AlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space

0

Sign in to get full access
Overview
- The paper "AlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space" explores a novel approach to discovering visual concepts using brain-guided universal feature spaces.
- The key contributions include the development of the AlignedCut method for discovering visual concepts, leveraging brain-guided feature spaces to enhance the interpretability and generalizability of the discovered concepts, and the use of a brain-guided universal feature encoder to capture transferable visual knowledge.
Plain English Explanation
The researchers behind this paper have developed a new way to uncover the building blocks of visual perception, known as "visual concepts." These visual concepts are the fundamental units that make up how we understand and interpret the world around us through our sense of sight.
The researchers used brain activity data, obtained from people observing various images, as a guide to discover these visual concepts. By aligning the brain's responses to visual stimuli with the features extracted by machine learning models, the researchers were able to identify a "universal" set of visual features that seem to be consistently represented in the brain across different people and tasks.
This builds on previous work that has shown the brain uses a common "vocabulary" to process visual information, regardless of the specific task or individual. The researchers in this paper leverage this insight to develop a method called "AlignedCut" that can automatically discover these meaningful visual concepts from the universal feature space.
The key advantage of this approach is that the discovered visual concepts are inherently more interpretable and generalizable, as they are grounded in our biological understanding of how the brain processes visual information. This could lead to more explainable and trustworthy computer vision systems that better align with human perception.
Technical Explanation
The core of the paper is the development of the AlignedCut method, which combines several key innovations:
-
Brain-Guided Universal Feature Encoder: The researchers train a neural network to learn a universal feature representation of images that aligns with brain activity patterns observed across different people and visual tasks. This builds on previous work showing the existence of a "common visual vocabulary" in the brain.
-
Visual Concept Discovery via AlignedCut: The AlignedCut algorithm is used to discover meaningful visual concepts from the brain-guided universal feature space. It does this by identifying compact clusters of features that are both visually coherent and strongly aligned with distinct patterns of brain activity.
-
Interpretable and Generalizable Visual Concepts: By grounding the discovered visual concepts in brain activity data, the researchers show that these concepts are more interpretable and generalizable compared to concepts discovered using standard unsupervised learning techniques. This addresses limitations of previous work on discovering visual concepts.
The paper demonstrates the effectiveness of this approach through extensive experiments, including qualitative analysis of the discovered visual concepts and quantitative evaluation on various computer vision benchmarks. The results indicate that the brain-guided visual concepts learned by AlignedCut can enhance the performance and interpretability of downstream vision tasks.
Critical Analysis
One key strength of this work is the tight integration between the machine learning models and our biological understanding of visual perception. By using brain activity data as a guide, the researchers are able to discover visual concepts that are more closely aligned with how the human brain processes visual information.
However, a potential limitation is the reliance on functional magnetic resonance imaging (fMRI) data, which has relatively low spatial and temporal resolution compared to other neuroscientific techniques. It's possible that using higher-resolution data, such as electroencephalography (EEG) or single-neuron recordings, could lead to even more precise and informative visual concepts.
Additionally, while the researchers demonstrate the generalizability of the discovered visual concepts, it would be interesting to see how well the approach scales to a broader range of visual stimuli and tasks beyond the ones examined in the paper. Exploring the transferability of these visual concepts to different domains could further validate the utility of the brain-guided approach.
Conclusion
Overall, the "AlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space" paper presents a novel and promising approach to discovering visual concepts that are grounded in our biological understanding of visual perception. By leveraging brain activity data, the researchers have developed a method that can uncover interpretable and generalizable visual building blocks, which could lead to more explainable and trustworthy computer vision systems. While there are some potential limitations, this work represents an important step towards bridging the gap between artificial and biological visual processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space
Huzheng Yang, James Gee, Jianbo Shi
We study the intriguing connection between visual data, deep networks, and the brain. Our method creates a universal channel alignment by using brain voxel fMRI response prediction as the training objective. We discover that deep networks, trained with different objectives, share common feature channels across various models. These channels can be clustered into recurring sets, corresponding to distinct brain regions, indicating the formation of visual concepts. Tracing the clusters of channel responses onto the images, we see semantically meaningful object segments emerge, even without any supervised decoder. Furthermore, the universal feature alignment and the clustering of channels produce a picture and quantification of how visual information is processed through the different network layers, which produces precise comparisons between the networks.
Read more6/27/2024

0
Universal dimensions of visual representation
Zirui Chen, Michael F. Bonner
Do neural network models of vision learn brain-aligned representations because they share architectural constraints and task objectives with biological vision or because they learn universal features of natural image processing? We characterized the universality of hundreds of thousands of representational dimensions from visual neural networks with varied construction. We found that networks with varied architectures and task objectives learn to represent natural images using a shared set of latent dimensions, despite appearing highly distinct at a surface level. Next, by comparing these networks with human brain representations measured with fMRI, we found that the most brain-aligned representations in neural networks are those that are universal and independent of a network's specific characteristics. Remarkably, each network can be reduced to fewer than ten of its most universal dimensions with little impact on its representational similarity to the human brain. These results suggest that the underlying similarities between artificial and biological vision are primarily governed by a core set of universal image representations that are convergently learned by diverse systems.
Read more8/26/2024

0
Parallel Backpropagation for Shared-Feature Visualization
Alexander Lappe, Anna Bogn'ar, Ghazaleh Ghamkhari Nejad, Albert Mukovskiy, Lucas Martini, Martin A. Giese, Rufin Vogels
High-level visual brain regions contain subareas in which neurons appear to respond more strongly to examples of a particular semantic category, like faces or bodies, rather than objects. However, recent work has shown that while this finding holds on average, some out-of-category stimuli also activate neurons in these regions. This may be due to visual features common among the preferred class also being present in other images. Here, we propose a deep-learning-based approach for visualizing these features. For each neuron, we identify relevant visual features driving its selectivity by modelling responses to images based on latent activations of a deep neural network. Given an out-of-category image which strongly activates the neuron, our method first identifies a reference image from the preferred category yielding a similar feature activation pattern. We then backpropagate latent activations of both images to the pixel level, while enhancing the identified shared dimensions and attenuating non-shared features. The procedure highlights image regions containing shared features driving responses of the model neuron. We apply the algorithm to novel recordings from body-selective regions in macaque IT cortex in order to understand why some images of objects excite these neurons. Visualizations reveal object parts which resemble parts of a macaque body, shedding light on neural preference of these objects.
Read more5/17/2024
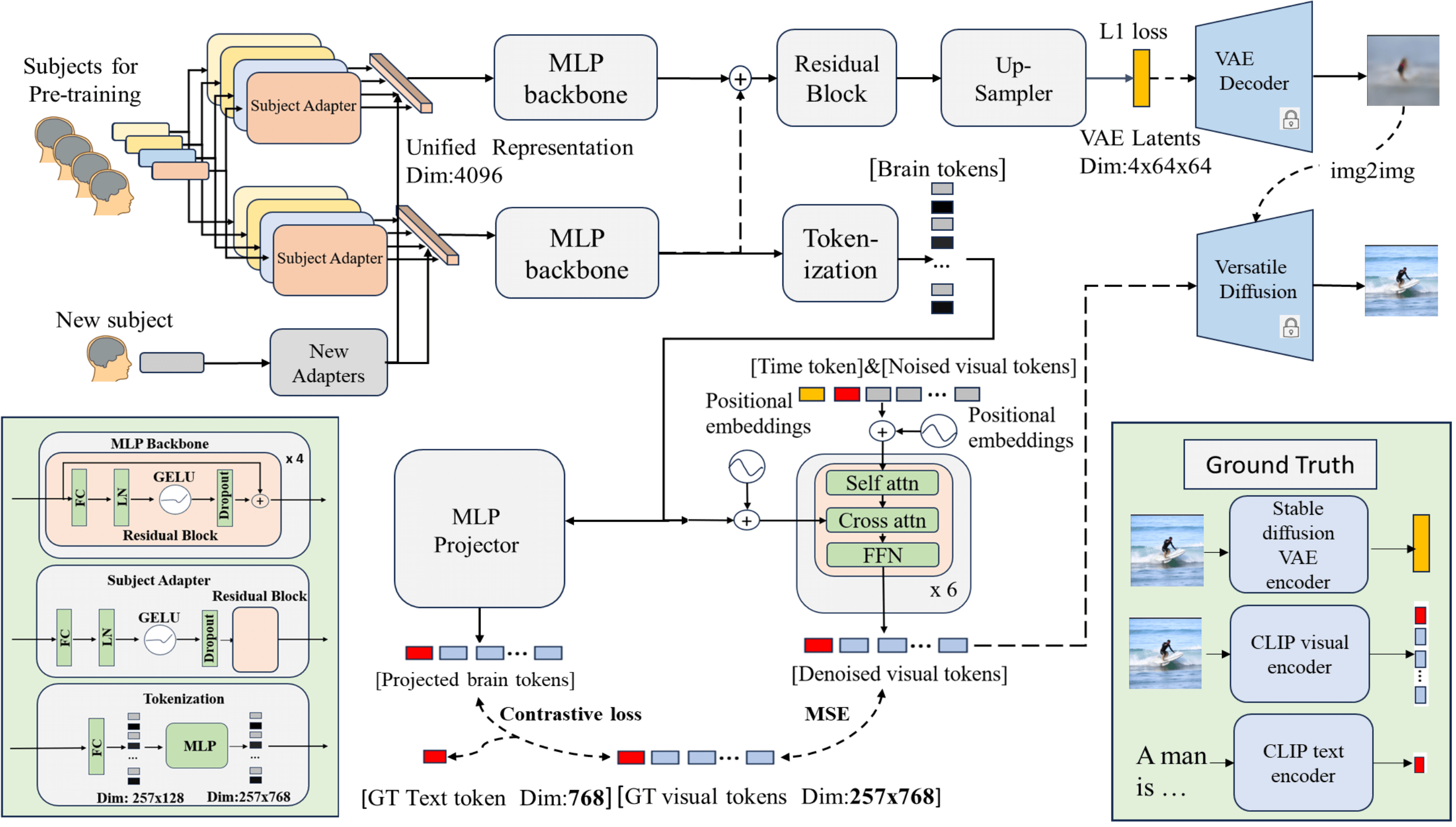
0
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
Read more6/14/2024