Universal dimensions of visual representation

0

Sign in to get full access
Overview
- Explains the universal dimensions of visual representation
- Identifies core principles underlying visual perception and cognition
- Uses neural network models to study representational alignment across different tasks and datasets
Plain English Explanation
The paper explores the fundamental dimensions that shape how our visual system processes and represents information. By studying how deep neural networks learn to represent visual data, the researchers uncovered some key principles that seem to underlie human visual perception and cognition.
The researchers found that as neural networks are trained on different visual tasks and datasets, the representations they develop align with a common set of universal dimensions. These dimensions appear to reflect core organizational principles, like the distinction between object shape and texture, that are preserved across a wide range of visual processing.
In other words, regardless of the specific task or dataset, neural networks tend to latch onto the same fundamental building blocks when learning to represent visual information. This suggests that these universal dimensions may correspond to how the human visual system itself is structured and operates.
Technical Explanation
The paper uses deep neural network models as a tool to investigate the fundamental principles that shape visual representation. The researchers trained neural networks on a diverse set of visual tasks and datasets, ranging from object recognition to scene understanding.
They then analyzed the internal representations developed by these models, and found that they aligned with a common set of universal dimensions. These dimensions reflected key organizational principles, like the distinction between shape and texture information, that were preserved across tasks and datasets.
Further analysis revealed that these universal dimensions were not just an artifact of the neural network architecture, but instead seemed to reflect core organizational principles of the visual system. The researchers showed that the alignment of representations along these dimensions correlated with measures of human visual similarity judgments.
Overall, the findings suggest that the representations learned by neural networks may provide a window into the fundamental dimensions that structure visual processing in the human brain. The work has important implications for understanding the computational principles underlying visual cognition.
Critical Analysis
The paper presents a compelling line of evidence for the existence of universal dimensions underlying visual representation. The use of neural networks as a model system allows the researchers to probe the representational principles in a principled and quantifiable way.
However, the study is limited to analyzing representations in artificial neural networks, rather than directly measuring human visual processing. While the correlations with human similarity judgments are suggestive, more direct comparisons to neurophysiological or behavioral data would strengthen the claims about the relevance of these dimensions to human vision.
Additionally, the specific dimensions identified, such as the shape-texture distinction, align with longstanding theories in visual perception. While the neural network approach provides further validation of these ideas, it does not necessarily reveal fundamentally new principles.
Further research could explore whether these universal dimensions generalize to other modalities beyond vision, or whether there are additional core principles that emerge when considering a broader range of visual processing tasks and datasets.
Conclusion
This paper makes an important contribution by using deep neural networks to uncover universal dimensions that seem to underlie visual representation. The findings suggest that, at a computational level, the visual system may be organized around a core set of organizational principles that are preserved across a wide range of visual processing tasks.
While more work is needed to fully validate the relevance of these dimensions to human visual cognition, the study provides valuable insights into the fundamental building blocks of visual perception. Understanding these universal principles could have far-reaching implications for fields ranging from neuroscience to artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Universal dimensions of visual representation
Zirui Chen, Michael F. Bonner
Do neural network models of vision learn brain-aligned representations because they share architectural constraints and task objectives with biological vision or because they learn universal features of natural image processing? We characterized the universality of hundreds of thousands of representational dimensions from visual neural networks with varied construction. We found that networks with varied architectures and task objectives learn to represent natural images using a shared set of latent dimensions, despite appearing highly distinct at a surface level. Next, by comparing these networks with human brain representations measured with fMRI, we found that the most brain-aligned representations in neural networks are those that are universal and independent of a network's specific characteristics. Remarkably, each network can be reduced to fewer than ten of its most universal dimensions with little impact on its representational similarity to the human brain. These results suggest that the underlying similarities between artificial and biological vision are primarily governed by a core set of universal image representations that are convergently learned by diverse systems.
Read more8/26/2024
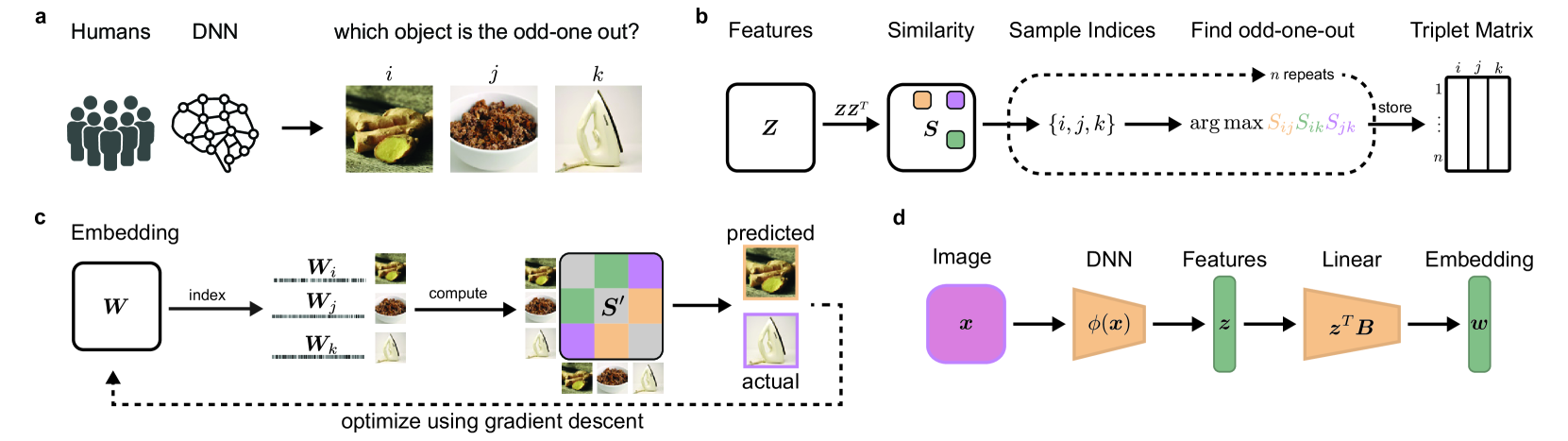
0
Dimensions underlying the representational alignment of deep neural networks with humans
Florian P. Mahner, Lukas Muttenthaler, Umut Guc{c}lu, Martin N. Hebart
Determining the similarities and differences between humans and artificial intelligence is an important goal both in machine learning and cognitive neuroscience. However, similarities in representations only inform us about the degree of alignment, not the factors that determine it. Drawing upon recent developments in cognitive science, we propose a generic framework for yielding comparable representations in humans and deep neural networks (DNN). Applying this framework to humans and a DNN model of natural images revealed a low-dimensional DNN embedding of both visual and semantic dimensions. In contrast to humans, DNNs exhibited a clear dominance of visual over semantic features, indicating divergent strategies for representing images. While in-silico experiments showed seemingly-consistent interpretability of DNN dimensions, a direct comparison between human and DNN representations revealed substantial differences in how they process images. By making representations directly comparable, our results reveal important challenges for representational alignment, offering a means for improving their comparability.
Read more6/28/2024
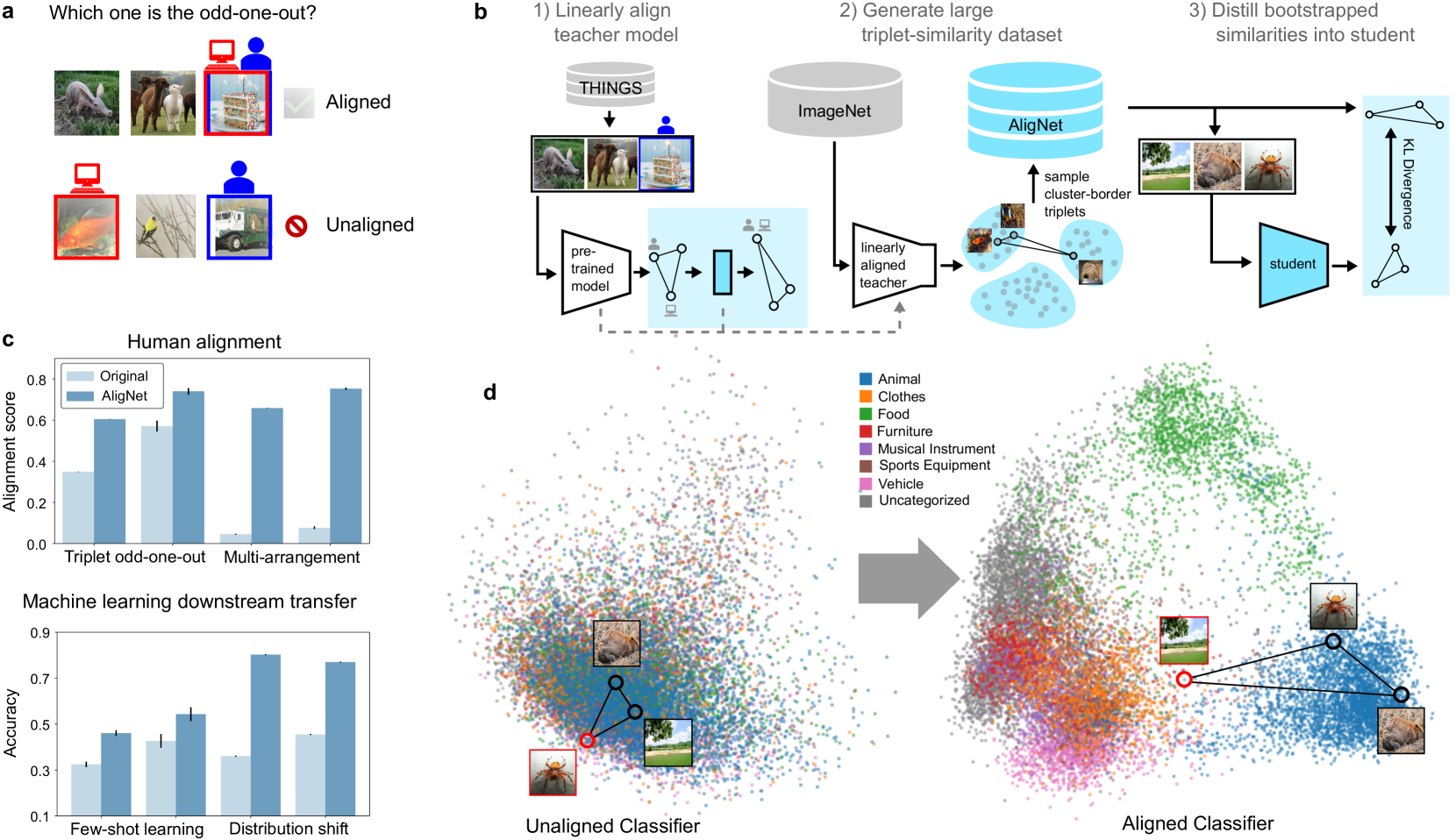
0
Aligning Machine and Human Visual Representations across Abstraction Levels
Lukas Muttenthaler, Klaus Greff, Frieda Born, Bernhard Spitzer, Simon Kornblith, Michael C. Mozer, Klaus-Robert Muller, Thomas Unterthiner, Andrew K. Lampinen
Deep neural networks have achieved success across a wide range of applications, including as models of human behavior in vision tasks. However, neural network training and human learning differ in fundamental ways, and neural networks often fail to generalize as robustly as humans do, raising questions regarding the similarity of their underlying representations. What is missing for modern learning systems to exhibit more human-like behavior? We highlight a key misalignment between vision models and humans: whereas human conceptual knowledge is hierarchically organized from fine- to coarse-scale distinctions, model representations do not accurately capture all these levels of abstraction. To address this misalignment, we first train a teacher model to imitate human judgments, then transfer human-like structure from its representations into pretrained state-of-the-art vision foundation models. These human-aligned models more accurately approximate human behavior and uncertainty across a wide range of similarity tasks, including a new dataset of human judgments spanning multiple levels of semantic abstractions. They also perform better on a diverse set of machine learning tasks, increasing generalization and out-of-distribution robustness. Thus, infusing neural networks with additional human knowledge yields a best-of-both-worlds representation that is both more consistent with human cognition and more practically useful, thus paving the way toward more robust, interpretable, and human-like artificial intelligence systems.
Read more9/17/2024

0
AlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space
Huzheng Yang, James Gee, Jianbo Shi
We study the intriguing connection between visual data, deep networks, and the brain. Our method creates a universal channel alignment by using brain voxel fMRI response prediction as the training objective. We discover that deep networks, trained with different objectives, share common feature channels across various models. These channels can be clustered into recurring sets, corresponding to distinct brain regions, indicating the formation of visual concepts. Tracing the clusters of channel responses onto the images, we see semantically meaningful object segments emerge, even without any supervised decoder. Furthermore, the universal feature alignment and the clustering of channels produce a picture and quantification of how visual information is processed through the different network layers, which produces precise comparisons between the networks.
Read more6/27/2024