Universal New Physics Latent Space

0

Sign in to get full access
Overview
- Provides a plain English summary of the research paper on "Universal New Physics Latent Space"
- Covers the key elements of the paper, including the experiment design, architecture, and insights
- Discusses the caveats, limitations, and areas for further research mentioned in the paper
- Encourages readers to think critically about the research and form their own opinions
- Summarizes the main takeaways and their potential implications
Plain English Explanation
This research paper explores the idea of a "universal new physics latent space" - a hidden representation that could capture fundamental properties of the universe beyond the current Standard Model of particle physics. The researchers hypothesize that by training machine learning models on a wide range of particle physics data, they can uncover latent features that may point to new, undiscovered physical phenomena.
The core of the paper describes a method for training neural networks to learn this latent space representation. The researchers use a technique called "variational autoencoders" to compress particle physics data into a compact, low-dimensional representation. They then analyze the properties of this latent space to look for signs of new physics, such as unexpected correlations or hidden structures.
<a href="https://aimodels.fyi/papers/arxiv/latent-functional-maps">The researchers suggest that this latent space could serve as a "functional map" of fundamental physics</a>, providing a new way to explore and understand the underlying nature of the universe. By uncovering these hidden patterns, they hope to shed light on the limitations of the Standard Model and potentially discover new physical phenomena.
Technical Explanation
The paper describes a method for learning a "universal new physics latent space" using a variational autoencoder (VAE) architecture. The VAE is trained on a diverse dataset of particle physics events, including both Standard Model processes and hypothetical new physics signals.
The key elements of the approach are:
- Data Preprocessing: The researchers preprocess the particle physics data to extract relevant features, such as particle momenta, energies, and event-level observables.
- Variational Autoencoder: They then train a VAE model to learn a low-dimensional latent representation of the input data. The VAE consists of an encoder network that maps the input data to a latent space, and a decoder network that reconstructs the original data from the latent representation.
- Latent Space Analysis: By analyzing the properties of the learned latent space, such as the distribution of latent variables and the presence of hidden structures, the researchers look for signs of new physics beyond the Standard Model.
The researchers demonstrate the effectiveness of their approach using a simplified model of supersymmetric gluino production as a test case. They show that the latent space learned by their VAE model can capture the distinctive features of this new physics scenario, suggesting that the method has the potential to uncover other, previously unknown physical phenomena.
Critical Analysis
The researchers acknowledge several caveats and limitations to their work. First, the performance of the VAE model is dependent on the quality and diversity of the training data, which may not fully capture the complexity of particle physics processes. <a href="https://aimodels.fyi/papers/arxiv/mapping-multiverse-latent-representations">There are also inherent challenges in interpreting the learned latent representations and relating them to underlying physical concepts</a>.
Additionally, the researchers note that their approach is computationally intensive and may not be scalable to the full complexity of particle physics experiments. <a href="https://aimodels.fyi/papers/arxiv/latent-space-translation-via-inverse-relative-projection">Further research is needed to improve the efficiency and robustness of the latent space learning process</a>.
Overall, the paper presents an intriguing and ambitious approach to uncovering new physics using machine learning techniques. However, the researchers acknowledge that their work is still in the early stages, and significant further research and validation will be required before the "universal new physics latent space" concept can be fully realized and applied to real-world particle physics challenges.
Conclusion
This research paper explores the idea of using machine learning to uncover a "universal new physics latent space" - a hidden representation that could capture fundamental properties of the universe beyond the current Standard Model of particle physics. The researchers demonstrate a method for training variational autoencoders to learn this latent space, and they show how it can be used to detect the signatures of new physics scenarios.
While the researchers acknowledge several limitations and caveats to their approach, the paper presents an intriguing and ambitious vision for using machine learning to drive discoveries in particle physics. <a href="https://aimodels.fyi/papers/arxiv/all-roads-lead-to-rome-exploring-representational">By uncovering hidden patterns and structures in particle physics data, the universal new physics latent space could provide a powerful new tool for exploring the fundamental nature of the universe</a>. As the fields of machine learning and particle physics continue to evolve, this research suggests exciting possibilities for further breakthroughs and discoveries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Universal New Physics Latent Space
Anna Hallin, Gregor Kasieczka, Sabine Kraml, Andr'e Lessa, Louis Moureaux, Tore von Schwartz, David Shih
We develop a machine learning method for mapping data originating from both Standard Model processes and various theories beyond the Standard Model into a unified representation (latent) space while conserving information about the relationship between the underlying theories. We apply our method to three examples of new physics at the LHC of increasing complexity, showing that models can be clustered according to their LHC phenomenology: different models are mapped to distinct regions in latent space, while indistinguishable models are mapped to the same region. This opens interesting new avenues on several fronts, such as model discrimination, selection of representative benchmark scenarios, and identifying gaps in the coverage of model space.
Read more7/31/2024
🤯
0
Latent. Functional Map
Marco Fumero, Marco Pegoraro, Valentino Maiorca, Francesco Locatello, Emanuele Rodol`a
Neural models learn data representations that lie on low-dimensional manifolds, yet modeling the relation between these representational spaces is an ongoing challenge. By integrating spectral geometry principles into neural modeling, we show that this problem can be better addressed in the functional domain, mitigating complexity, while enhancing interpretability and performances on downstream tasks. To this end, we introduce a multi-purpose framework to the representation learning community, which allows to: (i) compare different spaces in an interpretable way and measure their intrinsic similarity; (ii) find correspondences between them, both in unsupervised and weakly supervised settings, and (iii) to effectively transfer representations between distinct spaces. We validate our framework on various applications, ranging from stitching to retrieval tasks, demonstrating that latent functional maps can serve as a swiss-army knife for representation alignment.
Read more6/24/2024
🤖
0
Mapping the Multiverse of Latent Representations
Jeremy Wayland, Corinna Coupette, Bastian Rieck
Echoing recent calls to counter reliability and robustness concerns in machine learning via multiverse analysis, we present PRESTO, a principled framework for mapping the multiverse of machine-learning models that rely on latent representations. Although such models enjoy widespread adoption, the variability in their embeddings remains poorly understood, resulting in unnecessary complexity and untrustworthy representations. Our framework uses persistent homology to characterize the latent spaces arising from different combinations of diverse machine-learning methods, (hyper)parameter configurations, and datasets, allowing us to measure their pairwise (dis)similarity and statistically reason about their distributions. As we demonstrate both theoretically and empirically, our pipeline preserves desirable properties of collections of latent representations, and it can be leveraged to perform sensitivity analysis, detect anomalous embeddings, or efficiently and effectively navigate hyperparameter search spaces.
Read more6/4/2024
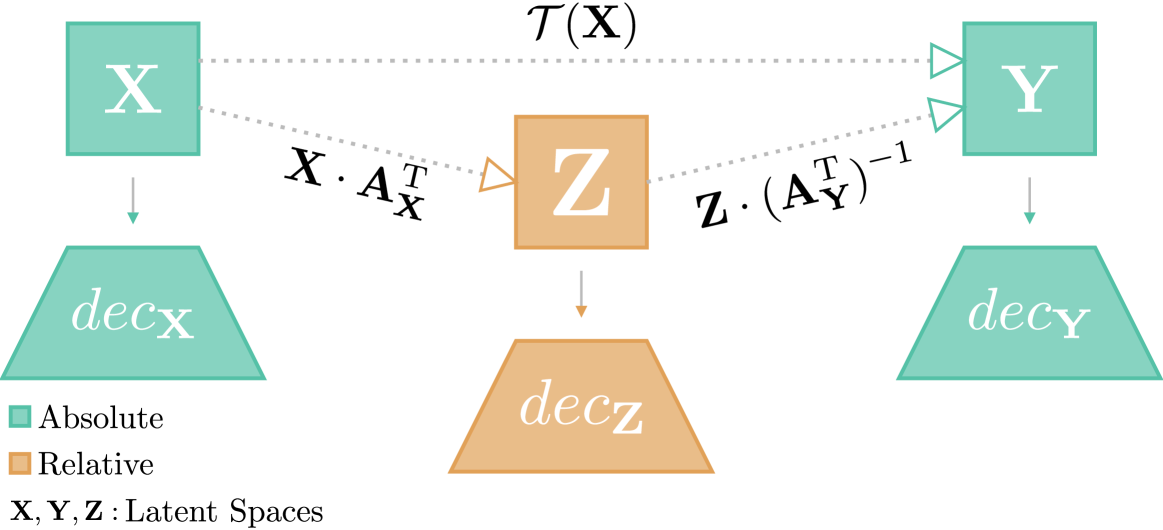
0
Latent Space Translation via Inverse Relative Projection
Valentino Maiorca, Luca Moschella, Marco Fumero, Francesco Locatello, Emanuele Rodol`a
The emergence of similar representations between independently trained neural models has sparked significant interest in the representation learning community, leading to the development of various methods to obtain communication between latent spaces. Latent space communication can be achieved in two ways: i) by independently mapping the original spaces to a shared or relative one; ii) by directly estimating a transformation from a source latent space to a target one. In this work, we combine the two into a novel method to obtain latent space translation through the relative space. By formalizing the invertibility of angle-preserving relative representations and assuming the scale invariance of decoder modules in neural models, we can effectively use the relative space as an intermediary, independently projecting onto and from other semantically similar spaces. Extensive experiments over various architectures and datasets validate our scale invariance assumption and demonstrate the high accuracy of our method in latent space translation. We also apply our method to zero-shot stitching between arbitrary pre-trained text and image encoders and their classifiers, even across modalities. Our method has significant potential for facilitating the reuse of models in a practical manner via compositionality.
Read more6/24/2024