Universal Physics Transformers: A Framework For Efficiently Scaling Neural Operators

0
🧠
Sign in to get full access
Overview
- Neural operators have emerged as promising physics surrogate models, but scaling them to larger and more complex simulations remains a challenge.
- Existing neural operators often follow problem-specific designs, with GNNs used for Lagrangian simulations and grid-based models for Eulerian simulations.
- The paper introduces Universal Physics Transformers (UPTs), a unified learning paradigm for a wide range of spatio-temporal problems.
Plain English Explanation
Neural operators are a type of machine learning model that can be used to simulate physical systems, like fluid flow or particle dynamics. They're called "surrogate models" because they can stand in for more complex and computationally-intensive simulations.
As the problems that these neural operators are applied to become more complex, the natural question is: how can we scale them up to handle larger and more sophisticated simulations? This is a tricky challenge because different applications often use different techniques, even when the underlying physics is similar.
For example, graph neural networks (GNNs) are commonly used for Lagrangian simulations (which track individual particles), while grid-based models are more common for Eulerian simulations (which model the continuous flow of a fluid). This can make it difficult to develop a unified approach that works well across diverse applications.
The paper introduces a new model called Universal Physics Transformers (UPTs), which aims to provide a flexible and scalable solution. UPTs don't rely on grid- or particle-based representations, allowing them to work seamlessly across different types of simulations. Instead, they efficiently propagate dynamics in a latent (hidden) space, using techniques like inverse encoding and decoding.
This latent space representation also allows UPTs to query the simulation at any point in space and time, rather than being limited to the original grid or particle locations. The paper demonstrates the versatility of UPTs by applying them to mesh-based fluid simulations, steady-state Reynolds-averaged Navier-Stokes simulations, and Lagrangian-based dynamics.
Technical Explanation
The key innovation of Universal Physics Transformers (UPTs) is their ability to operate without relying on grid- or particle-based latent structures. This enables them to be more flexible and scalable across a wide range of spatio-temporal problems, from mesh-based fluid simulations to Lagrangian-based dynamics.
UPTs efficiently propagate dynamics in the latent space, leveraging inverse encoding and decoding techniques. This allows them to query the latent space representation at any point in space-time, rather than being constrained to the original grid or particle locations.
The paper demonstrates the versatility of UPTs by applying them to three diverse simulation domains:
- Mesh-based fluid simulations
- Steady-state Reynolds-averaged Navier-Stokes simulations
- Lagrangian-based dynamics
Unlike many existing neural operators that follow problem-specific designs, UPTs provide a unified learning paradigm that can handle a wide range of spatio-temporal problems, even when the underlying dynamics of the systems are similar.
This flexibility and scalability of UPTs is particularly important as the complexity of physical simulations continues to grow, and the need for efficient and accurate surrogate models increases.
Critical Analysis
The paper presents a promising approach with Universal Physics Transformers (UPTs), but it's important to consider some potential caveats and areas for further research.
One potential limitation is the reliance on inverse encoding and decoding techniques to propagate dynamics in the latent space. While this approach allows for flexible querying of the simulation, it may introduce additional complexity and potential sources of error compared to more traditional grid- or particle-based methods.
Additionally, the paper demonstrates the effectiveness of UPTs across three diverse simulation domains, but it's unclear how well the approach would scale to even larger and more complex problems. Further research may be needed to assess the limits of UPTs' scalability and generalization capabilities.
It's also worth considering the computational efficiency of UPTs compared to other neural operator approaches or traditional numerical simulations, as this is a crucial factor for real-world applications. The paper provides some insights, but a more thorough analysis of the computational trade-offs may be warranted.
Overall, the Universal Physics Transformers represent an exciting step forward in the development of flexible and scalable physics surrogate models. However, as with any new approach, it's important to continue critical evaluation and exploration of its limitations and potential areas for improvement.
Conclusion
The introduction of Universal Physics Transformers (UPTs) represents a significant advancement in the field of neural operators, which serve as physics surrogate models. By operating without reliance on grid- or particle-based latent structures, UPTs demonstrate a remarkable degree of flexibility and scalability across a wide range of spatio-temporal problems, from fluid dynamics to Lagrangian-based simulations.
The paper's ability to effectively propagate dynamics in the latent space, enabled by inverse encoding and decoding techniques, opens up new possibilities for querying simulation results at any point in space and time. This could have important implications for various applications, from engineering design to scientific research.
While the paper provides a strong proof of concept, further research is needed to fully assess the limits of UPTs' scalability and computational efficiency, as well as to explore potential avenues for improvement. Nonetheless, the Universal Physics Transformers represent an exciting step forward in the ongoing quest to develop more powerful and versatile physics surrogate models, with the potential to significantly accelerate and enhance a wide range of scientific and engineering endeavors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Universal Physics Transformers: A Framework For Efficiently Scaling Neural Operators
Benedikt Alkin, Andreas Furst, Simon Schmid, Lukas Gruber, Markus Holzleitner, Johannes Brandstetter
Neural operators, serving as physics surrogate models, have recently gained increased interest. With ever increasing problem complexity, the natural question arises: what is an efficient way to scale neural operators to larger and more complex simulations - most importantly by taking into account different types of simulation datasets. This is of special interest since, akin to their numerical counterparts, different techniques are used across applications, even if the underlying dynamics of the systems are similar. Whereas the flexibility of transformers has enabled unified architectures across domains, neural operators mostly follow a problem specific design, where GNNs are commonly used for Lagrangian simulations and grid-based models predominate Eulerian simulations. We introduce Universal Physics Transformers (UPTs), an efficient and unified learning paradigm for a wide range of spatio-temporal problems. UPTs operate without grid- or particle-based latent structures, enabling flexibility and scalability across meshes and particles. UPTs efficiently propagate dynamics in the latent space, emphasized by inverse encoding and decoding techniques. Finally, UPTs allow for queries of the latent space representation at any point in space-time. We demonstrate diverse applicability and efficacy of UPTs in mesh-based fluid simulations, and steady-state Reynolds averaged Navier-Stokes simulations, and Lagrangian-based dynamics.
Read more5/1/2024
0
UPS: Efficiently Building Foundation Models for PDE Solving via Cross-Modal Adaptation
Junhong Shen, Tanya Marwah, Ameet Talwalkar
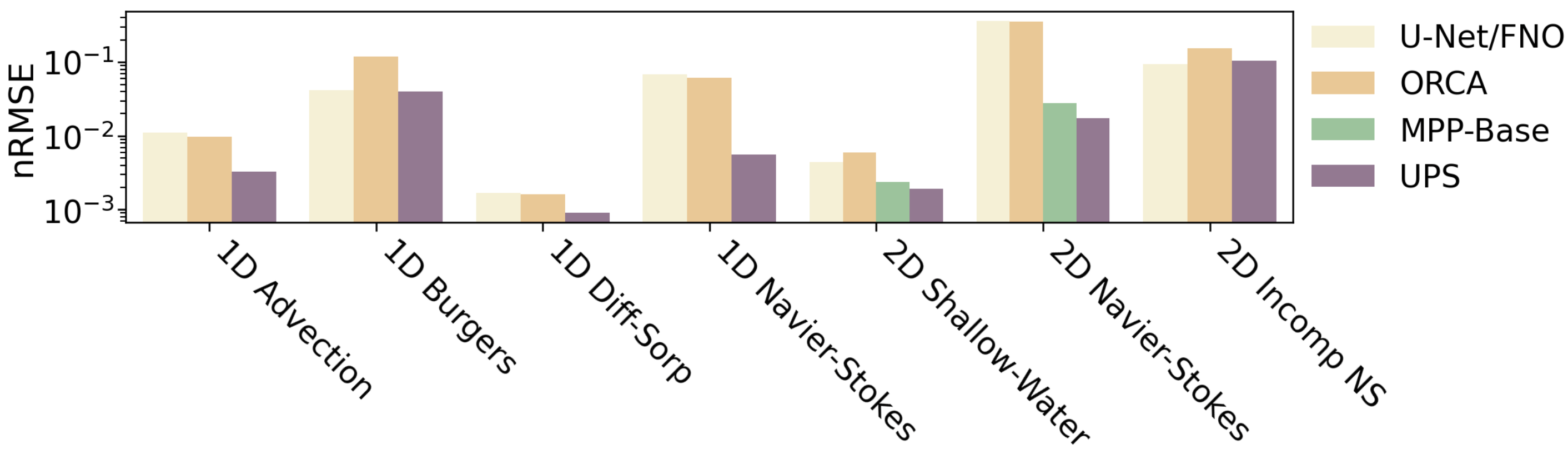
We present Unified PDE Solvers (UPS), a data- and compute-efficient approach to developing unified neural operators for diverse families of spatiotemporal PDEs from various domains, dimensions, and resolutions. UPS embeds different PDEs into a shared representation space and processes them using a FNO-transformer architecture. Rather than training the network from scratch, which is data-demanding and computationally expensive, we warm-start the transformer from pretrained LLMs and perform explicit alignment to reduce the modality gap while improving data and compute efficiency. The cross-modal UPS achieves state-of-the-art results on a wide range of 1D and 2D PDE families from PDEBench, outperforming existing unified models using 4 times less data and 26 times less compute. Meanwhile, it is capable of few-shot transfer to unseen PDE families and coefficients.
Read more8/1/2024
🧠
0
Universal Approximation of Operators with Transformers and Neural Integral Operators
Emanuele Zappala, Maryam Bagherian
We study the universal approximation properties of transformers and neural integral operators for operators in Banach spaces. In particular, we show that the transformer architecture is a universal approximator of integral operators between Holder spaces. Moreover, we show that a generalized version of neural integral operators, based on the Gavurin integral, are universal approximators of arbitrary operators between Banach spaces. Lastly, we show that a modified version of transformer, which uses Leray-Schauder mappings, is a universal approximator of operators between arbitrary Banach spaces.
Read more9/4/2024
👨🏫
0
Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics
Jonas Spinner, Victor Bres'o, Pim de Haan, Tilman Plehn, Jesse Thaler, Johann Brehmer
Extracting scientific understanding from particle-physics experiments requires solving diverse learning problems with high precision and good data efficiency. We propose the Lorentz Geometric Algebra Transformer (L-GATr), a new multi-purpose architecture for high-energy physics. L-GATr represents high-energy data in a geometric algebra over four-dimensional space-time and is equivariant under Lorentz transformations, the symmetry group of relativistic kinematics. At the same time, the architecture is a Transformer, which makes it versatile and scalable to large systems. L-GATr is first demonstrated on regression and classification tasks from particle physics. We then construct the first Lorentz-equivariant generative model: a continuous normalizing flow based on an L-GATr network, trained with Riemannian flow matching. Across our experiments, L-GATr is on par with or outperforms strong domain-specific baselines.
Read more7/10/2024