsupervised class-agnostic instance segmentation on point clouds and outperformed previous traditional methods by over 18.2% and a competitive concurrent work UnScene3D by 5.5% in AP. Additionally, when used as a pretext task and fine-tuned on S3DIS, FreePoint performs significantly better than existing self-supervised pre-training methods with limited annotations and surpasses CSC by 6.0% in AP with 10% annotation masks.
Read more6/18/2024