Universal End-to-End Neural Network for Lossy Image Compression

0
Sign in to get full access
Overview
- Proposes a universal end-to-end neural network for lossy image compression
- Aims to achieve high-quality image reconstruction at low bitrates
- Introduces a novel architecture and training methodology
Plain English Explanation
The research paper presents a new neural network for compressing images in a way that reduces file size while still preserving image quality. The key idea is to create a "universal" network that can handle a wide variety of images, rather than having separate networks for different types of images.
The neural network works by first encoding the image into a compact representation, and then decoding that representation back into the original image. The encoding process reduces the amount of information needed to store the image, while the decoding process reconstructs the image from the compressed data.
The researchers developed a novel architecture and training methodology to make this end-to-end neural network work well for a wide range of images, rather than just specialized domains. The goal is to create a more versatile and efficient image compression system that can be widely adopted.
Technical Explanation
The paper proposes a universal end-to-end neural network for lossy image compression. The key elements of the approach include:
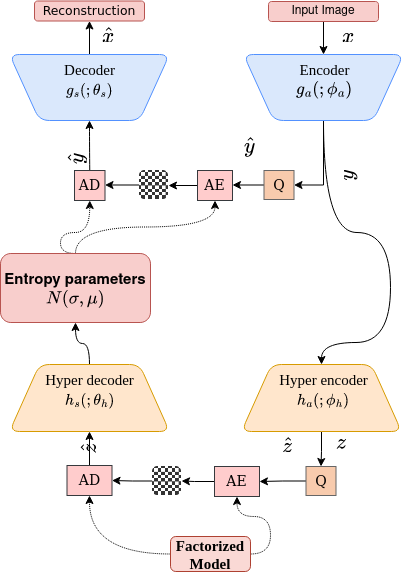
- Architecture: The network consists of an encoder that compresses the input image into a compact latent representation, and a decoder that reconstructs the image from the latent representation. The network is designed to be general-purpose, without specialized components for different image types.
- Training: The network is trained using a combination of reconstruction loss, rate loss, and perceptual loss. The reconstruction loss ensures the decoded image matches the original, the rate loss encourages compression, and the perceptual loss captures human-perceived image quality.
- Universality: The training process encourages the network to learn a universal representation that works well across a wide range of natural images, rather than specializing for particular domains.
The experiments demonstrate that this universal end-to-end approach can achieve state-of-the-art performance on standard image compression benchmarks, outperforming specialized codecs like JPEG and HEIC at low bitrates.
Critical Analysis
The paper makes a compelling case for a universal end-to-end neural network approach to image compression. Some key strengths and limitations:
Strengths:
- Versatility: The universal nature of the network allows it to handle a wide variety of natural images, rather than requiring specialized models.
- Performance: The results show the network can outperform traditional codecs, especially at low bitrates where image quality is most critical.
- Potential for Improvement: The authors note several ways the network could be further optimized, such as incorporating more advanced perceptual loss functions.
Limitations:
- Computational Complexity: Deploying such a large neural network for image compression may require significant computational resources, limiting its practical applicability on resource-constrained devices.
- Generalization Concerns: While the network is designed to be universal, it's unclear how well it would generalize to niche image domains not represented in the training data.
- Lack of Interpretability: As with many deep learning models, the inner workings of the network are not easily interpretable, which can make it difficult to diagnose failure cases or further improve the approach.
Overall, the research represents an innovative step forward in image compression technology, but there remain opportunities to refine the approach and address practical deployment challenges.
Conclusion
This paper presents a novel universal end-to-end neural network for lossy image compression that can outperform traditional codecs, especially at low bitrates where image quality is most critical. By taking a general-purpose approach to the network architecture and training process, the researchers have developed a versatile compression system that has the potential to be widely adopted.
While the computational complexity and interpretability of the model remain areas for further research, the promising results demonstrate the value of this end-to-end neural network approach to image compression. As deep learning continues to advance, we can expect to see more innovative solutions that challenge traditional compression algorithms and unlock new possibilities for efficient and high-quality visual data transmission.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Universal End-to-End Neural Network for Lossy Image Compression
Bouzid Arezki, Fangchen Feng, Anissa Mokraoui
This paper presents variable bitrate lossy image compression using a VAE-based neural network. An adaptable image quality adjustment strategy is proposed. The key innovation involves adeptly adjusting the input scale exclusively during the inference process, resulting in an exceptionally efficient rate-distortion mechanism. Through extensive experimentation, across diverse VAE-based compression architectures (CNN, ViT) and training methodologies (MSE, SSIM), our approach exhibits remarkable universality. This success is attributed to the inherent generalization capacity of neural networks. Unlike methods that adjust model architecture or loss functions, our approach emphasizes simplicity, reducing computational complexity and memory requirements. The experiments not only highlight the effectiveness of our approach but also indicate its potential to drive advancements in variable-rate neural network lossy image compression methodologies.
Read more9/11/2024

0
Convolutional variational autoencoders for secure lossy image compression in remote sensing
Alessandro Giuliano, S. Andrew Gadsden, Waleed Hilal, John Yawney
The volume of remote sensing data is experiencing rapid growth, primarily due to the plethora of space and air platforms equipped with an array of sensors. Due to limited hardware and battery constraints the data is transmitted back to Earth for processing. The large amounts of data along with security concerns call for new compression and encryption techniques capable of preserving reconstruction quality while minimizing the transmission cost of this data back to Earth. This study investigates image compression based on convolutional variational autoencoders (CVAE), which are capable of substantially reducing the volume of transmitted data while guaranteeing secure lossy image reconstruction. CVAEs have been demonstrated to outperform conventional compression methods such as JPEG2000 by a substantial margin on compression benchmark datasets. The proposed model draws on the strength of the CVAEs capability to abstract data into highly insightful latent spaces, and combining it with the utilization of an entropy bottleneck is capable of finding an optimal balance between compressibility and reconstruction quality. The balance is reached by optimizing over a composite loss function that represents the rate-distortion curve.
Read more4/8/2024

0
High Efficiency Image Compression for Large Visual-Language Models
Binzhe Li, Shurun Wang, Shiqi Wang, Yan Ye
In recent years, large visual language models (LVLMs) have shown impressive performance and promising generalization capability in multi-modal tasks, thus replacing humans as receivers of visual information in various application scenarios. In this paper, we pioneer to propose a variable bitrate image compression framework consisting of a pre-editing module and an end-to-end codec to achieve promising rate-accuracy performance for different LVLMs. In particular, instead of optimizing an adaptive pre-editing network towards a particular task or several representative tasks, we propose a new optimization strategy tailored for LVLMs, which is designed based on the representation and discrimination capability with token-level distortion and rank. The pre-editing module and the variable bitrate end-to-end image codec are jointly trained by the losses based on semantic tokens of the large model, which introduce enhanced generalization capability for various data and tasks. {Experimental results demonstrate that the proposed framework could efficiently achieve much better rate-accuracy performance compared to the state-of-the-art coding standard, Versatile Video Coding.} Meanwhile, experiments with multi-modal tasks have revealed the robustness and generalization capability of the proposed framework.
Read more7/25/2024

0
Variational autoencoder-based neural network model compression
Liang Cheng, Peiyuan Guan, Amir Taherkordi, Lei Liu, Dapeng Lan
Variational Autoencoders (VAEs), as a form of deep generative model, have been widely used in recent years, and shown great great peformance in a number of different domains, including image generation and anomaly detection, etc.. This paper aims to explore neural network model compression method based on VAE. The experiment uses different neural network models for MNIST recognition as compression targets, including Feedforward Neural Network (FNN), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM). These models are the most basic models in deep learning, and other more complex and advanced models are based on them or inherit their features and evolve. In the experiment, the first step is to train the models mentioned above, each trained model will have different accuracy and number of total parameters. And then the variants of parameters for each model are processed as training data in VAEs separately, and the trained VAEs are tested by the true model parameters. The experimental results show that using the latent space as a representation of the model compression can improve the compression rate compared to some traditional methods such as pruning and quantization, meanwhile the accuracy is not greatly affected using the model parameters reconstructed based on the latent space. In the future, a variety of different large-scale deep learning models will be used more widely, so exploring different ways to save time and space on saving or transferring models will become necessary, and the use of VAE in this paper can provide a basis for these further explorations.
Read more8/28/2024